Benanza: Automatic $mu$Benchmark Generation to Compute "Lower-bound" Latency and Inform Optimizations of Deep Learning Models on GPUs
As Deep Learning (DL) models have been increasingly used in latency-sensitive applications, there has been a growing interest in improving their response time. An important venue for such improvement is to profile the execution of these models and ch…
Authors: Cheng Li, Abdul Dakkak, Jinjun Xiong
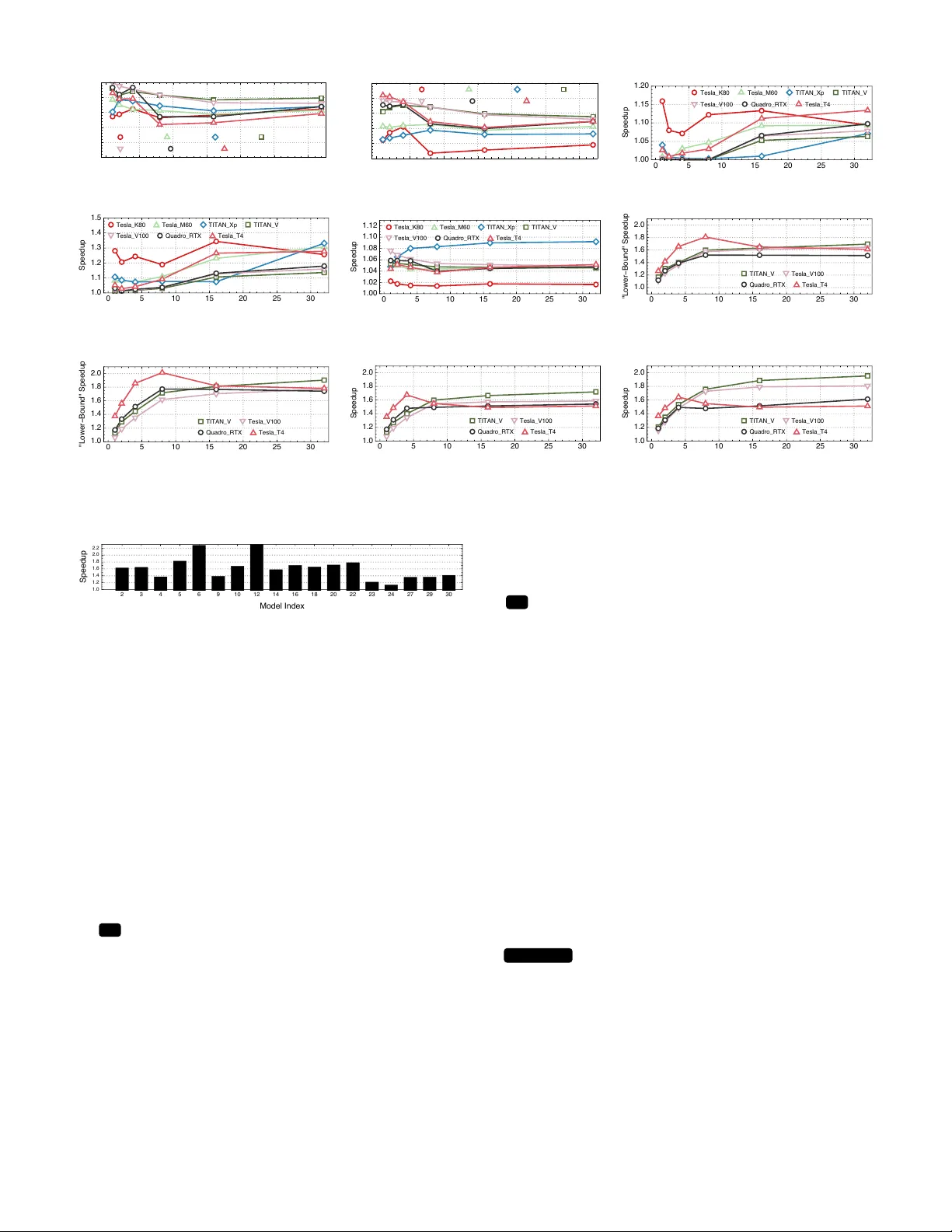
Benanza : Automatic µ Benchmark Generation to Compute “Lo wer -bound” Latency and Inform Optimizations of Deep Learning Models on GPUs Cheng Li * , Abdul Dakkak * Univ ersity of Illinois Urbana-Champaign Urbana, USA { cli99, dakkak } @illinois.edu Jinjun Xiong IBM T . J. W atson Research Center Y orkto wn Heights, USA jinjun@us.ibm.com W en-mei Hwu Univ ersity of Illinois Urbana-Champaign Urbana, USA w-hwu@illinois.edu Abstract —As Deep Learning (DL) models hav e been increas- ingly used in latency-sensitive applications, ther e has been a gro wing interest in impro ving their response time. An important venue for such impro vement is to profile the execution of these models and characterize their performance to identify possible optimization opportunities. Ho wever , the curr ent profiling tools lack the highly desired abilities to characterize ideal perfor - mance, identify sources of inefficiency , and quantify the benefits of potential optimizations. Such deficiencies ha ve led to slow characterization/optimization cycles that cannot keep up with the fast pace at which new DL models are introduced. W e propose Benanza , a sustainable and extensible bench- marking and analysis design that speeds up the characteriza- tion/optimization cycle of DL models on GPUs. Benanza consists of four major components: a model pr ocessor that parses models into an internal repr esentation, a configurable benchmark generator that automatically generates micro-benchmarks given a set of models, a database of benchmark results, and an analyzer that computes the “lower -bound” latency of DL models using the benchmark data and inf orms optimizations of model execution. The “lower -bound” latency metric estimates the ideal model execution on a GPU system and serves as the basis for identifying optimization opportunities in frameworks or system libraries. W e used Benanza to ev aluate 30 ONNX models in MXNet, ONNX Runtime, and PyT orch on 7 GPUs ranging from Kepler to the latest T uring, and identified optimizations in parallel layer execution, cuDNN con volution algorithm selection, framework inefficiency , layer fusion, and using T ensor Cores. I . I N T RO D U C T I O N The past few years have seen a spur of deep learning (DL) innovations. These innov ations span from DL models to software stack optimizations (e.g. frameworks such as MXNet or PyT orch, libraries such as cuDNN or MKL-DNN) and hardware stack improvements (e.g. CPU, GPU, FPGA). Among all the inno v ations, howe ver , DL models are the most rapidly ev olving and prolific. This is true in both academia [ 1 ] and industry [ 2 ], where models are tweaked and introduced on a weekly , daily , or e ven hourly basis. Both industry and academia have in vested heavily in devel- oping benchmarks to characterize DL models and systems [ 3 ], [ 4 ], [ 5 ], [ 6 ], [ 7 ]. Characterization is followed by optimiza- tions to improve the model performance. Howe ver , there is ∗ The two authors contributed equally to this paper. % Fig. 1. The GPU kernel time breakdown for all 30 models (listed in T able I) on T esla V100 (T able III) using batch size 1. Both cuDNN and cuBLAS in voke child GPU kernel(s) asynchronously . Therefore, we measure the time of the kernels launched by the cuDNN and cuBLAS APIs rather than the time of the APIs themselves for accurate characterization of latencies. currently a gap between the benchmarking results and possible optimizations to perform. Researchers use profilers, such as n vprof [ 8 ], Nsight [ 9 ], and VT une [ 10 ], to profile and get lo w- lev el GPU and CPU information. With ample knowledge of how models execute and utilize system resources, researchers manually identify bottlenecks and inefficiencies within model ex ecution using the profilers. Researchers then make h ypotheses of solutions, and try out different ideas to optimize the model ex ecution — which may or may not pan out. This manual and ad-hoc process requires a lot of ef fort and e xpertise and slo ws down the turnaround time for model optimization and system tuning. Thus there is a need for a systematic DL benchmarking and subsequent analysis design that can guide researchers to potential optimization opportunities and assess hypothetical ex ecution scenarios. Since for GPUs model ex ecution latenc y is determined by the hardware, framework, and system libraries (primarily cuDNN [ 11 ] and cuBLAS [ 12 ] for DL), answers to the following questions are highly desired by researchers: Q 1 what is the potential latenc y speedup if optimizations are performed? Q 2 Are independent layers ex ecuted in parallel? Q 3 Are con volution layers using the optimal conv olution algorithms? Q 4 Are there any inefficiencies or unexpected behavior in a frame work? Does the execution Q 5 fuse layers or Q 6 lev erage T ensor Cores, and what are the benefits? W e motiv ate our design by answering these 6 questions, while ensuring the sustainability and extensibility of the design. T o answer these questions, we first propose a ne w benchmark- ing metric: “lower-bound” latency . The “lower -bound” latency estimates the ideal latency of a DL model giv en a software and hardware stack, and is based on the following observ ations: (1) DL models are executed as layers in frameworks and thus layers form the performance b uilding blocks of DL models. (2) Framew orks delegate execution of common layers to either cuDNN or cuBLAS (sho wn in Figure 1). The “lower -bound” latency is defined in terms of the latencies of the cuDNN and cuBLAS API functions corresponding to the model layers (framew ork o verhead and memory transfers are ignored). W e refine the “lower -bound” latency and define it under sequential execution mode (all layers are executed sequentially) and parallel execution mode (data-independent layers are e xecuted asynchronously). This paper presents Benanza (pronounced bonanza) — a sustainable and e xtensible benchmarking and analysis design. Benanza consists of a set of modular components: (1) a model processor to process input ONNX models into a set of unique layers (layers are considered the same if they have the same layer type, shape, and parameters), (2) a benchmark generator to automatically generate parameterized cuDNN and cuBLAS micro-benchmarks from the unique layers, (3) a performance database to store historical benchmark results, and (4) an analyzer to compute the “lo wer-bound” latency of DL models and inform potential optimizations ( Q 1-6 ). Benanza is architected to be sustainable. The benchmarking workflo w of Benanza is highly automated and minimizes the benchmark dev elopment and maintenance effort. Benan za uses the observ ation that DL models have repeated layers (i.e. non-unique) within and across models to decrease the time to benchmark. When a new model is introduced, only the new , un-benchmarked layers (not in the performance database) need to be benchmarked. Although the focus of the paper is on NVIDIA GPUs using cuDNN and cuBLAS, the design proposed is extensible and users can incorporate other benchmark runtimes that target other software libraries or hardware such as: frame works’ API or MKL-DNN for CPUs. In summary , this paper makes the follo wing contrib utions: • W e propose a “lower-bound” latency metric for DL models based on the observ ation that the latency of a DL model is bounded by the latencies of the cuDNN and cuBLAS API calls corresponding to the model layers. The “lo wer-bound” latency metric estimates the ideal latency of a model giv en a specific GPU hardw are and softw are stack. • W e present Benanza , a nov el benchmarking and analysis system designed to automatically generate micro-benchmarks gi ven a set of models; compute their “lo wer-bound” latencies using the benchmark data; and inform optimizations of their ex ecution on GPUs. Benanza is sustainable and extensible to cope with the fast ev olution of DL innov ations. • Using Benanza , we characterized the “lower -bound” latencies of 30 ONNX models (shown in T able I) using MXNet, ONNX Runtime, and PyT orch on 7 systems (sho wn in T able III). W e performed a comprehensive “lo wer-bound” latency analysis as we vary the model, execution mode, batch size, and system. E.g., when using parallel execution mode, up to 2.87 × (with a geometric mean of 1.32 × across models) latenc y speedup could be made to MXNet using batch size 1 on the Tesla_V100 system. • W e identified optimization opportunities through Benanza in cuDNN conv olution algorithm selection (up to 1.32 × geometric mean speedup across models), inefficiencies within MXNet (up to 1.15 × speedup across models) and PyT orch (up to 2.3 × speedup using batch size 1 ) frameworks, and layer fusion and T ensor Cores (up to 1.09 × and 1.72 × speedup for ResNet50-v1 respectiv ely). W e further demonstrated that when performed jointly , these optimizations achiev e up to 1.95 × speedup for ResNet50-v1 across systems and batch sizes. I I . B AC K G RO U N D A N D M O T I V AT I O N A. DL Model Execution and ONNX F ormat A DL model is an execution graph where each vertex is a layer operator (e.g. con volution, activ ation, normalization, pooling, or softmax). These layer operators (or layers for short) are functions defined by a DL frame work. A framew ork ex ecutes a model by trav ersing the model graph in topological order and enqueuing the layers into an execution queue. Although sequential e valuation is always valid, frame works striv e to ex ecute data-independent layers within the queue in parallel. Through ex ecution scheduling, a framework can o ver- lap communication with computation, run two data-independent layers in parallel, etc. Regardless of the ex ecution strategy , ho wev er , layer execution latency is the limiting factor for model ex ecution. Therefore, layers are not only the b uilding blocks by which de veloper define models, but are also the atomic components that define a model’ s performance characteristics. Each framew ork provides its own API, layer definition semantics, model storage format, and model ex ecuting strategy . T o increase interoperability between framew orks, there has been concerted effort [ 13 ], [ 14 ] to standardize layer definitions and model exchange format. A leading ef fort is the Open Neural Network Exchange F ormat (ONNX), which has wide industry and framework backing. Framew orks such as Caf fe2, CNTK, MXNet, Paddle, PyT orch, and T ensorR T readily support ONNX, and con verters exist for other frameworks such as Caffe and T ensorFlo w . T o perform a fair comparison between framew orks (by ev aluating them using the same ONNX model), and more importantly , to make Benanza framework-agnostic, we choose ONNX as the model input format for Benanza . ONNX hosts all their models publicly [ 15 ] and, we select 30 vision models out of the 32 models av ailable at the time of writing for ev aluation (the 2 models not selected are non-vision models). The selected models cover an array of tasks and are listed in T able I. W e refer to these models by their IDs throughout the paper . B. cuDNN and cuBLAS Much like BLAS or LAP ACK are the backbone of HPC computing, cuDNN and cuBLAS form the backbone of the GPU software stacks for DL. cuDNN is a GPU-accelerated li- brary which provides highly tuned functions that implement DL layers such as con volution, pooling, normalization, acti vation. cuBLAS is a GPU-accelerated BLAS library which provides Mo d e l Exe cu t i o n Pro f i l e Be n a n za An a l yze r O N N X Mo d e l Pro ce sso r Sh a p e I n f e r Mo d e l Pa rse r L a ye r U n i f i e r Au t o ma t i c Be n ch ma rk G e n e ra t o r Al g o ri t h m I n st a n t i a t i o n cu D N N a n d cu BL AS Be n ch ma rks D a t a T yp e I n st a n t i a t i o n Be n ch ma rk R u n t i me Pe rf o rma n ce D B T i t a n _ Xp … T e sl a _ T 4 T e sl a _ V1 0 0 §III.A §III.D §III.B §III.C L a t e n cy § IV .A : W h a t i s t h e i d e a l (“l o w e r-b o u n d ”) l a t e n cy o f t h e mo d e l o n a syst e m? 𝓠 1 § IV .C : Are t h e re a n y i n e f f i ci e n ci e s mo d e l e xe cu t i o n b y f ra me w o rks? 𝓠 4 § IV .A : Do independent l a ye rs w i t h i n t h e mo d e l ru n i n p a ra l l e l ? 𝓠 2 § IV .D : W h a t i s t h e l a t e n cy i mp ro ve me n t s o f p e rf o rmi n g l a ye r f u si o n ? 𝓠 5 § IV .E : Are T e n so r C o re s u se d a n d w h a t a re t h e l a t e n cy b e n e f i t s o f u si n g T e n so r C o re s? 𝓠 6 § IV .B : Are t h e co n vo l u t i o n l a ye rs u si n g t h e o p t i ma l a l g o ri t h ms? 𝓠 3 cu D N N / cu BL AS L o g s N si g h t Pro f i l e An a l ysi s W o rkf l o w Be n ch ma rki n g W o rkf l o w T e sl a _ K8 0 T e sl a _ M6 0 §III.D 1 2 3 5 4 4 5 5 5 Fig. 2. The Benanza design and workflow . T ABLE I T H E 30 O NN X M O D EL S U S E D AR E V I S IO N M O D EL S W H I CH E N C O MPA S S I M AG E CL A S S IFI C A T I ON ( I C ) , O B J E CT D E T E CT I O N ( OD ) , FAC E R E CO G N I TI O N ( F R ) , E M OT I ON R E C O GN I T I ON ( E R ) , S E M A NT I C S E GM E N T A T I ON ( S S ) , O R H A N D DI G I T R EC O G N IT I O N ( HR ) TA SK S . ID Name T ask MA Cs # Layers Y ear 1 Arcface [16] FR 12.08G 412 2018 2 BVLC-Alexnet [17] IC 656M 24 2012 3 BVLC-Caffenet [17] IC 721M 24 2012 4 BVLC-Googlenet [18] IC 1.59G 143 2014 5 BVLC-RCNN-ILSVRC13 [19] IC 718M 23 2013 6 Densenet-121 [20] IC 2.87G 910 2016 7 DUC [21] SS 34.94G 355 2017 8 Emotion Ferplus [22] ER 877M 52 2016 9 Inception-v1 [23] IC 1.44G 144 2015 10 Inception-v2 [24] IC 2.03G 509 2015 11 LeNet [25] HR 796K 12 2010 12 MobileNet-v2 [26] IC 437M 155 2017 13 Resnet18-v1 [27] IC 1.82G 69 2015 14 Resnet18-v2 [28] IC 1.82G 69 2016 15 Resnet34-v1 [27] IC 3.67G 125 2015 16 Resnet34-v2 [28] IC 3.67G 125 2016 17 Resnet50-v1 [27] IC 3.87G 175 2015 18 Resnet50-v2 [28] IC 4.10G 174 2016 19 Resnet101-v1 [27] IC 7.58G 345 2015 20 Resnet101-v2 [28] IC 7.81G 344 2016 21 Resnet152-v1 [27] IC 11.30G 515 2015 22 Resnet152-v2 [28] IC 11.53G 514 2016 23 Shufflenet [29] IC 127M 203 2015 24 Squeezenet-v1.1 [30] IC 352M 66 2016 25 Tiny Y olo-v2 [31] OD 3.13G 32 2016 26 Vgg16-BN [32] IC 15.38G 54 2014 27 Vgg16 [32] IC 15.38G 41 2014 28 Vgg19-bn [32] IC 19.55G 63 2014 29 Vgg19 [32] IC 19.55G 47 2014 30 Zfnet512 [33] IC 1.48G 22 2013 fast implementations of GEMM and GEMV . The DL layers supported by each API are listed in T able II. And, while there is a wide array of DL frame works, common between them is the reliance on the primitiv es defined by cuDNN and cuBLAS. In fact, all major DL frame works, such as MXNet, PyT orch, ONNX Runtime, and T ensorFlo w , rely on cuDNN/cuBLAS API functions for the implementation of common layers. Figure 3 shows the percentage of layers supported by cuDNN and cuBLAS for each model in T able I. Most layers within DL models are co vered by the cuDNN and cuBLAS API. The layers that are not supported are non-compute operators (such T ABLE II E L EV E N L A Y E R T Y PE S A R E S UP P O RT ED B Y C U D NN A N D T WO L A Y E R T Y PE S A R E S UP P O RT ED B Y C U B LA S . E AC H A P I M AY HA V E AU X IL I A RY F U NC T I O NS T O S E TU P I T S A RG U M EN T S ( E . G . C U D N N S E T T E N S O R 4 D D E S C R I P T O R T O S PE C I F Y A TE N S O R ’ S D I ME N S I ON S A N D C U D N N S E T C O N V O L U T I O N 2 D D E S C R I P T O R T O C O NFI G U R E TH E C O N VO LU T I O N AP I ) . T HE C O N VO L UT I O N , R N N , A ND G E MM A P I S H A V E T EN S O R C OR E S U P PO RT . Layer Type cuDNN / cuBLAS API T ensor Core Support Conv olution cudnnConvolutionForward 3 Activ ation cudnnActivationForward 7 BatchNorm cudnnBatchNormalizationForwardInference 7 Conv+Bias+Acti vation cudnnConvolutionBiasActivationForward 3 RNN cudnnRNNForwardInference 3 Dropout cudnnDropoutForward 7 Pooling cudnnPoolingForward 7 Softmax cudnnSoftmaxForward 7 Add cudnnAddTensor 7 Element-wise cudnnOpTensor 7 Rescale cudnnScaleTensor 7 GEMM cublas * Gemm / cublasGemmEx 3 GEMV cublasSgemv 7 as concatenate, which joins two tensors across a specified axis) or datatype manipulations (such as reshape, which changes the dimensions of a tensor). For example, the cuDNN and cuBLAS functions support 70% of the Inception-v2 (ID = 10 ) layers. This is because Inception-v2 makes heavy use of unsqueeze — a tensor reshape layer — and 27% of the layers in Inception-v2 are unsqueeze layers. Giv en a specific DL software stack (e.g. framew ork, cuDNN, cuBLAS, driv er , and other CUD A libraries) and GPU hardware, the cuDNN and cuBLAS functions in vok ed by a model are fixed. Most common layers are supported by cuDNN and cuBLAS and the latenc y attributed to cuDNN and cuBLAS functions is significant with respect to the model’ s compute latency . Figure 1 sho ws that for the 30 vision models, the time spent within the cuDNN and cuBLAS API calls dominates the model’ s GPU kernel time. The “other” time is either memory operations or frame work GPU kernels which are neither cuDNN nor cuBLAS API calls. Based on the abo ve observ ations, we propose a “lower-bound” latency metric for DL models, which is defined by the latencies of the cuDNN and cuBLAS API functions corresponding to the model layers given a specific software/hardware stack. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 26 25 27 28 29 30 0 20 40 60 80 100 Model Index % Suppor ted Fig. 3. The percentage of layers supported by cuDNN and cuBLAS (also covered by Benanza ) for each model in T able I. The “lower -bound” latency forms an ideal latency , which we use to understand ho w to improve the model’ s latency . W e compute the “lo wer-bound” latency under dif ferent e xecution scenarios to determine if optimizations can be made, pinpoint where optimization opportunities are, and quantify the potential benefits of optimizations, as detailed in Section III. I I I . Benanza D E S I G N A N D I M P L E M E N TA T I O N Benanza consists of four main components: Model Processor, Automatic Benchmark Generator , Performance Database, and Analyzer . The components are sho wn in Figure 2 and are used in the benchmarking and analysis w orkflo ws: • Benchmarking workflow: 1 The Model Processor takes ONNX models as input, parses them, performs shape infer - ence, and finds the set of unique layers within the models. T wo layers are considered the same (non-unique) if they hav e the same operator type, shape, and parameters (i.e. only differ in weight values ). 2 The Automatic Benchmark Generator then generates micro-benchmarks for each unique layer . The generated micro-benchmarks measure the latency (or the GPU kernel metrics if profiling mode is enabled) of the corresponding cuDNN or cuBLAS function calls for the layers. 3 The micro-benchmarks are then run on systems of interest and the results are stored in the Performance Database. • Analysis workflow: 4 The user runs the target model using a frame work on a system of interest with utilities provided by Benanza to get the model e xecution profile (i.e. the model’ s latenc y , cuDNN and cuBLAS logs, and Nsight profile). 5 The user then specifies the model and system to Benanza . The model is parsed into layers and the Analyzer queries the latencies of each layer from the Performance Database (using the layers and system information pro vided) to compute the Q 1 “lower -bound” latency under different ex ecution scenarios. By analyzing the model execution profile and the computed “lower -bound”, the Analyzer informs optimizations in: Q 2 parallel ex ecution of independent layers, Q 3 con volution algorithm selection, Q 4 framew ork inefficienc y , Q 5 layer fusion, and Q 6 T ensor Core usage. A. Benanza Model Pr ocessor The 1 Model Processor parses ONNX models into Ben anza ’ s internal representation (IR). The IR wraps around the ONNX Protobuf and has the same layer coverage. Since ONNX models do not ha ve layer shapes information embedded (except for the input layers), shape inference [ 34 ] is performed to determine the shape of each layer . Layers in the IR (referred to as layers and correspond to the ONNX nodes) are annotated with the inferred shapes. Benchmarks are generated for each layer using its type, shape, and parameters information. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 26 25 27 28 29 30 0 20 40 60 80 100 Model Index % Unique Fig. 4. The percentage of unique layers within the 30 models W e observe that layers with the same type, shape, and parameters (i.e. only differ in weight values ) are repeated extensi vely within and across models. Figure 4 shows that most models have a low percentage of unique layers — indicating that layers are repeated extensi vely within the model. For example, ResNet50-v1 (ID= 17 ) has 175 layers but only 47 ( 26.9% ) are unique. The number of unique layers across models of similar architecture is also low . The ResNet * -v1 models (ID= 13, 15, 17, 19, 21 ) are built from the same modules and hav e a total of 1229 layers, of which only 60 ( 5.6% ) are unique. Across all 30 models, the total number of layers is 5754 , but only 1031 ( 18% ) are unique. W e exploit this layer repeatability to optimize the benchmark generation and minimize the time to benchmark. Thus, the Model Processor unifies the repeated layers across the input models and produces a set of unique layers. The time sav ed can be used to e xplore other algorithms and data types (Sections III-B2 and III-B3) benchmarks. B. Automatic Benchmark Generator The 2 Automatic Benchmark Generator uses the set of unique layers (produced by the Model Processor) and generates C++ code to in voke the benchmark runtime using each layer’ s type, shape, and parameters information. 1) The Benchmark Runtime: Benanza provides a benchmark runtime that measures the latency of the cuDNN or cuBLAS APIs required to ex ecute each layer (as shown in T able II). The runtime also sets up the function arguments for each API. The setup time is not included in the latency measurement. The runtime uses the Google Benchmark [ 35 ] library — a micro- benchmarking support library . The Google Benchmark library dynamically determines the number of iterations to run each benchmark and ensures that the reported latenc y results are statistically stable. Generated benchmarks are link ed with the cuDNN/cuBLAS libraries, and are run on systems of interest. 2) Algorithm Instantiation: The con volution layers map to the cudnnConvolutionForward API (T able II). The con volution API takes one of the follo wing 8 algorithms as an argument: Implicit GEMM (IGEMM), Implicit PreComputed GEMM (IPGEMM), GEMM, Direct (DRCT), FFT , T iled FFT (TFFT), W inograd (WING), and W inograd Non-Fused (WINGNF). These algorithms have different compute and memory characteristics [ 36 ], [ 37 ]. The optimal algorithm to use depends on the system, layer shape, and layer param- eters (e.g. filter size, stride, dilation, etc.) [ 11 ]. For infer- ence, most frameworks (e.g. MXNet, PyT orch, T ensorFlow) rely on the cuDNN provided heuristic function ( cudnn GetConvolutionForwardAlgorithm ) to choose the con volution algorithm. The heuristic function suggests an algorithm giv en the layer’ s shape, parameters, data type, system, etc. T o explore the design space of algorithm selection, by default, for each layer Benanza generates benchmarks using all algorithms applicable to the layer . 3) Data T ype Support: Benanza can be configured to generate micro-benchmarks that target dif ferent data types. Both float16 and float32 are generated by def ault, but benchmarks can be instantiated for other data types. The float16 benchmarks use T ensor Cores when the API function (see T able II) and the system (see T able III) support it. 4) Layer Fusion Support: Benanza can be configured to generate micro-benchmarks that target the cuDNN fused API ( cudnnConvolutionBiasActivationForward ) to perform the conv olution, bias, and activ ation layer se- quence. T wo fusion pattern rules are currently handled by Benanza : Con v → Bias → Activ ation and Conv → Bias. The Con v → Bias → Acti vation maps directly to the fused API. Fusing Con v → Bias is implemented through the fused API using CUDNN_ACTIVATION_IDENTITY as the activ ation function and requires cuDNN version ≥ 7.1 . For older cuDNN versions, the Con v → Bias is implemented as two calls — a cudnn ConvolutionForward follo wed by a cudnnAddTensor . Users can extend Benanza ’ s fusion support by re gistering new fusion patterns as the cuDNN fused API ev olves. 5) Integr ation with CUPTI: Benanza can be configured to generate benchmarks that integrate with low-le vel GPU profiler libraries such as NVIDIA ’ s CUPTI [ 38 ]. This integration allo ws Benanza to capture detailed GPU metrics [ 39 ] of benchmarks such as flops, memory transfers, etc. In this mode, the user specifies the metrics of interest, the number of benchmark iterations for warm-up, and the number of iterations to measure. Benanza does not use the Google Benchmark in this mode since a fixed, small number of profiling runs suffice for statistically stable measurement of the metrics. The profiling outputs (name, timing, and metric v alues of GPU kernels) are stored as metadata to the corresponding benchmark entry in the Performance Database. C. P erformance Database The 3 benchmarking results are collected and published to Benanza ’ s Performance Database. Each entry within the database is inde xed by the system, data type, and layer (type, shape, and parameter information). The Analyzer queries the database to get the benchmark latencies. If a query is a miss, then a w arning with the information about the missing benchmark is issued to the user and the user is ask ed if the y wish the Automatic Benchmark Generator to generate the missing benchmarks. D. Benanza Analyzer The 4 user runs the tar get model using a frame work on a system of interest with utilities provided by Benanza to get the model execution pr ofile . The model execution profile contains information about the model’ s latenc y , cuDNN and cuBLAS logs, and Nsight profile (which contains cuDNN/cuBLAS API calls and function backtrace information). Capturing the model’ s latency requires the user to place the provided timing functions within their application code. T o capture the usage maxpool_2 MaxPool 10.228µs conv_4 Conv 30.51 1µs conv_5 Conv 30.719µs conv_7 Conv 30.231µs maxpool_3 MaxPool 10.102µs relu_4 Relu 8.046µs concat_1 Concat relu_5 Relu 8.045µs conv_6 Conv 47.652µs relu_6 Relu 8.122µs relu_7 Relu 7.963µs conv_8 Conv 41.912µs relu_8 Relu 8.017µs conv_9 Conv 30.465µs relu_9 Relu 8.017µs ... ... Layer Name Layer T ype Benchmark Latency Legend: Fig. 5. The first parallel module of Inception-v1 in Figure 8 visualized by the Benanza Analyzer . The layers are annotated with the name, type, and latency used for the “lower-bound” calculation. The critical path used in the parallel mode is highlighted in red. of cuDNN and cuBLAS functions within a frame work, Benan za launches the user code with the CUDNN_LOGINFO_DBG and CUBLAS_LOGINFO_DBG en vironment v ariables. These en vironment variables enable the cuDNN and cuBLAS loggers respectiv ely . Utilities to run the user code using NVIDIA ’ s Nsight profiler are also provided. The results from Nsight are parsed and correlated with the cuDNN and cuBLAS logs. The 5 user then inputs the model execution profile along with the ONNX model, system, data type. The model is parsed by the Model Processor into layers. Then, the Benanza Analyzer queries the Performance Database for the benchmark latencies of each layer using the user-specified system and data type (by default float32 ). Due to algorithm (Section III-B 2) instantiation, multiple benchmarks may exist for a layer . The Analyzer , therefore, selects the benchmark result achie ving the lowest latency . The follo wing analyses are then performed: 1) Q 1,2 Sequential and P arallel “Lower-Bound” Latency: DL models may contain layer sequences which can be executed independently in parallel. The sub-graph formed by these data- independent layer sequences is called a parallel module . For example, a parallel module in Inception-v1 is shown in Figure 5. A framework may ex ecute the independent paths within the parallel module either sequentially or in parallel. Thus, the Analyzer computes the “lower -bound” latency of a model using tw o execution modes: sequential and parallel. The sequential mode assumes that independent layers are ex ecuted sequentially , and therefore is defined as the sum of each layer’ s benchmark latency . The parallel strategy assumes that data-independent layers are executed in parallel. Therefore, the parallel “lower -bound” latency is defined by the model’ s critical path — the simple path from the start to the end layer with the highest latency . Finding the critical path of a graph is a longest path problem and is NP-hard. Since a DL model forms a directed acyclic graph (D A G), the critical path can be framed as a shortest path problem [ 40 ]. T o compute the critical path we construct a weighted D AG from the model graph where the edge weight between tw o nodes (layers) is negati ve of the latency of the layer at the tail of the edge. Computing the shortest path from the start to the end layer of the constructed weighted D AG produces the critical path of the model. The parallel “lo wer-bound” latency is the sum of layers latencies along the critical path. Benanza visualizes the critical path of the model (e.g. Figure 5), and the dif ference between the sequential and parallel “lower -bound” latencies indicates the profit of e xecuting independent layers in parallel. Other analyses performed by Benanza le verage the sequential and parallel “lower-bound” latencies, and the benefits can be calculated in terms of either sequential or parallel mode. 2) Q 3 Con volution Algorithm Selection: The Analyzer uses the parsed cuDNN log in the model execution profile to determine if the cuDNN algorithm used by the framework for each layer is optimal (recall from Section III-B 2 that benchmark results using all a vailable algorithms for layers exist in the Performance Database). Cases where the algorithm choice is sub-optimal are reported to the user along with how much latency impro vement could be gained if algorithm selection was ideal. The user can act upon these suggestions by forcing the framework to use a specific algorithm for each layer . 3) Q 4 F ramework Inefficiency Inspection: The expected cuDNN and cuBLAS API calls are known to the Analyzer from the “lo wer-bound” latency computation. The Analyzer compares the model ex ecution profile against the expected ex ecution to pinpoint inefficiencies within the framework. The user is presented with any deviation observ ed in cuDNN or cuBLAS API in vocation’ s parameters or their execution order . CUD A API functions and CUDA kernels ex ecuted between cuDNN or cuBLAS API calls, are also presented to the user — along with their backtraces. 4) Q 5 Layer Fusion Analysis: If the user enables the benchmark generation for layer fusion (as described in Sec- tion III-B 4), then the Analyzer can be used to determine the potential profitability if layer fusion is employed. The Analyzer trav erses the model layers and looks for the fusion pattern rules (listed in Section III-B 4). If one of these patterns is found, then the corresponding fused operation’ s latency is queried from the database and is used in the “lower-bound” computation (in either sequential or parallel mode). If the benchmark is unav ailable, or failed to run, then the latencies of the non- fused layers are used. The difference between the non-fused “lower -bound” latency and the fused “lo wer-bound” latency determines the profitability of layer fusion. 5) Q 6 T ensor Core Analysis: The Analyzer determines if the tar get model execution utilizes T ensor Cores by looking at kernel names in the model ex ecution profile. Kernel names that match the _[ish]\d+ * Regular -expression use T ensor Cores. By def ault, benchmarks targeting both float16 and float32 are generated. When benchmarks are run on systems with T ensor Core support, the difference between the “lower - bound” latency of float32 and float16 informs the profitability of using T ensor Cores with float16 . E. Sustainability and Extensibility The sustainability of Benanza is ensured by providing an automated benchmark generation and analysis workflo w design along with a continuously updated Performance Database. Benchmarking requires limited ef fort, as the micro-benchmarks are automatically generated, and the user only needs to compile and run the generated code on systems of interest. A big insight of the proposed design is that there is ample layer repeatability within and across models. This keeps the number of unique layers and thus the number of Performance Database entries in check over time. For new models, only the ne wly introduced unique layers are benchmarked. For example, consider a scenario where all models in T able I except for ResNet * -v2 hav e already been benchmarked and the results are in the Performance Database. Using our design, benchmarking the ResNet * -v2 models requires measuring all the ResNet * -v2 layers that are not within the Performance Database. Evaluating this hypothetical scenario results in a 75% reduction ( 30 minutes) in benchmarking time on the Tesla_V100 system for batch size 32 . The saving would be e ven larger on slower systems. By storing and reusing the micro-benchmark results in the Performance Database we minimize the time cost of running micro-benchmarks. Benanza is e xtensible. As sho wn in Figure 2, Benanza is designed as a set of modular components. As ne w cuDNN functions are introduced, users update the Benanza runtime ac- cordingly . For example, if a new cuDNN con volution algorithm is added, then the user can just add it to the list of algorithms to instantiate in the con volution benchmark implementation. If a ne w cuDNN/cuBLAS API or a fused API is added, then a user needs to add the benchmark implementation for the new API using the templates provided by Benanza . Users can also e xtend the Automatic Benchmark Generator to support other runtimes that target other softw are libraries or hardware, and leverage most of the other components unmodified. These runtimes can tar get the framew orks’ Python or C++ API or other DL libraries (e.g. MIOpen [ 41 ] on AMD GPUs, or MKL- DNN [ 42 ] on CPUs). Through the novel benchmarking and analysis design, Benanza copes well with the fast e volving pace of DL innov ations. I V . E V A L UATI O N W e implemented Benanza and ev aluated its design by answering Q 1-6 . W e ev aluated 30 ONNX models (listed in T able I) in the MXNet (v 1.5.1 ), ONNX Runtime (v 0.5.0 ), and PyT orch (v 1.3 ) frame works. Experiments were run on the 7 systems listed in T able III. All systems use Ubuntu 18.04.3 L TS, CUDA 10.1.243 , cuDNN V ersion 7.6.3 , and CUD A Dri ver 430.26 . The micro-benchmarks were compiled with GCC 7.4.0 . W e first computed the float32 “lower - bound” latenc y in both sequential and parallel modes. Then we used the Analyzer to uncov er and explore optimization opportunities — cuDNN heuristics, framew ork inefficiencies, layer fusion, and usage of T ensor Cores, and show their impact on the latenc y . A. “Lower-Bound” Latency vs. Measur ed Latency W e measured the inference latenc y of the 30 models using MXNet, ONNX Runtime, and PyT orch on the Tesla_V100 system. Figure 6 shows the measured latency across all models and Figure 7 compares the latencies using different framew orks. T ABLE III W E U SE D 7 G P U S Y ST E M S F OR E V A L UA T I O N . T H E S Y ST E M S C OVE R T H E PAS T G P U G EN E R A T I O NS ( F RO M K E P LE R T O T HE L ATE S T T UR I N G ). A M A Z ON C L OU D ( A W S ) I S U S E D FO R 4 O F T H E S YS T E M S AN D T H E OT H E R 3 A RE L O C A L MA CH I N E S . T H E 4 T U R I NG A N D V O LT A G P U S S UP P O RT T EN S O R C OR E S A N D TH E I R T HE O R E TI C A L T EN S O R C OR E P E RF O R M AN C E ( T EN S O R T FL O P S ) A R E L I ST E D . Name CPU GPU (Release Y ear) GPU Architecture GPU Memory Capacity , Bandwidth Theoretical FP32 TFLOPS Theoretical T ensor TFLOPS T esla K80 (A WS P2) Intel Xeon CPU E5-2686 v4 T esla K80 (2014) K epler 12 GB, 480 GB/s 5.6 7 T esla M60 (A WS G3) Intel Core i9-7900X CPU T esla M60 (2015) Maxwell 7 GB, 160.4 GB/s 4.8 7 TIT AN Xp Intel Xeon CPU E5-2686 v4 TIT AN Xp (2017) Pascal 12 GB, 547.6 GB/s 12.2 7 TIT AN V Intel Core i7-7820X CPU TIT AN V (2017) V olta 12 GB, 672 GB/s 14.9 110.0 T esla V100 (A WS P3) Intel Xeon CPU E5-2686 v4 T esla V100 SXM2 (2018) V olta 16 GB, 900 GB/s 15.7 125.0 Quadro R TX Intel Xeon CPU E5-2630 v4 Quadro RTX 6000 (2019) T uring 24 GB, 624 GB/s 16.3 130.5 T esla T4 (A WS G4) Intel Xeon Platinum 8259CL CPU T esla T4 (2019) T uring 15 GB, 320 GB/s 8.1 65.0 ( ) Model Index Fig. 6. The measured latency of all ONNX models using batch size 1 with MXNet backend on T esla V100 in T able III. Fig. 7. The measured latency of all ONNX models with MXNet, ONNX Runtime, and PyT orch backends (normalized to MXNet latency) using batch size 1 on T esla V100. Benanza Ratio Fig. 8. The Benanza Ratio in sequential and parallel mode of 30 models in MXNet using batch size 1 on Tesla_V100 . _ _ _ _ _ _ _ ( ) Batch Size Fig. 9. The measured latency of ResNet50_v1 in MXNet across batch sizes and systems. Due to the lack of support of some ONNX operators by ONNX Runtime [ 43 ] and PyT orch [ 44 ], not all models run within these framew orks. As MXNet is the fastest in general, subsequent sections of the paper (with the exception of Section IV -C ) focus on informing optimizations in MXNet. 