An Automated and Robust Image Watermarking Scheme Based on Deep Neural Networks
💡 Research Summary
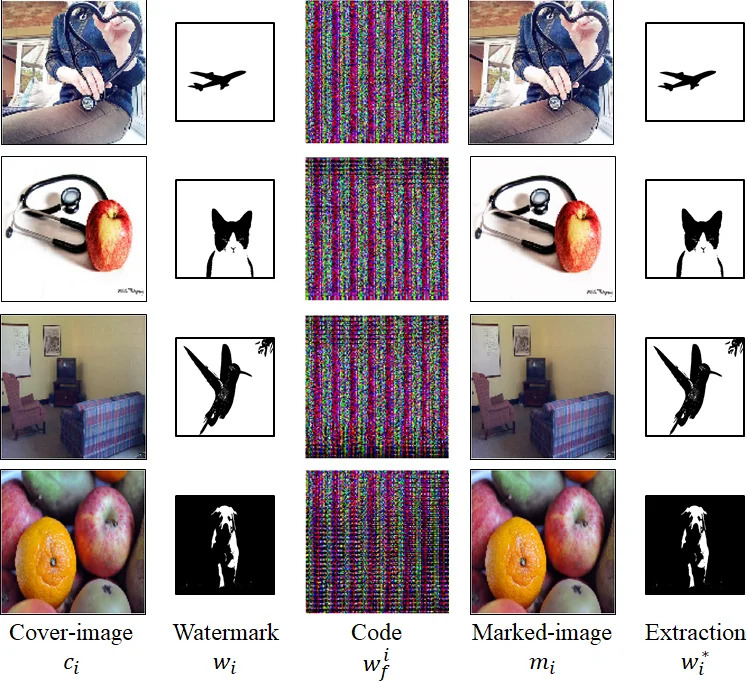
The paper presents a novel deep‑learning‑based image watermarking framework that simultaneously achieves automation, blindness, and robustness without requiring prior knowledge of attacks or adversarial examples. Traditional watermarking pipelines rely on manually designed projection, embedding, and extraction functions, which limits adaptability and robustness, especially under diverse distortions. To overcome these limitations, the authors construct a unified neural architecture composed of five modules: (1) an encoder µθ₁ that transforms a raw watermark w into a high‑dimensional feature representation w_f; (2) an embedder σθ₂ that fuses w_f with a cover image c to generate a marked image m that is visually indistinguishable from c; (3) a variance layer τθ₅ that models channel distortions (compression, geometric transforms, noise, camera capture) and is trained to preserve the embedded information while discarding irrelevant perturbations; (4) an extractor ϕθ₃ that recovers w_f from the distorted representation T; and (5) a decoder γθ₄ that reconstructs the original watermark ŵ from w_f.
Training is performed in an unsupervised manner using paired samples of cover images and watermarks. The loss function L(ϑ) combines three terms: (i) an extraction loss λ₁‖ŵ−w‖₁ that directly penalizes differences between the recovered and original watermark; (ii) a fidelity loss λ₂‖m−c‖₁ that forces the marked image to stay close to the cover image in pixel space, ensuring imperceptibility; and (iii) an information loss λ₃ψ(m,w_f) that maximizes the correlation between feature maps of the marked image and the encoded watermark. The correlation is measured via Gram‑matrix similarity of two intermediate convolutional blocks (B₁, B₂), a technique borrowed from style‑transfer literature. A regularization term λ₄P is added to explicitly encourage robustness in τθ₅, though the exact formulation of P is left abstract. The overall objective is to minimize L(ϑ)+λ₄P with respect to all trainable parameters ϑ =
Comments & Academic Discussion
Loading comments...
Leave a Comment