Towards Understanding Cooperative Multi-Agent Q-Learning with Value Factorization
💡 Research Summary
This paper provides a rigorous theoretical investigation of value‑factorization methods that have become central to scaling cooperative multi‑agent reinforcement learning (MARL). The authors first introduce a Decentralized Rich‑Observation Markov Decision Process (Dec‑ROMDP), which augments the classic Dec‑POMDP with observations that uniquely identify the underlying latent state. This setting enables the use of reactive function classes that depend only on the current observation, simplifying analysis while retaining the essential challenges of cooperative MARL such as credit assignment, non‑stationarity, and scalability.
The core contribution is the formulation of Factorized Multi‑Agent Fitted Q‑Iteration (FMA‑FQI), a direct generalization of the well‑studied single‑agent Fitted Q‑Iteration (FQI) to the multi‑agent domain. In FMA‑FQI, a dataset of tuples (observation, joint action, reward, next observation) is repeatedly used to minimize the empirical Bellman error of a joint Q‑function Q_tot, which is constrained to belong to a factorized function class Q_FMA. The factorization ties Q_tot to a set of individual value functions Q_i, allowing decentralized execution by greedy selection on each Q_i. This framework captures the essence of the CTDE (centralized training with decentralized execution) paradigm used by most deep MARL algorithms.
Using FMA‑FQI, the paper analyzes two widely adopted factorization schemes.
-
Linear value factorization (VDN) – Here Q_tot is defined as the simple sum of individual Q_i. The authors show that the Bellman‑error minimization reduces to a weighted linear least‑squares problem with a closed‑form solution. This reveals that linear factorization implicitly implements a powerful counterfactual credit‑assignment mechanism: each Q_i learns to estimate its marginal contribution to the global reward without any explicit baseline. However, because the linear class is highly restrictive, the authors prove that in general there may be no fixed‑point solution and the algorithm can diverge, especially when the training data are off‑policy. They further demonstrate that on‑policy data collection guarantees the existence of a fixed point and provides local convergence guarantees near the optimal Q‑functions, thereby offering a practical remedy for instability.
-
IGM‑based factorization (QPLEX, QTRAN) – In this case Q_tot is expressed as a monotonic (or otherwise IGM‑compatible) function f of the individual Q_i. The IGM (Individual‑Global‑Max) principle enforces that the joint greedy action coincides with the collection of individual greedy actions. Within the FMA‑FQI framework, the authors prove that if the function class is rich enough to represent all IGM‑compatible joint value functions, the iteration converges globally to the optimal Q‑functions and the resulting policies are optimal. This establishes a strong theoretical foundation for recent IGM‑focused architectures, showing that they overcome the representational limitations of linear factorization while preserving the CTDE consistency.
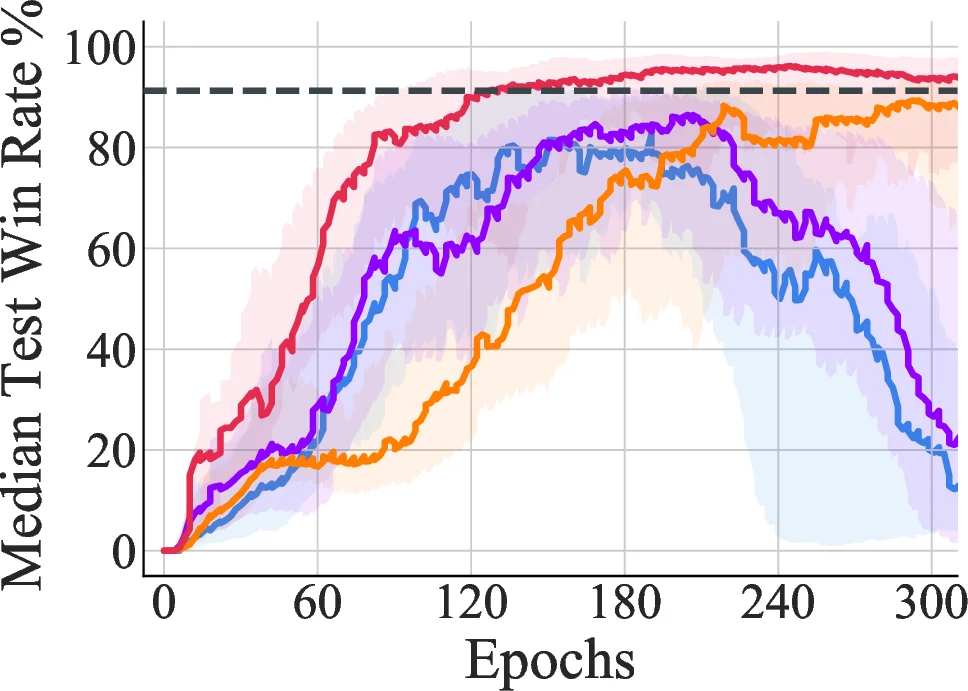
To bridge theory and practice, the paper conducts extensive experiments on didactic cooperative tasks and on the StarCraft II unit micromanagement benchmark. Empirical results confirm the theoretical predictions: linear factorization (VDN) can be unstable on complex tasks but benefits markedly from on‑policy data or additional regularization; IGM‑based methods (QPLEX, QTRAN) exhibit robust convergence and achieve state‑of‑the‑art performance on the challenging StarCraft scenarios.
In summary, the work introduces a unifying analytical framework (FMA‑FQI) for cooperative MARL with value factorization, elucidates the implicit credit‑assignment properties of linear decomposition, identifies conditions under which it may diverge, and proves global optimality for IGM‑compatible factorizations. These insights provide clear guidance for designing future MARL algorithms, selecting appropriate factorization structures, and choosing data collection strategies to ensure stable and efficient learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment