Preparing Ginkgo for AMD GPUs -- A Testimonial on Porting CUDA Code to HIP
With AMD reinforcing their ambition in the scientific high performance computing ecosystem, we extend the hardware scope of the Ginkgo linear algebra package to feature a HIP backend for AMD GPUs. In this paper, we report and discuss the porting effort from CUDA, the extension of the HIP framework to add missing features such as cooperative groups, the performance price of compiling HIP code for AMD architectures, and the design of a library providing native backends for NVIDIA and AMD GPUs while minimizing code duplication by using a shared code base.
💡 Research Summary
The paper presents a comprehensive case study of extending the open‑source sparse linear‑algebra library Ginkgo to support AMD GPUs through the HIP programming model. The motivation stems from the growing presence of AMD hardware in national labs and the Exascale Computing Project, which makes reliance on NVIDIA‑only CUDA untenable for a high‑performance library that aims to serve a broad scientific community.
The authors first review the CUDA programming model, highlighting its kernel launch syntax, launch‑bounds optimization, and the rich ecosystem of vendor‑provided libraries (cuBLAS, cuSPARSE, cuSOLVER). They then introduce HIP as AMD’s counterpart built on top of the ROCm stack, noting that while HIP mirrors many CUDA concepts (e.g., global functions), it differs in launch syntax (hipLaunchKernelGGL) and lacks several CUDA‑specific features, most notably warp‑level cooperative groups and sub‑warp shuffle/vote intrinsics. The hardware difference—32‑thread warps on NVIDIA versus 64‑thread wavefronts on AMD—also forces careful reconsideration of thread‑block sizing and register usage.
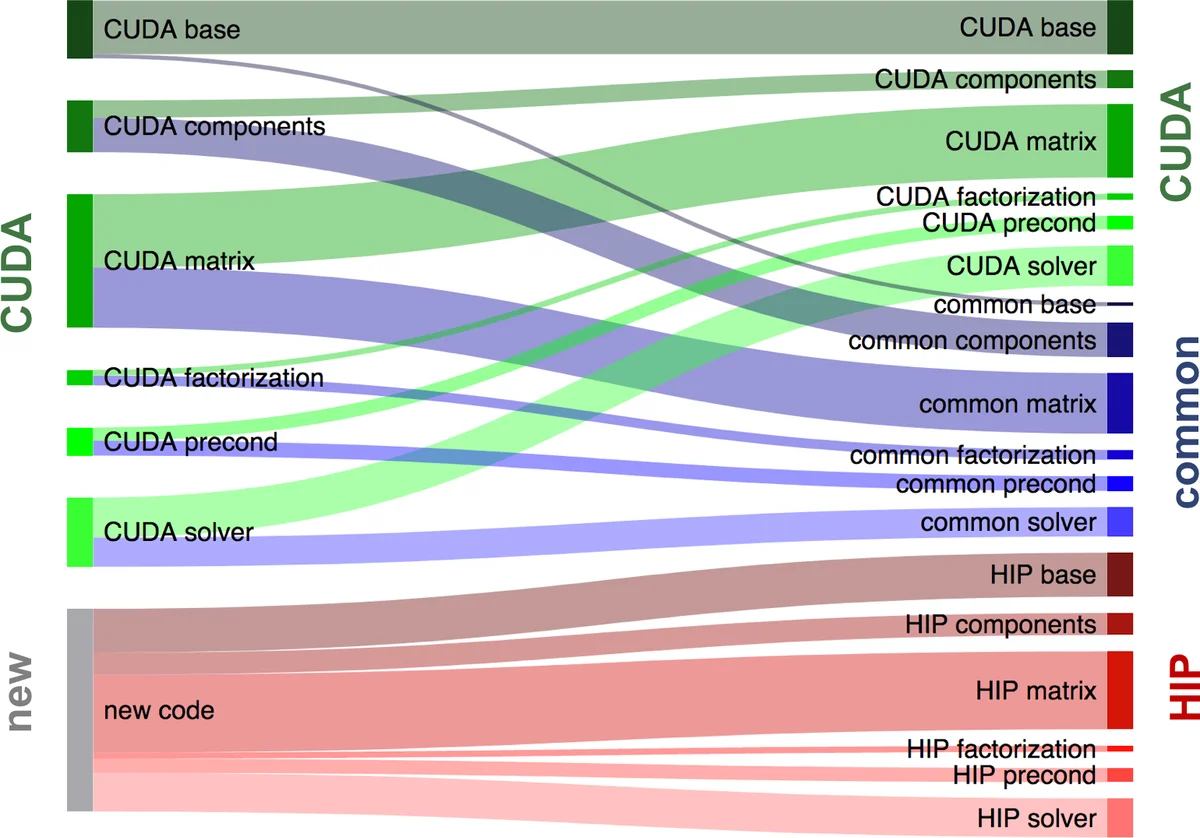
Ginkgo’s architecture is described as a core library that contains algorithmic skeletons and generic data structures, with separate back‑ends for CPU reference, OpenMP, CUDA, and now HIP. To avoid duplicating the same kernel code for each back‑end, the authors create a “common” directory that holds device‑agnostic kernels. Backend‑specific wrappers in the “cuda” and “hip” folders only set configuration parameters such as warp size, launch bounds, and shared‑memory allocation. This design enables a single source of truth for the computational logic while still allowing fine‑grained tuning for each GPU architecture.
A major technical contribution is the implementation of cooperative‑group functionality missing from HIP. The authors design a sub‑warp abstraction that computes size, rank, lane offset, and mask based on the hardware’s wavefront size. Using these values they re‑implement shuffle (shfl_xor), ballot, any, and all operations with bit‑mask manipulation and popcnt intrinsics that exist in both CUDA and HIP. The implementation deliberately uses contiguous thread IDs so that the block index can identify the sub‑warp, ensuring deterministic behavior across architectures. For operations that HIP does provide (e.g., block and grid groups), the code falls back to the native API, preserving compatibility with future HIP releases.
Performance evaluation focuses on a reduction kernel that performs a series of intra‑warp reductions. The kernel is executed 100 times (after a warm‑up) on an NVIDIA V100 and an AMD Radeon VII, with inner‑loop counts of 1 000 and 2 000 to amortize launch overhead. Two versions are compared: one using the vendor’s native intrinsics (legacy) and one using Ginkgo’s cross‑platform cooperative‑group wrapper (green). The results show that the wrapper version matches or slightly exceeds the native version on both GPUs, demonstrating that the sub‑warp implementation incurs negligible overhead. On the AMD device the HIP‑compiled code is within 5–10 % of the CUDA‑compiled code, a difference attributed mainly to compiler optimizations and memory‑bandwidth variations rather than algorithmic inefficiency.
The authors conclude that Ginkgo is, to the best of their knowledge, the first open‑source sparse linear‑algebra library offering the same rich set of matrix formats (COO, CSR, SELL‑P, ELL, Hybrid), solvers (CG, BiCG, GMRES, etc.), preconditioners (block‑Jacobi), and factorization methods (ParILU, ParILUT) on both NVIDIA and AMD GPUs. Their “common”‑plus‑backend‑specific configuration strategy provides a practical template for other HPC libraries seeking multi‑vendor GPU support without exploding code maintenance effort. Moreover, by extending HIP with missing cooperative‑group primitives, they demonstrate how the community can fill gaps in the AMD ecosystem, accelerating the adoption of AMD GPUs in scientific computing. The paper therefore serves both as a technical guide for CUDA‑to‑HIP porting and as evidence that performance parity is achievable when careful abstraction and hardware‑aware tuning are applied.
Comments & Academic Discussion
Loading comments...
Leave a Comment