Learning to Dress 3D People in Generative Clothing
Three-dimensional human body models are widely used in the analysis of human pose and motion. Existing models, however, are learned from minimally-clothed 3D scans and thus do not generalize to the complexity of dressed people in common images and videos. Additionally, current models lack the expressive power needed to represent the complex non-linear geometry of pose-dependent clothing shapes. To address this, we learn a generative 3D mesh model of clothed people from 3D scans with varying pose and clothing. Specifically, we train a conditional Mesh-VAE-GAN to learn the clothing deformation from the SMPL body model, making clothing an additional term in SMPL. Our model is conditioned on both pose and clothing type, giving the ability to draw samples of clothing to dress different body shapes in a variety of styles and poses. To preserve wrinkle detail, our Mesh-VAE-GAN extends patchwise discriminators to 3D meshes. Our model, named CAPE, represents global shape and fine local structure, effectively extending the SMPL body model to clothing. To our knowledge, this is the first generative model that directly dresses 3D human body meshes and generalizes to different poses. The model, code and data are available for research purposes at https://cape.is.tue.mpg.de.
💡 Research Summary
The paper introduces CAPE (Clothed Auto Person Encoding), a probabilistic generative model that dresses the widely used SMPL body model with realistic clothing. Existing SMPL‑based models are trained on minimally‑clothed scans and therefore cannot capture the complex, pose‑dependent geometry of real garments. To overcome this, the authors capture a new 4D dataset consisting of over 80 000 frames from 11 subjects wearing various clothing types (e.g., shorts, long pants) while performing diverse motion sequences. For each frame they obtain a minimally‑clothed SMPL registration and a fully clothed scan, compute per‑vertex displacements, and treat these displacements as a graph that inherits SMPL’s topology.
CAPE models the clothing displacement as an additive layer on top of the SMPL template. The displacement graph is generated by a conditional Mesh‑VAE‑GAN. An encoder built from graph convolutional layers maps the input displacement graph to a low‑dimensional latent code z, while a decoder takes z together with pose parameters θ (23 joint rotations) and a clothing‑type conditioning vector c to reconstruct the displacement graph. The VAE loss (reconstruction + KL divergence) ensures a smooth latent space, and a GAN loss with a novel patch‑wise discriminator encourages realistic high‑frequency details such as wrinkles. The discriminator operates on small mesh patches (sub‑graphs), allowing it to focus on local realism rather than being dominated by global shape.
Because the generator is conditioned on pose and clothing type, a single latent code can be sampled across many poses, producing pose‑dependent deformations (e.g., wrinkles that appear when the leg bends). Conversely, sampling different z values for the same pose yields diverse garment styles within the same clothing category, reflecting the multimodal nature of clothing geometry. This addresses the deterministic limitation of prior regression‑based clothing models.
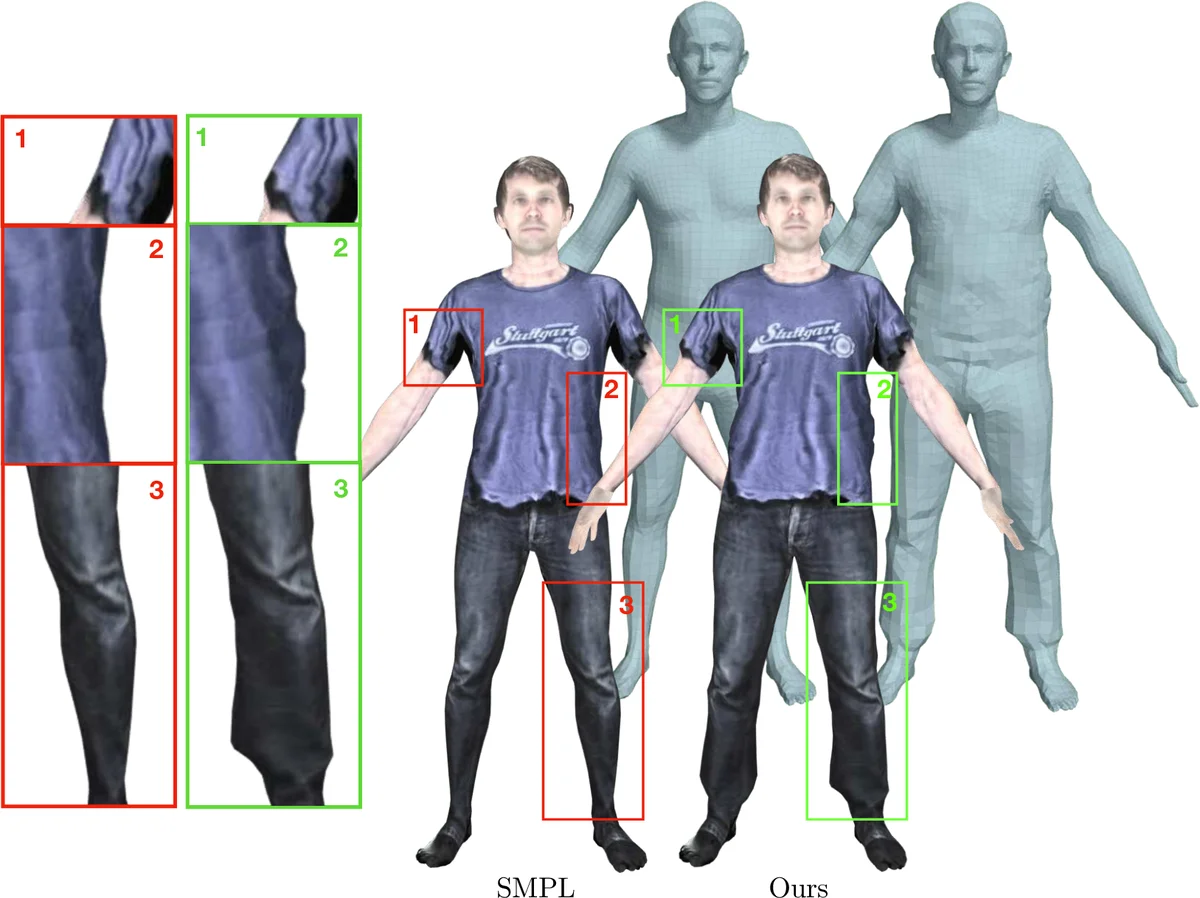
The authors integrate CAPE into SMPLify, an image‑based 3D human fitting pipeline, and demonstrate that the “clothed‑SMPL” improves reconstruction quality both quantitatively (lower vertex error) and qualitatively (more accurate silhouettes and wrinkle patterns). They also show that CAPE can generate arbitrary clothed meshes by sampling z, θ, c, making it a plug‑and‑play component for applications such as synthetic data generation, pose estimation priors, and analysis‑by‑synthesis.
Key contributions are: (1) a probabilistic formulation of clothing modeling as a displacement layer; (2) a conditional Mesh‑VAE‑GAN that captures both global garment shape and fine wrinkle detail; (3) a patch‑wise mesh discriminator that effectively preserves high‑frequency geometry; (4) a new 4D scan dataset of clothed humans; and (5) demonstration of a seamless extension of SMPL for downstream tasks. Limitations include the reliance on SMPL’s topology (making it less suitable for loose or multi‑layer garments) and the absence of explicit physical simulation, which could be addressed in future work by incorporating multi‑topology support and physics‑based refinement.
Comments & Academic Discussion
Loading comments...
Leave a Comment