1) Q 1,2 Sequential Mode vs P arallel Mode: The dif ference between the “lo wer-bound” latency and the measured latenc y indicates the optimization opportunities in the framew ork and its use of the cuDNN and cuBLAS APIs. A model’ s “lower - bound” latency normalized to its measured latency is referred to as its Benanza Ratio (BR). Figure 8 sho ws the BR in sequential ( BR sequential ) and parallel mode ( BR parallel ) in MXNet across all models using batch size 1 on the Tesla_V100 system. The BR sequential across models has a geometric mean of 0.88 , thus a potential latency speedup of 1.0 0.88 = 1.14 × can be made to the measured model ex ecution. The BR parallel across models has a geometric mean of 0.76 , indicating a potential latency speedup of 1.0 0.76 = 1.32 × . The difference between a model’ s parallel and sequential “lower -bound” latency depends on the existence of parallel modules within the model and ho w compute-intensiv e the data-independent paths are. Models without parallel modules hav e the same sequential and parallel “lower -bound” latency , thus the BR sequential is equal to the BR parallel . For models with compute-intensiv e parallel modules, such as the Inception models (ID= 4, 9, 10 ), the potential speedup of the latency (or 1 BR parallel ) is 2.87 × , 2.69 × , and 2.45 × respectiv ely . The BR sequential and BR parallel of LeNet (ID= 11 ) are both low because LeNet is a simple model which has low latency ( 0.33 ms as sho wn in Figure 6) and the MXNet ov erhead and other non-compute portion is high, thus its BR is low . The sequential “lower -bound” latenc y of the models with parallel modules (e.g. Inception and ResNet models) is closer to their measured latency when compared to the parallel “lo wer-bound” latenc y (BR parallel < BR sequential < 1 ). This suggests that parallel modules are e xecuted sequentially in MXNet, e ven though the data-independent layers could be run in parallel. W e v erified the sequential execution behavior in MXNet by inspecting the model ex ecution profile. Thus we ev aluated the benefits of the latter optimizations in terms of the sequential “lo wer-bound” latency . Fig. 10. The cuDNN heuristic selects 8 non-optimal con volution layer algorithms for ResNet50_v1 using batch size 32 on Tesla_V100 . Up to 2.75 × speedup can be achiev ed if selection was ideal. _ _ _ _ _ _ _ Fig. 11. The latenc y speedup achie ved for ResNet50_v1 by applying the MXNet optimization described in Section IV -C 1 across batch sizes and systems. 2) Batch Sizes and Systems: T o demonstrate Benanza ’ s functions across batch sizes and systems, we ev aluated the “lo wer-bound” latency of all models using dif ferent batch sizes from 1 to 32 on representativ e systems (sho wn in T able III). W e select batch size 32 , since some models cannot be run using batch sizes beyond 32 due to GPU memory limitations. Figure 9 sho ws the measured latency of ResNet50-v1 on all systems in log scale. As expected, latencies are rev ersely correlated to the compute capability of the system (e.g. theoretical FP32 TFLOPS in T able III). ResNet50-v1 has a higher latency on Quadro_RTX when compared to Tesla_V100 , since Quadro_RTX has an on-chip (global) memory bandwidth of 624 GB/s whereas Tesla_V100 has an on-chip memory bandwidth of 900 GB/s. Figure 12 shows the BR sequential of ResNet50-v1 across batch sizes and systems. The results suggest that ResNet50-v1 ’ s optimization opportunities are system and batch size dependent. Both Tesla_V100 and TITAN_V are highly optimized to run ResNet50-v1 across batch sizes, since their BR is high — ranging from 0.86 to 1.0 . The BR for Tesla_T4 and Quaro_RTX is high for batch sizes 1 to 4 but drops beyond that. ResNet50-v1 is less optimized on the other systems and has a lo w BR. The geometric mean of the BR sequential for all the mod- els across systems and batch sizes is shown in Figure 13. Both Tesla_V100 and TITAN_V still have a high BR ( 0.76 − 0.88 ). A drop was still observed for Tesla_T4 and Quaro_RTX at batch size 4 . Tesla_M60 and TITAN_Xp hav e a BR between 0.63 and 0.72 . The oldest GPU generation, Tesla_K80 , has the lo west BR and is the least optimized. Overall, the current softw are stack (latest MXNet, cuDNN, and CUDA libraries used in the e valuation) is more optimized for the recent GPU generations (T uring and V olta) using smaller batch sizes. Compared to V olta, the software stack is less optimized for Turing. This is possibly because Turing is newly released, and we expect optimizations that target T uring to increase. Moreover , the low BR for the older GPUs suggest that vendors prioritize optimizations for newer GPU generations ov er older ones. B. Q 3 cuDNN Con volution Heuristics Using the Benanza Analyzer , we observed that heuristics employed by cuDNN (and subsequently the frameworks) are not always optimal. For example, Figure 10 shows the con volution layer latencies using the algorithms informed by cuDNN heuristics (labeled as cuDNN Heuristic ) normalized to using the optimal algorithm (labeled as Ideal Algorithm ) for ResNet50_v1 using batch size 32 on Tesla_V100 . The algorithm choices are listed in Section III-B 2. Figure 14 shows the latency speedup for ResNet50_v1 across batch sizes and systems by using the optimal con volution algorithm for all con volution layers. Figure 15 sho ws the geometric mean of the latency speedup for all models by using the optimal algorithms. At batch size 32 , the speedup ranges between 1.14 × and 1.32 × across GPUs. Both the latest and older GPU architectures can benefit from better algorithm heuristics. C. Q 4 Inef ficiencies in F rame works W e used Benanza to identify the inef ficiencies in MXNet and PyT orch. W e then implemented the optimizations informed by Benanza and sho w the latency speedup after the framew ork modifications. 1) MXNet ONNX Model Loader: W e observed through the Analyzer that there are layers in the model execution profile where the cuDNN API ar guments de viate from what is expected. An inspection of the Analyzer’ s parsed Nsight profile pointed to an image_2d_pad_constant_kernel GPU kernel function being inv oked before ev ery con volutional layer . Non-zero padding leads to the observ ed deviation between the expected and actual cuDNN API calls. W e inspected the MXNet source code and found that padding layers are inserted during the loading of ONNX models in MXNet. ONNX supports specifying asymmetric padding as a parameter in con volution layers, whereas MXNet does not. Therefore, MXNet must insert padding layers before con volution layers where asymmetric padding is used when loading ONNX models. Howe ver , the MXNet ONNX model loader adds padding layers before e very con volution layer (regardless of the use of asymmetric padding). A non-intrusiv e optimization is to only insert padding layers if asymmetric padding is used. W ith this simple one-line optimization, we observed up to 1.15 × latency speedup for ResNet50-v1 (shown in Figure 11). 2) PyT or ch cuDNN Wr apper: Using Benanza we observed that there were excessi ve calls to cudaStreamWaitEvent between cuDNN API calls. Using the backtrace information from the model ex ecution profile, we identified the PyT orch source file that introduces these synchronizations. Upon further study of the source code, we found that all cuDNN functions are in vok ed by a cuDNN wrapper in PyT orch. The wrapper manages a pool of cuDNN handles and is designed to enable in voking cuDNN functions from different CPU threads. cuDNN Benanza Ratio _ _ _ _ _ _ _ Fig. 12. The BR sequential of ResNet50-v1 . _ _ _ _ _ _ _ Benanza Ratio Fig. 13. The geometric mean of the BR sequential of all models. _ _ _ _ _ _ _ Fig. 14. The latency speedup for ResNet50-v1 if the cuDNN heuristic selections were optimal. _ _ _ _ _ _ _ Fig. 15. The geometric mean of the latency speedup for all models by using the optimal conv o- lution algorithm. _ _ _ _ _ _ _ Fig. 16. The latency speedup for ResNet50-v1 if layer fusion was performed. _ _ _ _ - Fig. 17. The “lower-bound” latency speedup if T en- sor Cores ( NCHW ) were used for ResNet50-v1 . _ _ _ _ - Fig. 18. The “lower-bound” latency speedup for ResNet50-v1 if T ensor Cores ( NHWC ) were used. _ _ _ _ Fig. 19. The latency speedup for ResNet50-v1 if T ensor Cores ( NHWC ) were used. _ _ _ _ Fig. 20. The latency speedup for ResNet50-v1 if parallel ex ecution, optimal algorithm selections, layer fusion, and T ensor Cores ( NHWC ) were used. Fig. 21. The speedup achieved by removing unnecessary cuDNN API synchronizations in PyT orch on Tesla_V100 using batch size 1. functions managed by the same handle are synchronized and executed sequentially . In the current PyT orch (v 1.3 ), howe ver , a single handle is used for inference, and thus forced synchronization occurs before each cuDNN function call. The synchronizations cause 100 µs stalls on av erage between cuDNN functions, thus the latency saved through this optimization is a function of the number of layers in a model. W e modified PyT orch to elide the cuDNN wrapper and only synchronize before and after performing inference. Figure 21 shows the speedup achie ved by this optimization for batch size 1. MobileNet-v2 (ID= 12 ) achie ves a 2.3 × speedup, since it has low latency and a large number of layers. D. Q 5 Layer Fusion W e used Benanza to e valuate the potential benefits of layer fu- sion. Figure 16 shows the latency speedup from layer fusion for ResNet50-v1 across the systems. ResNet50-v1 has the layer sequence pattern Con v → Bias → BatchNorm → Activ ation. Benanza reports that the Conv → Bias sequence can be fused for better latency and performs the fusion analysis (Section III-D 4). In all, 64 ( 18% ) layers were fused and up to 1.09 × speedup was achiev ed ov er the measured latency across systems for ResNet150-v1 . By inspecting the model execution profile, we found no indication that MXNet, ONNX Runtime, or PyT orch perform layer fusion using the cuDNN fused API. E. Q 6 T ensor Cores W e used Benanza to ev aluate the potential benefits of using float16 and T ensor Cores available on recent GPU architectures. While the cuDNN T ensor Core API supports both NHWC and NCHW layout, NVIDIA recommends the use of NHWC . W e use Benanza to generate benchmarks targeting both the NHWC and NCHW layout and ev aluated the “lo wer-bound” latency speedup, as shown in Figures 18 and 17 respectively . As expected, using the NHWC achiev es higher speedup. Internally , the current cuDNN API implements NCHW con volutions in terms of NHWC with an implicit transposition. As compute dominates (i.e. larger batch sizes), the relativ e overhead of the transposition becomes small; hence, NCHW and NHWC hav e similar performance for larger batch sizes. Figure 19 shows the latency speedup by using T ensor Cores( NHWC ). TITAN_V achiev es significant speedup (up to 1.72 × ). W e can see that Tesla_T4 benefits most from T ensor Cores for smaller batch sizes (i.e. might be best used for low-latenc y inference). F . Q 1,2,3,5,6 P arallel Execution, Algorithm Selection, Layer Fusion, and T ensor Cor es Benanza can be used to perform the abo ve analysis jointly . T o demonstrate this, we analyzed the latency speedup when using parallel execution of data-independent layers, optimal algorithm selection, layer fusion, and T ensor Cores ( NHWC ). Figure 20 shows the latenc y speedup for ResNet50-v1 across batch sizes and systems. Up to a 1.95 × and 1.8 × speedup can be achiev ed by TITAN_V and Tesla_V100 respectiv ely . W e can surmise, from the pre vious analysis, that most of the profit for TITAN_V is attrib uted to its use of T ensor Cores. Quadro_RTX and Telsa_T4 achiev e marginal speedup ov er the T ensor Core results. V . R E L A T E D W O R K DL Benc hmarking : There has been no shortage of work on dev eloping benchmarks to characterize DL models. These DL benchmarks either take a model as a black-box and measure the user -observable latency and throughput (end-to- end benchmarks) or delve deeper into models to characterize the layer or kernel performance (micro-benchmarks). The end-to-end benchmarks [ 3 ], [ 4 ], [ 6 ] provide a corpus of models that are deemed to be of value to characterize for industry and research. Micro-benchmarks [ 5 ], [ 45 ], [ 46 ], [ 4 ] distill DL models into their layers or kernels, and are hand- curated. Micro-benchmarking enables easy measurements of layers within popular DL models and inte grates easily with profiling tools. In [ 47 ], the author present a design that enables benchmarking DL models at across the abstraction lev els of inference pipeline and introduce a hierarchical profiling methodology (enabling framework-, model-, and hardware- profiling). In [ 7 ], the authors propose a benchmark suite to enable fair comparison of DL techniques at dif ferent le vels of granularity . At the operator level, [ 7 ] takes ONNX models and generates micro-benchmarks that target the frame work’ s Python API to measure the latency of each operator . Benanza also takes ONNX models as input, but generates lower -lev el cuDNN and cuBLAS micro-benchmarks to compute the “lo wer-bound” latency of the model, and perform analysis. The authors are unaware of previous work which generates micro-benchmarks from model layers and couples it with an analysis workflo w to inform optimizations. P erformance Advising : There is past work on using profiling to inform users of possible optimizations. These optimizations are performed at the compiler lev el [ 48 ] or are plugins to code editors to inform proper usage of APIs[ 49 ], [ 50 ]. Low-le vel profile reports and some suggestions on how to address bottlenecks are pro vided by profilers and IDEs such as: NVIDIA ’ s Nvprof [ 8 ], Intel’ s VTune [ 10 ], Oracle’ s Solaris Studio [ 51 ], Microsoft’ s Roslyn [ 52 ], and IBM’ s XL [ 53 ]. T o the author’ s kno wledge, there has been no w ork on applying or specializing the optimization advising to the DL domain. V I . C O N C L U S I O N This paper presents Benanza , a sustainable and extensible DL benchmarking and analysis design that automatically generates layer-wise benchmarks for DL models to compute the “lower-bound” latency and inform optimizations on GPUs. W e use Benanza to e valuate a set of 30 models using different framew orks on 7 GPUs, and pinpointed the optimizations in parallel layer ex ecution, cuDNN algorithm selection, framew ork inefficienc y , layer fusion, and T ensor Core usage. The results show that Benanza fills a significant gap within the characteri- zation/optimization cycle and w ould boost the productivity of DL model, frame work, and library dev elopers. A C K N O W L E D G M E N T S This work is supported by the IBM-ILLINOIS Center for Cognitiv e Computing Systems Research (C3SR) - a member of the IBM Cognitiv e Horizon Network, and the Applications Driving Architectures (ADA) Research Center - one of the JUMP Centers co-sponsored by SRC and D ARP A. R E F E R E N C E S [1] J. Dean, D. Patterson, and C. Y oung, “ A new golden age in computer architecture: Empowering the machine-learning rev olution, ” IEEE Micr o , vol. 38, no. 2, pp. 21–29, Mar. 2018. [Online]. A vailable: https://doi.org/10.1109/mm.2018.112130030 [2] K. Hazelwood, S. Bird, D. Brooks, S. Chintala, U. Diril, D. Dzhulgako v , M. Fawzy , B. Jia, Y . Jia, A. Kalro, J. Law , K. Lee, J. Lu, P . Noordhuis, M. Smelyanskiy , L. Xiong, and X. W ang, “ Applied machine learning at facebook: A datacenter infrastructure perspective, ” in 2018 IEEE International Symposium on High P erformance Computer Arc hitectur e (HPCA) , IEEE. IEEE, Feb . 2018, pp. 620–629. [Online]. A vailable: https://doi.org/10.1109/hpca.2018.00059 [3] “MLPerf, ” github .com/mlperf, 2019, accessed: 2019-10-04. [4] “AI-Matrix, ” github.com/alibaba/ai- matrix, 2019, accessed: 2019-10-04. [5] Baidu, “DeepBench, ” github.com/baidu- research/DeepBench, 2019. [6] C. Coleman, M. Zaharia, D. Kang, D. Narayanan, L. Nardi, T . Zhao, J. Zhang, P . Bailis, K. Olukotun, and C. R, “ Analysis of DA WNBench, a time-to-accuracy machine learning performance benchmark, ” SIGOPS Oper . Syst. Rev . , vol. 53, no. 1, pp. 14–25, Jul. 2019. [Online]. A vailable: https://doi.org/10.1145/3352020.3352024 [7] T . Ben-Nun, M. Besta, S. Huber , A. N. Ziogas, D. Peter , and T . Hoefler, “ A modular benchmarking infrastructure for high-performance and reproducible deep learning, ” in 2019 IEEE International P arallel and Distributed Pr ocessing Symposium (IPDPS) . IEEE, May 2019, the 33rd IEEE International Parallel & Distributed Processing Symposium (IPDPS’19). [Online]. A vailable: https://doi.org/10.1109/ipdps.2019. 00018 [8] “NVIDIA nvprof, ” docs.n vidia.com/cuda/profiler- users- guide/index.html, accessed: 2019-5-04. [9] “NVIDIA Nsight System, ” dev eloper .nvidia.com/nsight- systems, ac- cessed: 2019-5-04. [10] “Intel VT une, ” software.intel.com/en- us/vtune, accessed: 2019-5-04. [11] “NVIDIA cuDNN, ” dev eloper .nvidia.com/cudnn, 2019, accessed: 2019- 10-04. [12] “NVIDIA cuBLAS, ” developer .n vidia.com/cublas, accessed: 2019-10-04. [Online]. A vailable: developer .n vidia.com/cublas [13] “ONNX: Open Neural Network Exchange, ” onnx.ai, 2019, accessed: 2019-10-04. [14] “Neural Network Exchange Format (NNEF), ” www .khronos.org/nnef, 2019, accessed: 2019-10-04. [15] “ONNX Model Zoo, ” github.com/onnx/models, 2019, accessed: 2019- 10-04. [16] J. Deng, J. Guo, and S. Zafeiriou, “ArcFace: Additive angular margin loss for deep face recognition, ” CoRR , vol. abs/1801.07698, 2018. [Online]. A vailable: arxiv .org/abs/1801.07698 [17] A. Krizhevsky , I. Sutske ver , and G. E. Hinton, “ImageNet classification with deep conv olutional neural networks, ” in Advances in Neural Information Processing Systems 25 . Curran Associates, Inc., 2012. [18] C. Szegedy , W . Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov , D. Erhan, V . V anhoucke, and A. Rabinovich, “Going deeper with con volutions, ” in 2015 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) . IEEE, Jun. 2015, pp. 1–9. [Online]. A vailable: https://doi.org/10.1109/cvpr .2015.7298594 [19] R. B. Girshick, J. Donahue, T . Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation, ” CoRR , vol. abs/1311.2524, 2013. [Online]. A vailable: arxiv .or g/abs/1311.2524 [20] G. Huang, Z. Liu, and K. Q. W einberger , “Densely connected con volutional networks, ” CoRR , vol. abs/1608.06993, 2016. [Online]. A vailable: arxiv .org/abs/1608.06993 [21] P . W ang, P . Chen, Y . Y uan, D. Liu, Z. Huang, X. Hou, and G. W . Cottrell, “Understanding con volution for semantic segmentation, ” CoRR , vol. abs/1702.08502, 2017. [Online]. A vailable: arxiv .org/abs/1702.08502 [22] E. Barsoum, C. Zhang, C. Canton-Ferrer , and Z. Zhang, “Training deep networks for facial expression recognition with crowd-sourced label distribution, ” CoRR , v ol. abs/1608.01041, 2016. [Online]. A vailable: arxiv .or g/abs/1608.01041 [23] S. Ioffe and C. Szegedy , “Batch normalization: Accelerating deep network training by reducing internal covariate shift, ” CoRR , vol. abs/1502.03167, 2015. [Online]. A vailable: arxiv .org/abs/1502.03167 [24] C. Szegedy , V . V anhoucke, S. Ioffe, J. Shlens, and Z. W ojna, “Rethinking the inception architecture for computer vision, ” CoRR , vol. abs/1512.00567, 2015. [Online]. A vailable: arxiv .org/abs/1512.00567 [25] Y . Lecun, L. Bottou, Y . Bengio, and P . Haffner , “Gradient-based learning applied to document recognition, ” Pr oc. IEEE , vol. 86, no. 11, pp. 2278–2324, 1998. [Online]. A vailable: https://doi.org/10.1109/5.726791 [26] A. G. How ard, M. Zhu, B. Chen, D. Kalenichenko, W . W ang, T . W eyand, M. Andreetto, and H. Adam, “MobileNets: Efficient conv olutional neural networks for mobile vision applications, ” CoRR , vol. abs/1704.04861, 2017. [Online]. A vailable: arxiv .org/abs/1704.04861 [27] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” CoRR , vol. abs/1512.03385, 2015. [Online]. A vailable: arxiv .or g/abs/1512.03385 [28] ——, “Identity mappings in deep residual networks, ” in Computer V ision – ECCV 2016 , B. Leibe, J. Matas, N. Sebe, and M. W elling, Eds. Cham: Springer International Publishing, 2016, pp. 630–645. [29] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An extremely efficient conv olutional neural network for mobile devices, ” CoRR , vol. abs/1707.01083, 2017. [Online]. A vailable: arxiv .org/abs/1707.01083 [30] F . N. Iandola, M. W . Moske wicz, K. Ashraf, S. Han, W . J. Dally , and K. K eutzer, “SqueezeNet: Alexnet-le vel accuracy with 50x fewer parameters and < 1mb model size, ” CoRR , vol. abs/1602.07360, 2016. [Online]. A vailable: arxiv .org/abs/1602.07360 [31] J. Redmon and A. Farhadi, “Y OLO9000: better, faster , stronger, ” CoRR , vol. abs/1612.08242, 2016. [Online]. A vailable: arxiv .org/abs/1612.08242 [32] K. Simonyan and A. Zisserman, “V ery deep con volutional networks for lar ge-scale image recognition, ” CoRR , vol. abs/1409.1556, 2014. [Online]. A vailable: arxiv .org/abs/1409.1556 [33] M. D. Zeiler and R. Fergus, “V isualizing and understanding con volutional networks, ” CoRR , vol. abs/1311.2901, 2013. [Online]. A vailable: arxiv .org/abs/1311.2901 [34] Onnx, “ONNX shape inference, ” https://github.com/onnx/onnx/blob/ master/docs/ShapeInference.md, 2019. [35] Google, “Google benchmark, ” github .com/google/benchmark, 2014. [36] A. Anderson and D. Gregg, “Optimal DNN primitiv e selection with partitioned boolean quadratic programming, ” in Pr oceedings of the 2018 International Symposium on Code Generation and Optimization - CGO 2018 , A CM. ACM Press, 2018, pp. 340–351. [Online]. A vailable: https://doi.org/10.1145/3179541.3168805 [37] T . Ben-Nun and T . Hoefler , “Demystifying parallel and distributed deep learning, ” CSUR , vol. 52, no. 4, pp. 1–43, Aug. 2019. [Online]. A vailable: https://doi.org/10.1145/3320060 [38] “The CUD A Profiling T ools Interface, ” dev eloper .nvidia.com/ cuda- profiling- tools- interface, 2019, accessed: 2019-10-04. [39] “NVIDIA GPU Metrics Reference, ” docs.nvidia.com/cuda/ profiler- users- guide/inde x.html#metrics- reference, accessed: 2019- 7-24. [40] R. Sedgewick and K. W ayne, Algorithms , 4th ed. Addison-W esley Professional, 2011. [41] J. Khan, P . Fultz, A. T amazov , D. Lowell, C. Liu, M. Melesse, M. Nandhimandalam, K. Nasyrov , I. Perminov , T . Shah, V . Filippov , J. Zhang, J. Zhou, B. Natarajan, and M. Daga, “MIOpen: An open source library for deep learning primitiv es, ” 2019. [42] “Mkl-Dnn, ” github .com/intel/mkl- dnn, 2019, accessed: 2019-10-04. [43] Microsoft, “ONNX runtime, ” github .com/microsoft/onnxruntime, 2019. [44] A. Paszke, S. Gross, S. Chintala, and G. Chanan, “Pytorch: T ensors and dynamic neural networks in python with strong gpu acceleration, ” vol. 6, 2017. [45] S. Chintala, “ConvNet Benchmarks, ” github .com/soumith/ con vnet- benchmarks, 2019. [46] Intel, “benchdnn, ” github.com/intel/mkl- dnn/tree/master/tests/benchdnn, 2019. [47] C. Li, A. Dakkak, J. Xiong, W . W ei, L. Xu, and W .-M. Hwu, “XSP: Across-Stack Profiling and Analysis of Machine Learning Models on GPUs. ” IEEE, May 2020, the 34th IEEE International Parallel & Distributed Processing Symposium (IPDPS’20). [48] A. H. Ashouri, W . Killian, J. Cav azos, G. P alermo, and C. Silvano, “ A survey on compiler autotuning using machine learning, ” CSUR , vol. 51, no. 5, pp. 1–42, Sep. 2018. [Online]. A vailable: https: //doi.org/10.1145/3197978 [49] H. V andierendonck, S. Rul, and K. De Bosschere, “The paralax infrastructure, ” in Pr oceedings of the 19th international confer ence on P arallel architectur es and compilation techniques - P A CT ’10 , IEEE. ACM Press, 2010, pp. 389–399. [Online]. A vailable: https://doi.org/10.1145/1854273.1854322 [50] A. Haj-Ali, N. K. Ahmed, T . Willke, S. Shao, K. Asanovic, and I. Stoica, “NeuroV ectorizer: End-to-end vectorization with deep reinforcement learning, ” arXiv pr eprint arXiv:1909.13639 , 2019. [51] O. Solaris, “Oracle solaris studio code analyzer, ” 2019. [52] K. Ng, M. W arren, P . Golde, and A. Hejlsberg, “The Roslyn project, exposing the c# and VB compiler’ s code analysis, ” White paper , Micr osoft , 2011. [53] V . Sarkar , “ Automatic selection of high-order transformations in the IBM XL FOR TRAN compilers, ” IBM J. Res. & Dev . , vol. 41, no. 3, pp. 233– 264, May 1997. [Online]. A vailable: https://doi.org/10.1147/rd.413.0233
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment