Locally Masked Convolution for Autoregressive Models
High-dimensional generative models have many applications including image compression, multimedia generation, anomaly detection and data completion. State-of-the-art estimators for natural images are autoregressive, decomposing the joint distribution over pixels into a product of conditionals parameterized by a deep neural network, e.g. a convolutional neural network such as the PixelCNN. However, PixelCNNs only model a single decomposition of the joint, and only a single generation order is efficient. For tasks such as image completion, these models are unable to use much of the observed context. To generate data in arbitrary orders, we introduce LMConv: a simple modification to the standard 2D convolution that allows arbitrary masks to be applied to the weights at each location in the image. Using LMConv, we learn an ensemble of distribution estimators that share parameters but differ in generation order, achieving improved performance on whole-image density estimation (2.89 bpd on unconditional CIFAR10), as well as globally coherent image completions. Our code is available at https://ajayjain.github.io/lmconv.
💡 Research Summary
**
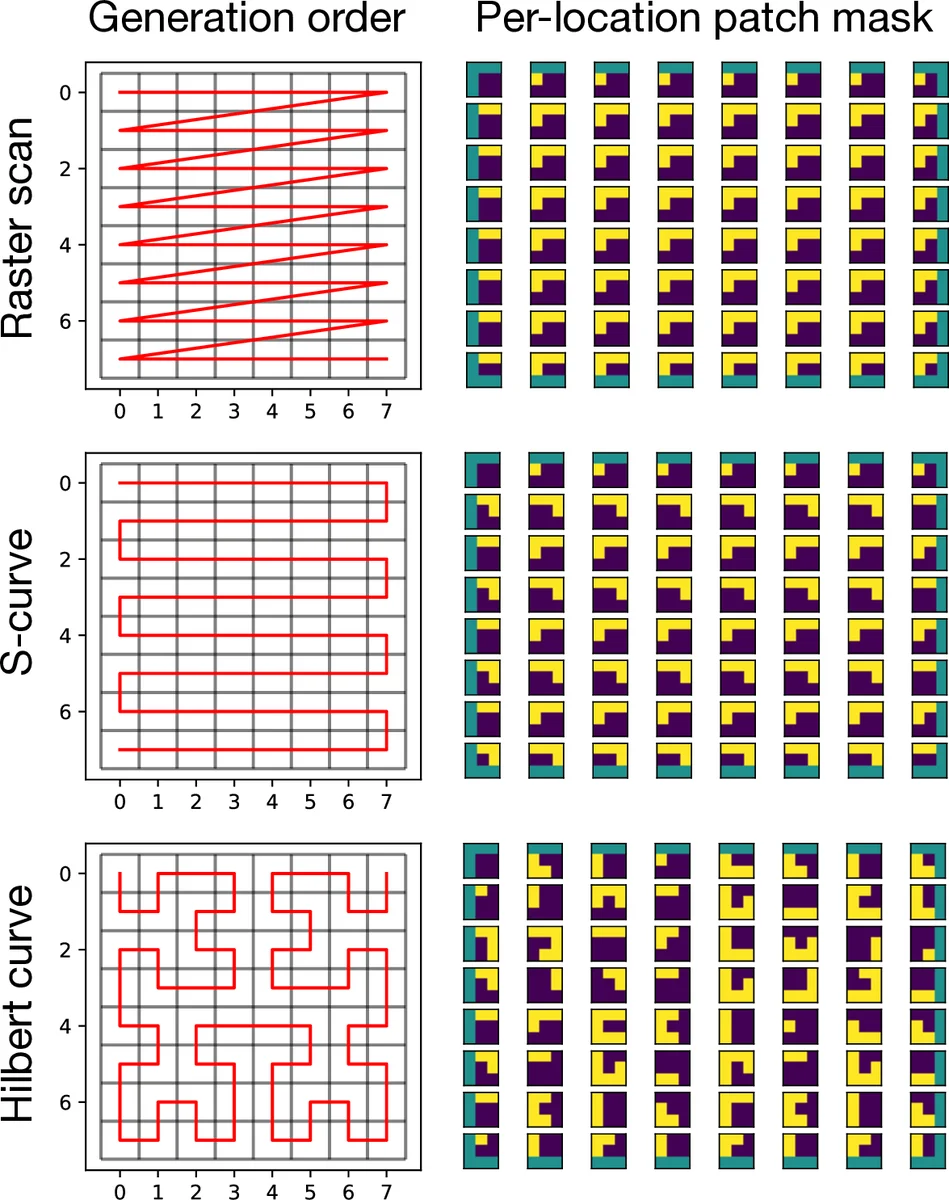
The paper addresses a fundamental limitation of modern autoregressive image models such as PixelCNN and PixelCNN++. These models typically adopt a single, fixed generation order—most commonly a raster‑scan that proceeds left‑to‑right and top‑to‑bottom. While this ordering is computationally convenient, it severely restricts the amount of observed context that can be leveraged during tasks like image completion or in‑painting, where the missing region may be located anywhere in the image. In such cases the raster‑scan order often leaves large “blind spots” because the conditional distribution for a pixel is allowed to depend only on previously generated pixels in the raster order, ignoring any observed pixels that appear later in that order.
To overcome this, the authors propose Locally Masked Convolution (LMConv), a simple yet powerful modification to the standard 2‑D convolution operation. Instead of applying a single binary mask to the convolutional weights (as in masked convolutions used by PixelCNN), LMConv applies a location‑specific mask to the input patches extracted by the im2col operation. For a given generation order π, a mask matrix M is constructed so that, for each spatial location, the patch fed to the convolution contains only those pixels that are predecessors of the target pixel under π. The masked patches are then multiplied by the weight matrix in the usual GEMM step, yielding the conditional logits for all pixels in parallel.
Key technical contributions include:
- Order‑dependent mask construction – The mask is derived from the chosen permutation π and can be generated on‑the‑fly for each training batch.
- Single‑parameter sharing across orders – All orders share the same filter weights and biases; only the mask changes, enabling efficient multi‑order training without a proportional increase in model size.
- Efficient implementation – By leveraging the existing im2col/col2im pipeline, LMConv incurs minimal overhead. Two implementations are provided: a straightforward autograd‑based version (≈20 lines of Python) and a custom backward pass that recomputes im2col during back‑propagation, achieving a 2.7× memory reduction at a modest 1.3× speed penalty.
- Support for multiple generation orders – The paper experiments with three families of orders: the classic raster scan, an S‑curve (alternating row direction), and a Hilbert space‑filling curve. The latter two reduce blind spots and keep spatially adjacent pixels close in the generation sequence.
Training proceeds by sampling a single order per mini‑batch (order‑agnostic training). The objective is the expected log‑likelihood over a uniform distribution of orders, effectively performing Bayesian model averaging across the set of order‑specific factorisations. At test time, for a given set of observed pixels, the model selects an order whose initial prefix matches the observed locations, thereby conditioning each unknown pixel on the maximal possible context.
Empirical results demonstrate that LMConv improves both unconditional density estimation and conditional image completion. On CIFAR‑10, an LMConv‑based ensemble achieves 2.89 bits per dimension, surpassing the previous state‑of‑the‑art PixelCNN++ (≈2.92 bpd). For image in‑painting, using the order that maximizes observed context yields completions that respect global structure far better than raster‑scan baselines. Moreover, the model exhibits reasonable generalisation to unseen orders, indicating that the learned representations are not tightly coupled to any single permutation.
The significance of this work lies in its demonstration that local masking of input patches can replace weight masking while preserving parallelism and enabling multi‑order autoregressive modeling. This opens the door to more flexible generative pipelines where the generation order can be adapted to the task (e.g., completing arbitrary masks, progressive rendering, or multi‑view synthesis) without retraining separate models. Limitations include the additional memory cost of duplicated patches in im2col and the need to construct masks per batch, which may become non‑trivial for very high‑resolution images. Future directions could explore hierarchical masking schemes, integration with self‑attention mechanisms, or hardware‑aware optimisations to further reduce overhead.
Comments & Academic Discussion
Loading comments...
Leave a Comment