Group testing with nested pools
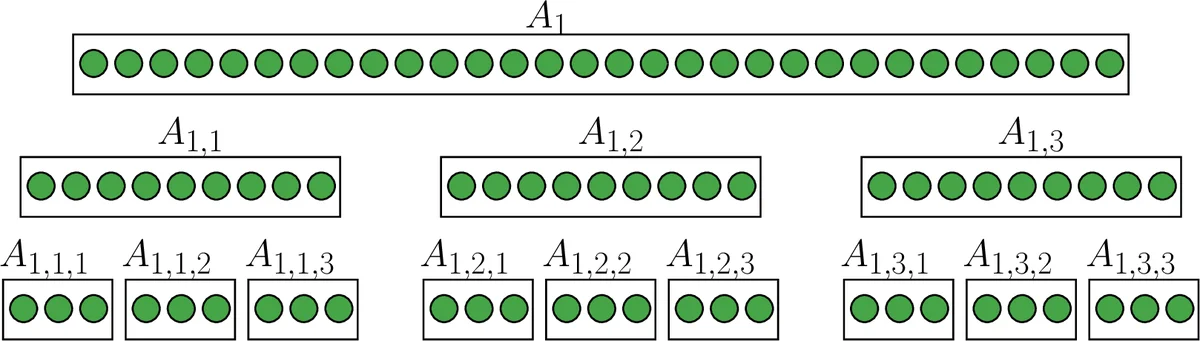
In order to identify the infected individuals of a population, their samples are divided in equally sized groups called pools and a single laboratory test is applied to each pool. Individuals whose samples belong to pools that test negative are declared healthy, while each pool that tests positive is divided into smaller, equally sized pools which are tested in the next stage. In the $(k+1)$-th stage all remaining samples are tested. If $p<1-3^{-1/3}$, we minimize the expected number of tests per individual as a function of the number $k+1$ of stages, and of the pool sizes in the first $k$ stages. We show that for each $p\in (0, 1-3^{-1/3})$ the optimal choice is one of four possible schemes, which are explicitly described. We conjecture that for each $p$, the optimal choice is one of the two sequences of pool sizes $(3^k\text{ or }3^{k-1}4,3^{k-1},\dots,3^2,3 )$, with a precise description of the range of $p$’s where each is optimal. The conjecture is supported by overwhelming numerical evidence for $p>2^{-51}$. We also show that the cost of the best among the schemes $(3^k,\dots,3)$ is of order $O\big(p\log(1/p)\big)$, comparable to the information theoretical lower bound $p\log_2(1/p)+(1-p)\log_2(1/(1-p))$, the entropy of a Bernoulli$(p)$ random variable.
💡 Research Summary
This paper presents a rigorous mathematical analysis of optimal multi-stage, nested pool group testing strategies. The core problem is to identify infected individuals within a population while minimizing the expected number of tests per person. The model extends Dorfman’s classic two-stage method by recursively subdividing pools that test positive into smaller, equally-sized pools for subsequent testing stages, culminating in individual testing of all remaining samples in the final (k+1)-th stage.
The authors assume a known infection probability p and independent Bernoulli statuses for individuals. Given a strategy defined by the number of pooled stages k and a sequence of pool sizes m = (m1, m2, …, mk) where each m_j is a multiple of m_{j+1}, they derive an exact formula for the expected cost (tests per individual) D_k(m, p). This cost function incorporates the initial pool setup cost, the expected cost of intermediate pool tests, and the cost of final individual tests.
The primary objective is to find the strategy (k, m) that minimizes D_k(m, p) for a given p. The main results are as follows: First, for p ≥ 1 - 3^{-1/3} ≈ 0.3066, individual testing is optimal. Second, for 0 < p < 1 - 3^{-1/3}, Proposition 3.1 proves that the optimal strategy must belong to one of four explicitly described types. These optimal types share a structural pattern: the final pool size (m_k) is either 2 or 3; each intermediate pool size is exactly three times the size of the pool in the next stage (m_j = 3 * m_{j+1} for j=2,…,k-1); and the first pool size (m1) is either three or four times the second pool size (m2). The four types are distinguished by the choices of (m_k, m1/m2).
Third, based on extensive numerical evidence for p > 2^{-51}, the authors conjecture (Conjecture 3.1) that two of these four types can be discarded, and the truly optimal strategy is either the sequence m_33 = (3^k, 3^{k-1}, …, 3^2, 3) or m_34 = (3^{k-1}*4, 3^{k-1}, …, 3^2, 3). They provide precise formulas (Proposition 3.2) to determine the optimal number of stages k for a given p within these schemes.
A significant theoretical contribution is Theorem 5.1, which shows that the cost of the best strategy among the m_33 schemes scales as O(p log(1/p)). This order matches the information-theoretic lower bound given by the entropy of a Bernoulli(p) variable, indicating the strategy’s fundamental efficiency. While the constant factor (3/log 3) is slightly worse than that of the best-known binary splitting algorithms (1/log 2), the nested pool strategy offers a practical advantage: it requires only a deterministic, predictable number of stages (approximately log_3(1/p)) per initial pool, unlike methods where the number of stages can scale with the random number of infected individuals.
The paper thoroughly contextualizes its work within the broader group testing literature, discussing adaptive vs. non-adaptive methods, binary splitting, and practical considerations like test errors and heterogeneous populations. It also mentions the motivation from COVID-19 testing. The analysis provides a clear framework for optimizing nested pool designs and strong evidence for simple, near-optimal rules governing pool size sequences, offering valuable guidance for practical implementation in large-scale testing scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment