Stochastic Optimization for Performative Prediction
💡 Research Summary
This paper, “Stochastic Optimization for Performative Prediction,” presents the first systematic analysis of stochastic optimization methods in settings where the deployment of a predictive model influences the data distribution it will encounter in the future—a phenomenon termed performative prediction. The core challenge is that in an online stochastic setting, the learner must balance between updating the model based on incoming data and deploying it, as each deployment triggers a distribution shift that can either aid or hinder convergence to a desirable equilibrium.
The authors formalize the goal as finding a performatively stable point—a model that minimizes the expected loss on the very distribution it induces. They analyze two natural stochastic gradient descent (SGD) variants tailored for this setting:
- Greedy Deploy: After observing a single data sample drawn from the current model’s induced distribution, the model parameters are updated via a stochastic gradient step, and the new model is immediately deployed. This process repeats every round.
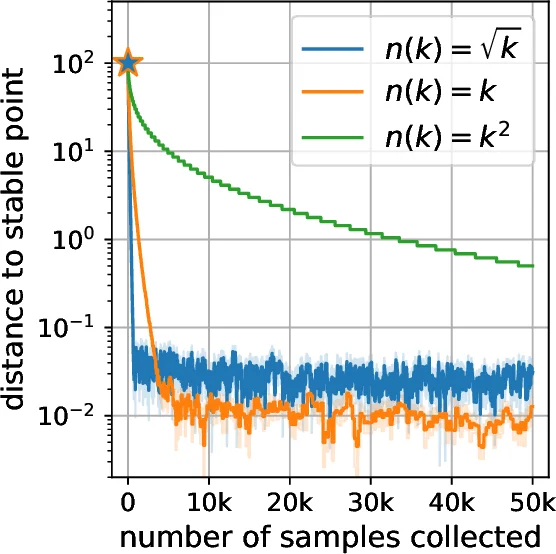
- Lazy Deploy: The algorithm collects multiple stochastic gradient steps (using multiple data samples) from a fixed distribution before deploying an updated model. This reduces the frequency of costly deployments at the expense of more samples.
Under standard assumptions of smoothness and strong convexity for the loss function, and a Lipschitz condition (ε-sensitivity) on the distribution map, the paper establishes non-asymptotic convergence guarantees for both methods. A key condition for convergence is ε < γ/β, where γ is the strong convexity parameter and β is the smoothness parameter. This threshold is shown to be sharp.
The main theoretical results are:
- Theorem 3.2 (Greedy Deploy): The greedy deploy algorithm converges to a performatively stable point at a rate of O(1/k), where k is the number of deployment steps. This rate smoothly recovers the optimal SGD rate as the performative effects vanish (ε → 0).
- Theorem 3.3 (Lazy Deploy): For any α > 0, the lazy deploy algorithm can achieve a convergence rate of O(1/k^α) in terms of deployment steps, provided it collects O(k^{1.1α}) samples between deployments. This offers a trade-off, allowing for very few deployments if sample collection is cheap.
Furthermore, the analysis and supporting experiments on synthetic data and a strategic classification simulator reveal a crucial practical insight: the relative performance of the two algorithms depends on the strength of performative effects (ε). Greedy deploy tends to perform better when ε is small (weak performativity), while lazy deploy is more effective when ε is larger (strong performativity), as it mitigates the destabilizing impact of frequent distribution shifts.
In summary, this work bridges the gap between the population-level analysis of performative prediction and practical online learning scenarios. It provides the first stochastic optimization guarantees in this domain, characterizes the convergence regime, and offers guidance on algorithm selection based on the problem’s characteristics—specifically, the cost of deployment and the sensitivity of the data distribution to the model.
Comments & Academic Discussion
Loading comments...
Leave a Comment