Using Reinforcement Learning to Herd a Robotic Swarm to a Target Distribution
In this paper, we present a reinforcement learning approach to designing a control policy for a “leader” agent that herds a swarm of “follower” agents, via repulsive interactions, as quickly as possible to a target probability distribution over a strongly connected graph. The leader control policy is a function of the swarm distribution, which evolves over time according to a mean-field model in the form of an ordinary difference equation. The dependence of the policy on agent populations at each graph vertex, rather than on individual agent activity, simplifies the observations required by the leader and enables the control strategy to scale with the number of agents. Two Temporal-Difference learning algorithms, SARSA and Q-Learning, are used to generate the leader control policy based on the follower agent distribution and the leader’s location on the graph. A simulation environment corresponding to a grid graph with 4 vertices was used to train and validate the control policies for follower agent populations ranging from 10 to 100. Finally, the control policies trained on 100 simulated agents were used to successfully redistribute a physical swarm of 10 small robots to a target distribution among 4 spatial regions.
💡 Research Summary
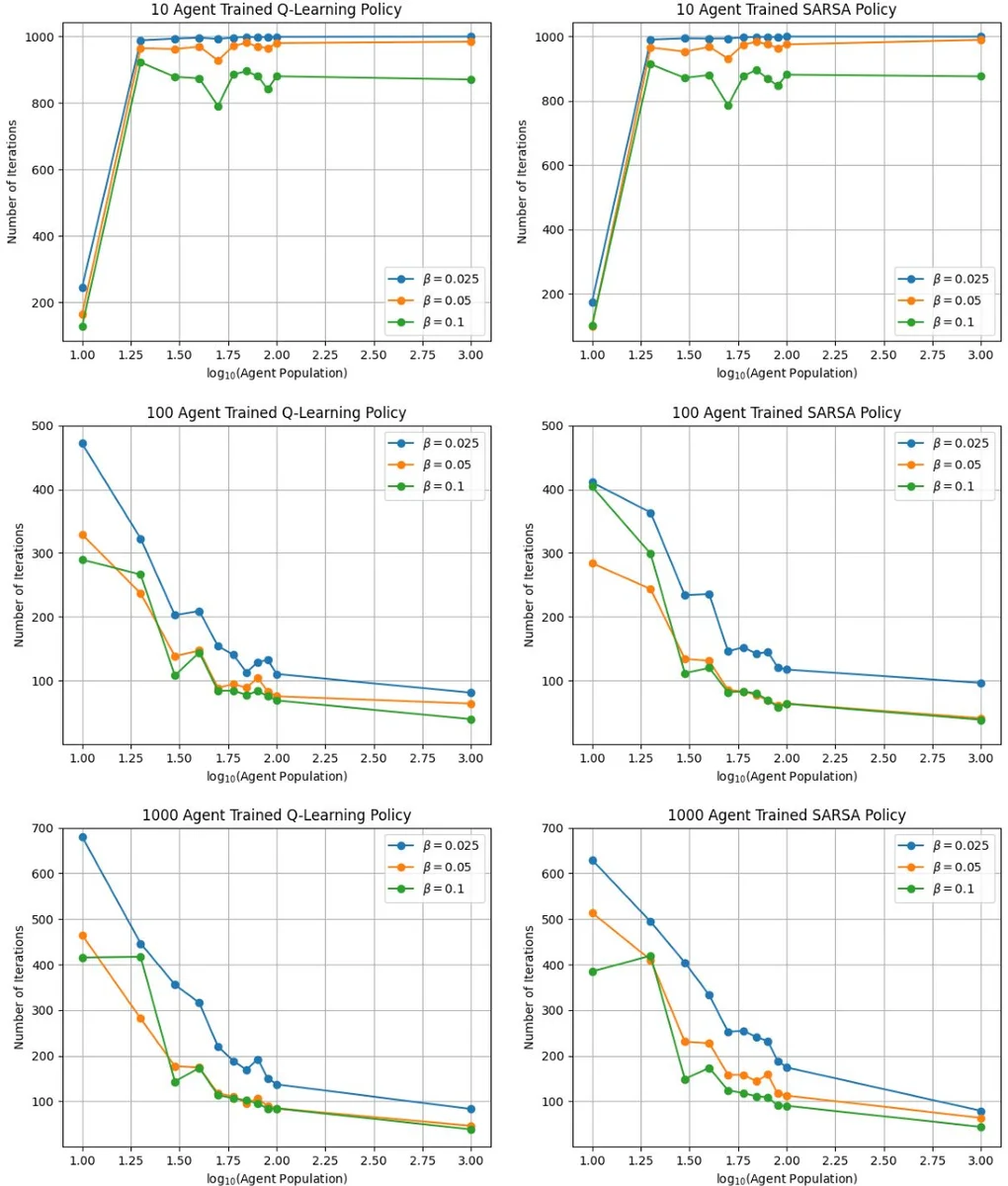
The paper introduces a reinforcement‑learning (RL) framework for steering a swarm of follower robots toward a prescribed probability distribution over a strongly connected graph, using a single “leader” robot that exerts a repulsive influence. The key idea is to treat the swarm’s empirical distribution across graph vertices as the system state rather than the individual positions of each robot. As the number of followers grows, the empirical distribution converges to a deterministic mean‑field variable ˆS(k) that evolves according to a discrete‑time Kolmogorov forward equation (a set of linear difference equations). The leader’s actions consist of moving to an adjacent vertex and optionally switching its behavioral mode (active/inactive). When the leader occupies a vertex and is active, followers at that vertex transition to neighboring vertices with a fixed probability β_e; otherwise they remain.
The control objective is to find a policy π that maps the current mean‑field distribution and the leader’s location to an action, minimizing the time required for the swarm to match a target distribution ˆS_target. The reward at each step is defined as the negative squared Euclidean distance between the current and target distributions, encouraging rapid convergence.
To learn π without an explicit model of follower dynamics, the authors apply two temporal‑difference (TD) RL algorithms: SARSA (on‑policy) and Q‑Learning (off‑policy). Because the mean‑field state is continuous, they discretize each vertex’s population fraction into D intervals (D=10 in experiments) and scale these to integer values F_v. The full state vector S_env =
Comments & Academic Discussion
Loading comments...
Leave a Comment