Dynamic Parameter Allocation in Parameter Servers
To keep up with increasing dataset sizes and model complexity, distributed training has become a necessity for large machine learning tasks. Parameter servers ease the implementation of distributed parameter management—a key concern in distributed training—, but can induce severe communication overhead. To reduce communication overhead, distributed machine learning algorithms use techniques to increase parameter access locality (PAL), achieving up to linear speed-ups. We found that existing parameter servers provide only limited support for PAL techniques, however, and therefore prevent efficient training. In this paper, we explore whether and to what extent PAL techniques can be supported, and whether such support is beneficial. We propose to integrate dynamic parameter allocation into parameter servers, describe an efficient implementation of such a parameter server called Lapse, and experimentally compare its performance to existing parameter servers across a number of machine learning tasks. We found that Lapse provides near-linear scaling and can be orders of magnitude faster than existing parameter servers.
💡 Research Summary
The paper addresses a fundamental bottleneck in distributed machine‑learning systems: the communication overhead caused by parameter servers (PS). While PS abstractions simplify distributed parameter management, most existing implementations allocate parameters statically and provide only limited support for techniques that increase parameter‑access locality (PAL), such as data clustering, parameter blocking, and latency hiding. These PAL techniques can dramatically reduce communication, often achieving near‑linear speed‑ups, but they require fine‑grained control over where parameters reside—a capability that classic PS designs lack.
To bridge this gap, the authors introduce Dynamic Parameter Allocation (DPA), a mechanism that allows parameters to be moved to the node where they are most frequently accessed, while preserving the usual pull/push semantics and sequential consistency guarantees of a PS. Building on DPA, they implement a new parameter‑server system called Lapse. Lapse’s architecture co‑locates a server thread and multiple worker threads within the same process on each node, eliminating costly inter‑process messaging. It also employs a shared‑memory cache for fast local access and provides an API that lets applications explicitly request parameter relocation. Crucially, the relocation protocol ensures that reads and writes remain consistent before, during, and after a move, so existing ML code can use Lapse without major rewrites.
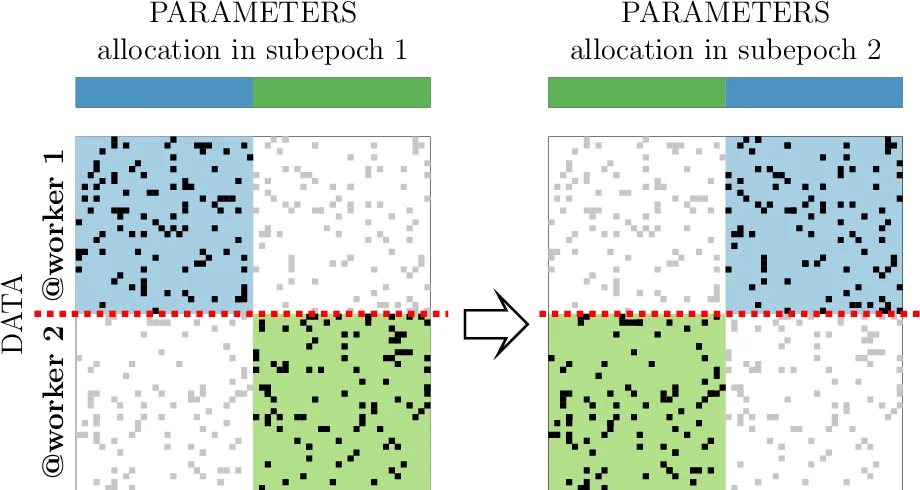
The paper evaluates Lapse on three representative workloads: (1) large‑scale knowledge‑graph embedding (RESCAL, 100‑dimensional), (2) matrix factorization (alternating least squares), and (3) word‑embedding training. For each workload, the authors apply appropriate PAL techniques—data clustering and latency hiding for RESCAL, parameter blocking for matrix factorization, and pre‑localization for word embeddings. In all cases, Lapse outperforms classic PS‑Lite and state‑of‑the‑art stale‑synchronous servers (e.g., Petuum). On the RESCAL task, Lapse scales from 0.6 h on a single 4‑thread node to 0.2 h on an 8‑node, 4‑thread configuration, demonstrating near‑linear scaling. For matrix factorization, dynamic block relocation eliminates inter‑node communication between sub‑epochs, yielding up to a ten‑fold speed‑up. In word‑embedding experiments, pre‑localization reduces latency enough to achieve a five‑fold improvement over PS‑Lite.
The authors’ contributions are fourfold: (i) a systematic analysis showing why existing PS designs hinder PAL techniques, (ii) the proposal of DPA as a general solution, (iii) the design and implementation of Lapse, an efficient DPA‑enabled PS, and (iv) an extensive empirical study confirming that DPA‑enabled servers can achieve near‑linear scalability and orders‑of‑magnitude speed‑ups compared to traditional PS architectures. The work demonstrates that by integrating dynamic parameter allocation directly into the server layer, distributed ML systems can reap the benefits of locality‑enhancing techniques without burdening developers with low‑level communication management, thereby making large‑scale training both faster and more accessible.
Comments & Academic Discussion
Loading comments...
Leave a Comment