HPC AI500: The Methodology, Tools, Roofline Performance Models, and Metrics for Benchmarking HPC AI Systems
The recent years witness a trend of applying large-scale distributed deep learning in both business and scientific computing areas, whose goal is to speed up the training time to achieve a state-of-the-art quality. The HPC community feels a great interest in building the HPC AI systems that are dedicated to running those workloads. The HPC AI benchmarks accelerate the process. Unfortunately, benchmarking HPC AI systems at scale raises serious challenges. None of previous HPC AI benchmarks achieve the goal of being equivalent, relevant, representative, affordable, and repeatable. This paper presents a comprehensive methodology, tools, Roofline performance models, and innovative metrics for benchmarking, optimizing, and ranking HPC AI systems, which we call HPC AI500 V2.0. We abstract the HPC AI system into nine independent layers, and present explicit benchmarking rules and procedures to assure equivalence of each layer, repeatability, and replicability. On the basis of AIBench – by far the most comprehensive AI benchmarks suite, we present and build two HPC AI benchmarks from both business and scientific computing: Image Classification, and Extreme Weather Analytics, achieving both representativeness and affordability. To rank the performance and energy-efficiency of HPC AI systems, we propose Valid FLOPS, and Valid FLOPS per watt, which impose a penalty on failing to achieve the target quality. We propose using convolution and GEMM – the two most intensively-used kernel functions to measure the upper bound performance of the HPC AI systems, and present HPC AI roofline models for guiding performance optimizations. The evaluations show our methodology, benchmarks, performance models, and metrics can measure, optimize, and rank the HPC AI systems in a scalable, simple, and affordable way. HPC AI500 V2.0 are publicly available from http://www.benchcouncil.org/benchhub/hpc-ai500-benchmark.
💡 Research Summary
The paper addresses the emerging need for a rigorous, reproducible benchmark suite tailored to high‑performance computing (HPC) systems that run large‑scale distributed deep‑learning workloads. Existing benchmarks such as TOP500, HPL‑AI, and traditional micro‑kernels focus on raw FLOP counts or specific linear‑algebra kernels and therefore fail to capture the unique characteristics of AI training, namely stochastic convergence, quality targets, and the tight coupling between hardware, system software, and algorithmic hyper‑parameters. To fill this gap, the authors propose HPC AI500 V2.0, a comprehensive methodology that simultaneously satisfies four desiderata: equivalence, representativeness, affordability, and repeatability.
The core of the methodology is a nine‑layer abstraction of an HPC AI system. Layers 1‑3 cover hardware (CPU, GPU, network) and low‑level system software; layers 4‑6 encapsulate AI accelerators and libraries (CUDA, cuDNN), AI frameworks (TensorFlow, PyTorch), and programming models (Horovod, MPI). Layer 7 represents the workload (algorithm, data pipeline), layer 8 the problem domain (datasets, target quality, epochs), and layer 9 the user‑level concerns (cost, energy). By fixing all but one layer during a test, the framework isolates the impact of each component, enabling fair cross‑system comparisons. Explicit benchmarking rules define which parameters may be varied (e.g., batch size, learning‑rate schedule, data‑parallelism) and which must remain constant (model architecture, dataset, target accuracy), thereby guaranteeing equivalence across different scales and implementations.
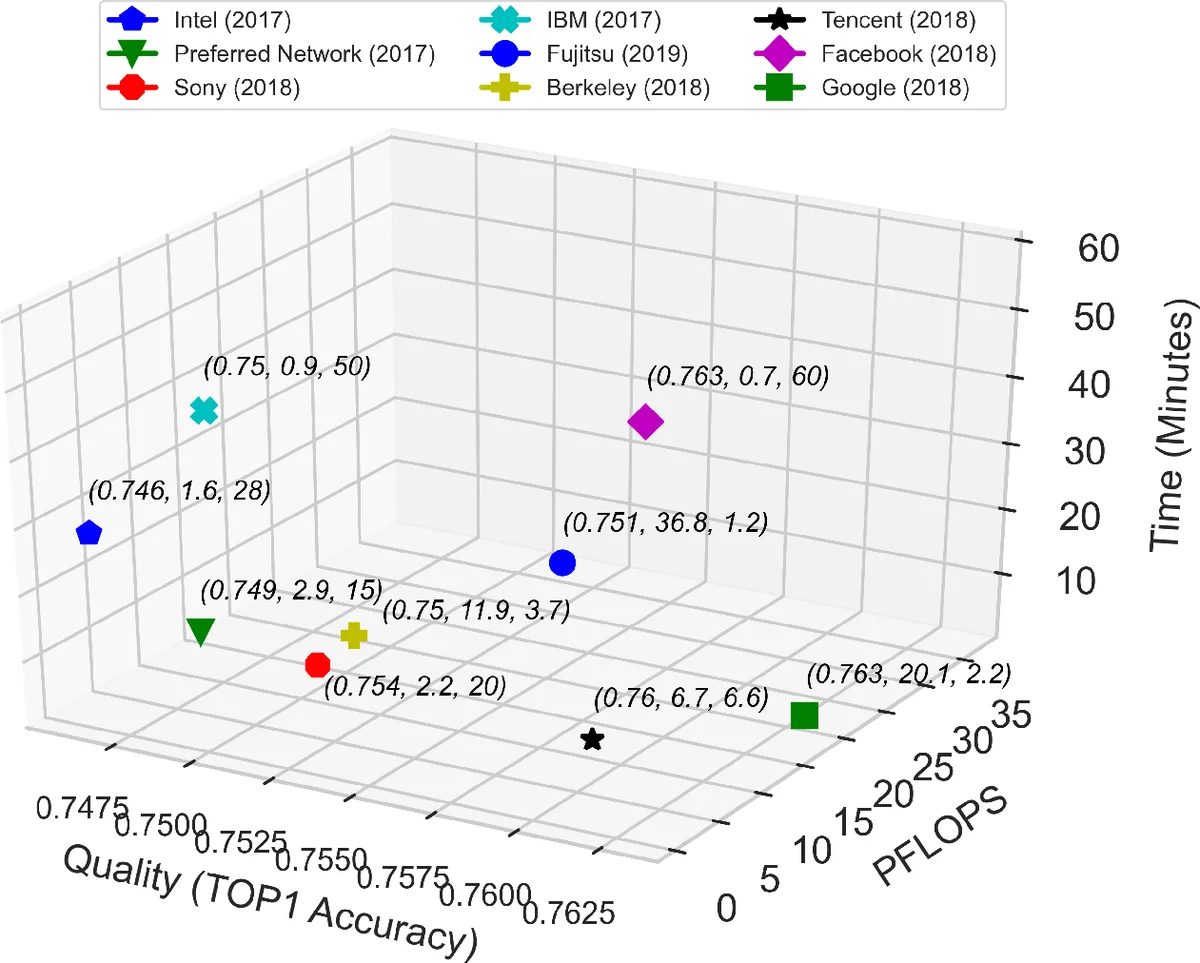
For practical evaluation the authors select two representative benchmarks from the AIBench suite: (1) Image Classification using ResNet‑50 on ImageNet, representing commercial AI workloads, and (2) Extreme Weather Analytics (EWA), a scientific‑computing use case that processes large climate datasets. These two tasks span a wide range of model sizes (0.03 M–68.39 M parameters), per‑inference computational cost (0.09 MFLOP–157.8 GFLOP), and convergence epochs (6–304), providing a balanced yet affordable testbed.
To rank systems the paper introduces “Valid FLOPS” and “Valid FLOPS per Watt”. Unlike raw FLOPS, Valid FLOPS applies a penalty if the system fails to achieve the predefined quality target (e.g., ≥75 % top‑1 accuracy for ResNet‑50). This ties performance measurement directly to the scientific or business value of the result. Valid FLOPS per Watt further incorporates energy consumption, offering a simple metric for energy‑efficiency comparisons. An auxiliary metric, time‑to‑quality, records the wall‑clock time required to reach the target quality, reflecting real‑world user concerns.
The authors argue that convolution and general matrix‑multiply (GEMM) are the dominant kernels across AI workloads (≈90 % of the compute in the 17 AIBench tasks). Consequently, they use these two kernels as micro‑benchmarks to define the theoretical performance ceiling of a system. Building on this, they develop single‑node and distributed‑system Roofline models that plot attainable performance as a function of operational intensity, memory bandwidth, and communication overhead. The models are validated with empirical data, showing that mixed‑precision (FP16) implementations can double kernel FLOPS while potentially degrading model accuracy—a trade‑off that the Roofline model captures quantitatively.
Experimental results demonstrate that HPC AI500 V2.0 meets all four desiderata: it provides equivalent measurements across heterogeneous systems, represents both commercial and scientific AI workloads, is affordable to implement and run at scale, and yields repeatable results despite the stochastic nature of training. All source code, datasets, and benchmark data are publicly released, enabling the community to reproduce and extend the work.
In summary, the paper delivers a well‑structured, extensible benchmark framework that bridges the gap between traditional HPC performance evaluation and the emerging demands of AI‑driven scientific and commercial computing. By coupling quality‑aware performance metrics with a clear nine‑layer abstraction and Roofline‑guided optimization guidance, HPC AI500 V2.0 offers a practical tool for system designers, vendors, and researchers to assess, compare, and improve next‑generation HPC AI platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment