SiEVE: Semantically Encoded Video Analytics on Edge and Cloud
Recent advances in computer vision and neural networks have made it possible for more surveillance videos to be automatically searched and analyzed by algorithms rather than humans. This happened in parallel with advances in edge computing where videos are analyzed over hierarchical clusters that contain edge devices, close to the video source. However, the current video analysis pipeline has several disadvantages when dealing with such advances. For example, video encoders have been designed for a long time to please human viewers and be agnostic of the downstream analysis task (e.g., object detection). Moreover, most of the video analytics systems leverage 2-tier architecture where the encoded video is sent to either a remote cloud or a private edge server but does not efficiently leverage both of them. In response to these advances, we present SIEVE, a 3-tier video analytics system to reduce the latency and increase the throughput of analytics over video streams. In SIEVE, we present a novel technique to detect objects in compressed video streams. We refer to this technique as semantic video encoding because it allows video encoders to be aware of the semantics of the downstream task (e.g., object detection). Our results show that by leveraging semantic video encoding, we achieve close to 100% object detection accuracy with decompressing only 3.5% of the video frames which results in more than 100x speedup compared to classical approaches that decompress every video frame.
💡 Research Summary
The paper introduces SiEVE, a three‑tier video analytics framework that tightly couples video encoding with downstream neural‑network (NN) inference to dramatically reduce the computational and bandwidth costs of object detection on surveillance streams. Traditional video encoders are designed solely for human viewing and remain agnostic to the semantics of later analysis tasks. Consequently, existing analytics pipelines either send fully decoded streams to a powerful cloud or perform limited processing on an edge server, but they still must decode every frame, incurring high latency and network load.
SiEVE’s novelty lies in “semantic video encoding.” By tuning two encoder parameters—Group‑of‑Pictures (GOP) size and the scenecut threshold—SiEVE forces the encoder to emit an I‑frame (key‑frame) only when a meaningful semantic change occurs, i.e., when the set of object classes in the scene changes. The remaining P‑frames are assumed to contain the same object labels as the preceding I‑frame and are therefore never decoded for the purpose of object detection. The I‑frame selection is performed by an “I‑frame seeker” that scans only the video metadata; no full‑frame decoding is required. In practice, this reduces the number of frames that need to be decompressed to roughly 3.5 % of the total.
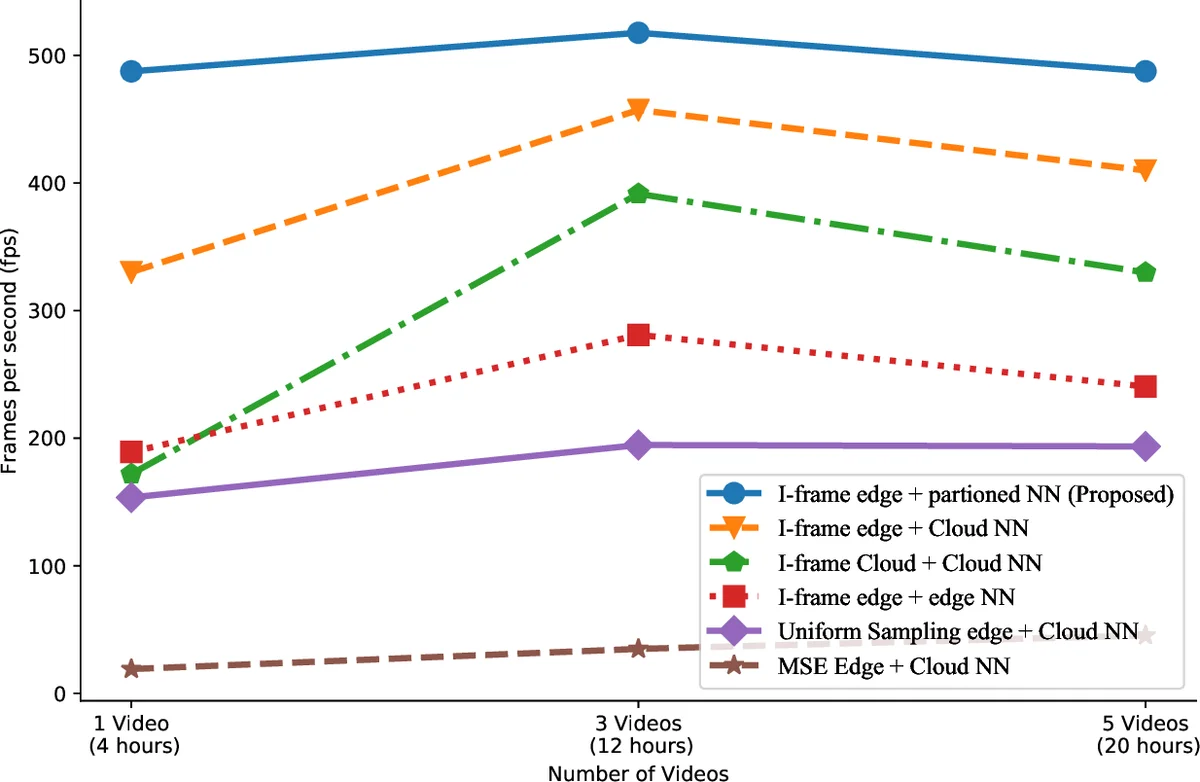
The system architecture consists of three layers: (1) cameras equipped with a controllable “semantic video encoder,” (2) an edge server that receives the encoded stream, extracts I‑frames, briefly decodes them (as JPEG‑like images), and runs a portion of the object‑detection NN, and (3) a cloud server that completes the remaining NN layers and stores the final object‑label results. The edge‑cloud NN partitioning is configurable: all layers may run on the edge for low‑latency scenarios, or a split can be made to leverage cloud compute for heavier layers. The edge compute engine processes I‑frames in a data‑flow pipeline, buffering them in an event queue before dispatch.
Parameter tuning is performed offline per camera. Historical, manually labeled video segments are re‑encoded with a grid of GOP sizes (e.g., 100, 250, 1000, 5000) and scenecut thresholds (e.g., 20, 40, 100, 200, 250). For each configuration, two metrics are measured: (a) event‑detection accuracy (whether an I‑frame appears at the start of each semantic event) and (b) filtering rate (fraction of frames kept as I‑frames). The configuration that maximizes the F1‑score (balancing accuracy and compression) is stored in a lookup table and used at runtime. This per‑camera tuning accounts for differences in camera height, field of view, and object size, ensuring that the motion‑sensitivity threshold matches the specific deployment.
Evaluation on a dataset of 2.16 million frames (≈12 GB) spanning multiple scenes, object types, and geographic locations shows compelling results. SiEVE achieves near‑perfect object‑detection accuracy (within 1‑5 % loss compared to frame‑by‑frame ground truth) while processing 10× more frames per second than image‑similarity baselines such as NoScope, which rely on full‑frame decoding and pixel‑wise similarity measures (e.g., MSE, SIFT). Bandwidth consumption drops from 12.26 GB to 1.68 GB—a 7× reduction—because only the sparse I‑frames are transmitted to the cloud. Overall, the system delivers more than 100× speedup relative to classical pipelines that decompress every frame, primarily by eliminating the costly bit‑stream decoding, motion compensation, and inverse Fourier transform steps for the majority of frames.
The authors position SiEVE against related work in three categories: video‑aspect optimizations (resolution, bitrate, frame‑rate selection), NN‑aspect optimizations (pruning, quantization), and hardware accelerators (TPU, GPUs). While prior works have tuned video parameters for NN inference, none have explored sub‑1 fps effective frame rates or leveraged encoder‑level motion estimation to generate semantics‑aware key‑frames. SiEVE thus fills a gap by making the encoder “aware” of downstream object‑label changes.
Limitations are acknowledged. The approach requires encoders whose GOP size and scenecut threshold can be externally configured, which may not be available on all commercial cameras. Offline tuning must be repeated when environmental conditions (lighting, camera angle, object scale) change, potentially incurring operational overhead. The current implementation focuses solely on object detection; extending to more complex tasks such as action recognition, multi‑object tracking, or person re‑identification would require additional mechanisms. Moreover, treating all P‑frames as “no change” could miss subtle motions (e.g., small gestures) that are relevant for certain applications. Finally, the experimental evaluation, while diverse, is still limited in scale and does not cover extreme network conditions or large‑scale deployments.
In conclusion, SiEVE demonstrates that integrating semantic awareness into video encoding can dramatically cut both compute and communication costs for edge‑cloud video analytics. By emitting key‑frames only when object labels change, the system sidesteps the need to decode the overwhelming majority of frames, achieving orders‑of‑magnitude speedups and bandwidth savings without sacrificing detection accuracy. The concept of semantic video encoding opens a promising research direction for future multi‑task, multi‑modal streaming systems, where encoders and analytics pipelines co‑evolve to meet the stringent latency and resource constraints of real‑time surveillance.
Comments & Academic Discussion
Loading comments...
Leave a Comment