Automating System Test Case Classification and Prioritization for Use Case-Driven Testing in Product Lines
Product Line Engineering (PLE) is a crucial practice in many software development environments where software systems are complex and developed for multiple customers with varying needs. At the same time, many development processes are use case-driven and this strongly influences their requirements engineering and system testing practices. In this paper, we propose, apply, and assess an automated system test case classification and prioritization approach specifically targeting system testing in the context of use case-driven development of product families. Our approach provides: (i) automated support to classify, for a new product in a product family, relevant and valid system test cases associated with previous products, and (ii) automated prioritization of system test cases using multiple risk factors such as fault-proneness of requirements and requirements volatility in a product family. Our evaluation was performed in the context of an industrial product family in the automotive domain. Results provide empirical evidence that we propose a practical and beneficial way to classify and prioritize system test cases for industrial product lines.
💡 Research Summary
The paper addresses the challenge of reusing system test cases in product‑line engineering (PLE) environments that are driven by use‑case specifications. In many automotive and embedded‑system contexts, each new product variant is created by extending or modifying existing use‑case models, and test engineers manually select, classify, and prioritize regression test cases. This manual process is error‑prone, time‑consuming, and often lacks a systematic way to assess risk.
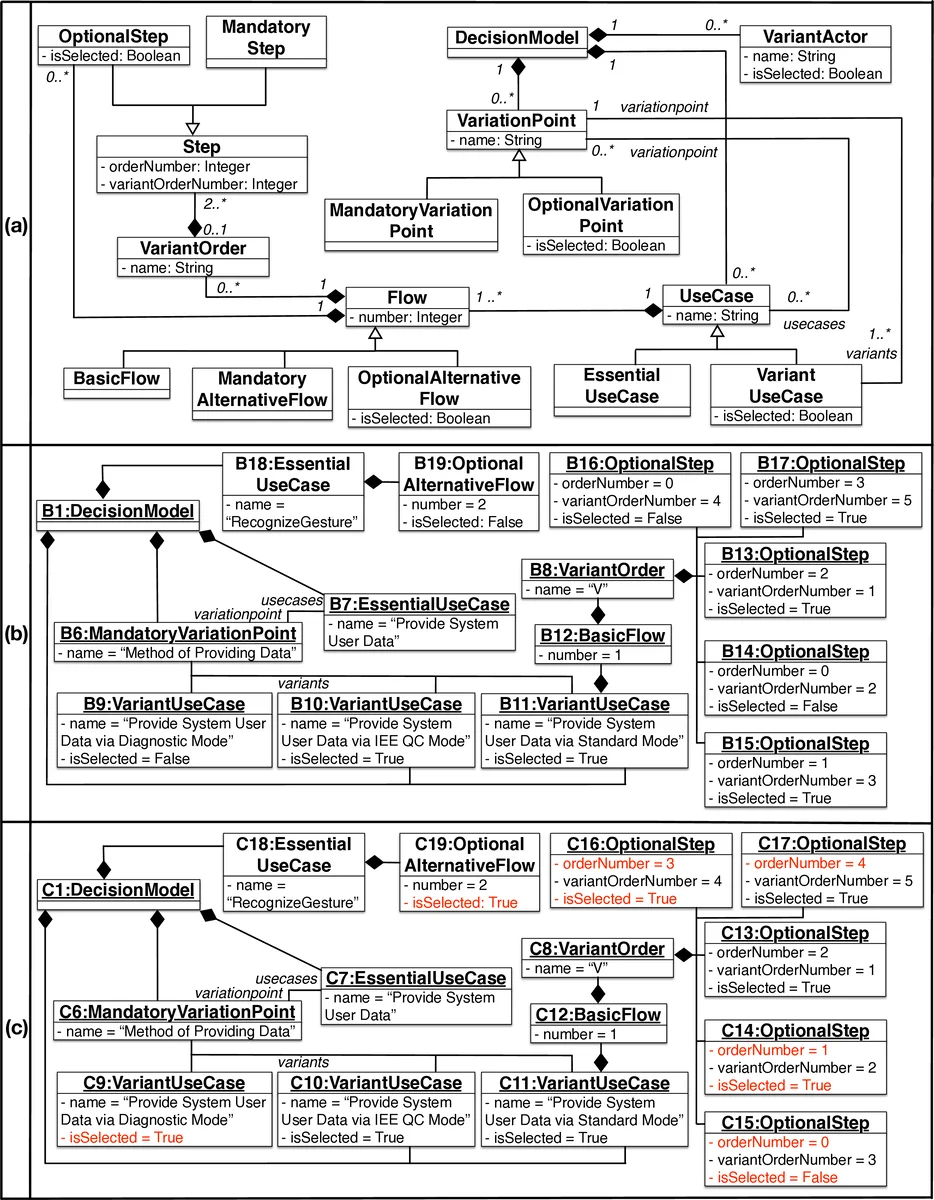
To overcome these limitations, the authors build on their earlier work on the Product line Use case Modeling method (PUM) and the supporting tool PUMConf, which is integrated with IBM DOORS. Their approach consists of two main components. First, a model‑differencing pipeline automatically compares the configuration decisions that generated the product‑specific (PS) use‑case specifications for a previous product and for a newly configured product. By detecting added, deleted, and updated variant decisions, the pipeline identifies the parts of the use‑case models that have changed. Using traceability links between use‑cases and system test cases—either manually maintained or automatically derived—the approach classifies existing test cases into three categories: obsolete (cannot be run on the new product), retestable (still valid but must be rerun), and reusable (valid and need not be rerun).
Second, the approach prioritizes the selected test cases using multiple risk factors. The authors focus on fault‑proneness of requirements and requirements volatility across the product line. They train logistic‑regression models on historical product‑line data to predict the likelihood that a given test case will fail when the associated requirements change. Test cases are then ordered by predicted failure probability, ensuring that the most risky tests are executed first, thereby maximizing fault detection while minimizing test effort.
The solution was evaluated on an industrial automotive product line, the Smart Trunk Opener (STO), comprising five successive products. Four research questions guided the study: (RQ1) the correctness of test‑case classification, (RQ2) the ability to identify new, untested scenarios, (RQ3) the effectiveness of the prioritization, and (RQ4) the potential cost reduction compared with current practice. Empirical results showed high precision and recall for both classification (≈0.92 precision, 0.88 recall) and new‑scenario identification (≈0.85 precision, 0.81 recall). The prioritization model increased fault detection rates by more than 15 % and reduced the overall effort for defining and executing system tests by roughly 30 % relative to the manual, ad‑hoc process used at the company.
A notable contribution is that the approach does not rely on detailed behavioral models (e.g., state machines or sequence diagrams) or source‑code coverage data, which are often unavailable in outsourced or embedded‑system testing contexts. Instead, it leverages the artifacts that are already present in many industrial settings: natural‑language use‑case specifications and traceability links. Limitations include the need for an initial set of high‑quality trace links and sufficient historical data to train reliable prediction models. Future work is suggested on automating trace link generation, incorporating additional risk dimensions (such as test execution cost or time), and validating the method in other domains beyond automotive.
Comments & Academic Discussion
Loading comments...
Leave a Comment