T-Net: Nested encoder-decoder architecture for the main vessel segmentation in coronary angiography
In this paper, we proposed T-Net containing a small encoder-decoder inside the encoder-decoder structure (EDiED). T-Net overcomes the limitation that U-Net can only have a single set of the concatenate layer between encoder and decoder block. To be m…
Authors: Tae Joon Jun, Jihoon Kweon, Young-Hak Kim
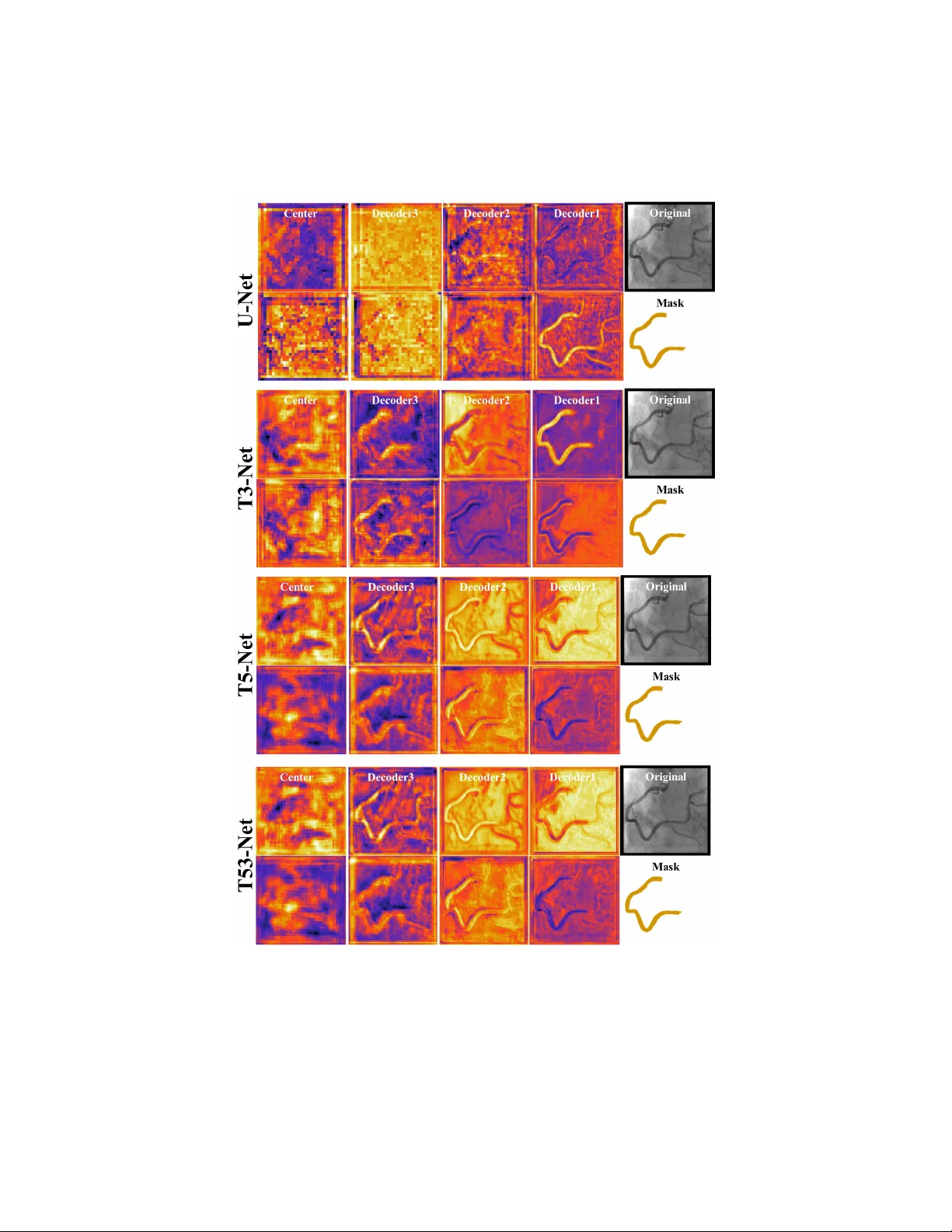
T-Net: Enco der-Deco der in Enco der-Deco der arc hitecture for the main v essel segmen tation in coronary angiograph y T ae Jo on Jun a , Jiho on Kw eon b , Y oung-Hak Kim b , Daey oung Kim a, ∗ a Scho ol of Computing, Kor e a A dvanc e d Institute of Scienc e and T e chnology, 34141 Daeje on, R epublic of Kor e a b Division of Car diolo gy, University of Ulsan Col le ge of Me dicine, Asan Me dic al Center, 05505 Se oul, R epublic of Kor e a Abstract In this pap er, we prop osed T-Net containing a small enco der-decoder inside the enco der-decoder structure (EDiED). T-Net o v ercomes the limitation that U-Net can only hav e a single set of the concatenate lay er betw een enco der and deco der blo c k. T o b e more precise, the U-Net symmetrically forms the concatenate la yers, so the lo w-lev el feature of the encoder is connected to the latter part of the deco der, and the high-lev el feature is connected to the b eginning of the deco der. T-Net arranges the p o oling and up-sampling appropriately during the enco der pro cess, and likewise during the deco ding pro cess s o that feature-maps of v arious sizes are obtained in a single blo ck. As a result, all features from the lo w-level to the high-level extracted from the enco der are delivered from the beginning of the deco der to predict a more accurate mask. W e ev aluated T-Net for the problem of segmen ting three main v essels in coronary angiograph y images. The exp erimen t consisted of a comparison of U-Net and T-Nets under the same conditions, and an optimized T-Net for the main vessel segmentation. As a result, T-Net recorded a Dice Similarit y Co efficien t score ( DSC ) of 0.815, 0.095 higher than that of U-Net, and the optimized T-Net recorded a DSC of 0.890 which w as 0.170 higher than that of U-Net. In addition, we visualized the ∗ Corresponding author Email addr ess: kimd@kaist.ac.kr (Daey oung Kim) Pr eprint submitte d to Neur al Networks May 21, 2020 w eight activ ation of the conv olutional la yer of T-Net and U-Net to sho w that T- Net actually predicts the mask from earlier deco ders. Therefore, we expect that T-Net can b e effectiv ely applied to other similar medical image segmen tation problems. Keywor ds: Con volutional neural netw ork; Main v essel segmentation; Coronary angiograph y; Enco der and deco der; 1. In tro duction Seman tic segmen tation is a t ypical problem where deep learning tec hnology is activ ely applied. Compared with classification, seman tic segmen tation has the adv an tage of visualizing the characteristics of an image b ecause it can display a concrete region with classes of ob ject. Ho wev er, while labeling of classification is word or n umber level, lab eling of semantic segmen tation requires muc h time and effort for lab eling b ecause it needs to extract sp ecific area from the image. Therefore, the most active area of semantic segmentation problem is medical image analysis. This is b ecause the effect obtained by marking sp ecific regions in the medical image is large ev en if time and effort are inv olv ed. Unlik e general images, which ha v e large n umber of ob jects to b e segmen ted and their shap e v ary , medical images are captured with a sp ecific purp ose, so the num b er of classes for segmentation is relatively small and the image shap e is fixed. There- fore, v arious metho ds for semantic segmen tation is prop osed to solve sp ecific medical image segmen tation problems [1]. Curren tly , the most p opular metho d for medical image semantic segmenta- tion is the fully conv olutional neural net work (CNN) structure based on U-Net [2]. The U-Net consists of an enco der part extracting a feature from the original image and a deco der part restoring the feature to a mask image. How ev er, since the size of the feature map contin uously decreases during the enco der pro cess, noise is generated while restoring the extracted features in the deco der pro cess. Therefore, to minimize the loss of the original image, U-Net provides a con- catenate lay er that directly connects the enco der and deco der. Ho wev er, due to 2 the structural restriction of U-Net, there is only one set of con volution blocks matc hing the feature-map of the same size in the enco der and deco der, whic h has a limitation in generating a precise mask. More sp ecifically , the high-lev el feature extracted from the latter enco der is connected to the beginning of the deco der, and the lo w-level feature is connected to the deco der near the predic- tion lay er. P articularly , this limitation is fatal in the medical image problem where the n umber of classes of the ob ject to b e segmen ted is small, but the re- gion of the mask has to b e precisely segmented. An example of such a medical image problem is the segmen ting main vessels from coronary angiography . In coronary angiography , the num b er of main vessels to b e segmen ted is relatively small, but masks should b e generated in the same form as the main v essel of the original image. In other words, the main vessel is identified among the v arious blo od vessels of similar shap e in the image, and the predicted region should b e similar to the actual vessel shap e in the original image. Therefore, from the lo w-level feature indicating the shap e of v essels to the high-level feature sp ec- ifying the main v essel, all lev els of features should be considered in the mask restoring pro cess. In this pap er, we prop ose a T-Net that allows v arious sizes of feature-maps b et w een enco der and decoder, resulting in sophisticated seman tic segmenta- tion. The core concept of T-Net is enco der-decoder in enco der-deco der (EDiED) structure. Through EDiED structure, the size of the feature-map is increased by up-sampling in the enco ding pro cess, while the size of the feature-map is reduced b y p o oling in the decoding pro cess. Thus, there are multiple sizes of feature maps in the same blo c k, which allows for a more versatile com bination when constructing the concatenated lay ers of the enco der-deco der. In other w ords, precise segmentation is p ossible from the b eginning of the deco der by trans- mitting all lev els of features extracted from ev ery enco der blo ck. W e ev aluated T-Net for the problem of segmenting three t yp es of main vessels in coronary an- giograph y . The three main vessels are the left an terior descending artery (LAD), the left circumflex artery (LCX), and the right coronary artery (RCA). W e first compare the p erformance of U-Net and T-Net under the same conditions and vi- 3 sualize the intermediate con volutional la yers to see how the actual weigh t v aries from original to mask image. Then, we fine-tuned the optimized T-Net struc- ture to sho w the b est segmentation performance. As a result, T-Net sho wed 0.095 higher Dice Similarity Co efficient score ( DSC ), 5.71% higher sensitivit y , 12.22% higher precision than those of U-Net in the same exp eriment condition. The optimized T-Net sho wed an a verage of 0.890 DSC , 88.32% sensitivity and 90.50% precision for the three types of main vessels segmen tation from coro- nary angiography . Our T-Net is also exp ected to be effectively applied to other medical image segmen tation problems that require precise segmentation. The rest of this Chapter is structured as follo w ed. In Section 2, w e review the literature for v essel segmentation in coronary angiography and also briefly review CNN-based studies for seman tic segmentation. Section 3 describes the basic structure of T-Net and sho ws examples of v arious mo dels that can be de- riv ed from T-Net. Section 4 describ es the optimal T-Net structure for the main v essel segmentation in coronary angiograph y . Section 5 ev aluates the compari- son of T-Net and U-Net and the p erformance of optimized T-Net. Finally , w e conclude this study in Section 6 and discusses future plans. 2. Related W ork 2.1. Main vessel se gmentation in c or onary angio gr aphy The W orld Health Organization (WHO) has announced that cardiov ascular diseases (CVDs) are the leading cause of death in to da y’s world [3]. More than 17 million people died of CVDs in 2016 which is an ab out 31% of all deaths, and more than 75% of these deaths o ccurred in low-income and middle-income coun tries [3]. Among CVDs, coronary artery disease (CAD) is the most com- mon cause of death [4][5]. In 2015, CAD affected 110 million p eople, resulting in 8.9 million deaths and 15.6% of all deaths, making it the most common cause of death w orldwide [4][5]. The primary imaging method to observ e CAD is X-ray angiograph y , often called coronary angiography . Esp ecially in coronary angiog- raph y , it is imp ortan t to identify the main blo od vessels correctly . How ever, the 4 iden tification of main v essels curren tly depends on the manual segmen tation from the radiologist, requiring a lot of time and effort. Moreov er, it is difficult to identify the v essel clearly b ecause of low contrast, non-uniform illumination, and low signal to noise ratios (SNR) of X-ray angiography [6]. Therefore, stud- ies on automated vessel segmentation are aimed at reducing time and cost b y helping relev an t exp erts. Among them, the main vessel segmen tation is a diffi- cult problem b ecause it do es not identify the whole blo o d v essels shown in the image but only the main blo o d vessel is segmented. Figure 1 shows the LAD, LCX, and R CA vessels observed in coronary angiography . Figure 1: Three main vessels with ov erlapping mask images There are sev eral studies on blo od vessel segmentation in coronary angiog- raph y . Near-Esfahani prop osed a CNN-based method to classify whole blo o d v essels in X-ray angiography [6]. Near-Esfahani used CNN to classify the cen- tral pixel of eac h patc h after dividing a single image into sev eral small patches. A total of 44 coronary angiography images of 512 x 512 size w ere spliced in to 26 train-sets and 18 test-sets and the result w as 93.5% segmentation accuracy . 5 F elfelian prop osed a metho d of extracting the ROI of the coronary arteries with a Hessian filter and segmen ting the bloo d v essel by ov erlapping the R OI with the flux flow measuremen t result [7]. As a result, the segmen tation accuracy w as about 96% for a total of 50 x-ray angiography images. W ang prop osed a metho d of v essel segmentation by com bining Hessian matrix m ulti-scale filtering and region growing algorithm [8]. Similarly , M’hiri prop osed a vessel segmenta- tion method that combines Hessian-based vesselness information with a random w alk formulation [9]. Compared with existing metho ds suc h as F rangi’s filter and active con tour metho d for 9 angiography images, the A UC was 0.95. In addition, there are man y other vessel segmentation approaches, but as ab ov e, they are not suitable for the main vessel segmentation problem b ecause they segmen t the entire vessel in X-ray angiography [10][11][12]. In other words, a mac hine learning based method is needed to extract the c haracteristics and p o- sition of the main vessel in order to segment only the main v essel. Recently , Jo prop osed the metho d of segmenting the LAD in coronary angiography , which is the most consistent with our study [13]. Jo automatically selects the appropri- ate filter through the selective feature mapping (SFM) metho d to extract the candidate area. Then, LAD vessel segmentation is p erformed in the candidate area. The CNN mo del for segmen tation is typical U-Net and is compared to U-Nets with backbone CNN using V GGNet [14] or DenseNet [15]. In a total of 1,987 angiography images, 200 images were used as train-set and 1,787 images w ere used as test-set, and the highest result show ed an av erage of 0.676 DSC . Although Jo’s approach utilizes U-Net and presents a nov el SFM metho d, the segmen tation p erformance is still lo w. 2.2. CNN for semantic se gmentation CNN for seman tic segmen tation has b een dev elop ed in t w o ma jor directions. One is the direction of the semantic segmen tation of ob jects in a general image. Generally , it is ev aluated in P ASCAL VOC [16] and MS COCO [17] dataset, where n umbers of classes to segment are 20 and 91 resp ectiv ely , excluding the bac kground. Therefore, the feature extraction p erformance of the enco der is of 6 primary imp ortance in this direction. The first proposed CNN-based metho d is the fully conv olutional netw ork (FCN) prop osed b y Long [18]. FCN is the mo del that c hanges the fully connected la yer of the well-kno wn classification models suc h as AlexNet [19], V GGNet [14], and Go ogLeNet [20] to a 1x1 con v olution and up-sampling the final prediction. Ho w ever, there is a limitation that the pro cess of restoring the FCN from a v ery small feature-map to the original mask at a single step is not accurate. Therefore, transposed con v olution is prop osed to o vercome the limitation of FCN [21]. Meanwhile, v arious studies for impro ving the p erformance in the P ASCAL VOC dataset hav e b een prop osed [22] [23] [24] [25]. The recently prop osed DeepLabv3+ [26] tak es into account the encoder- deco der architecture in previous version of DeepLab v3 [27]. Another direction is to p erform seman tic segmentation in medical images. In fact, creating a mask of seman tic segmen tation is v ery costly because it is almost imp ossible to segment all ob jects that app ear in a wide v ariet y of generic images. This is why the num b er of classes in ImageNet [28], a dataset for classification, is 1000, while P ASCAL VOC and MS COCO are less than 100. How ever, since medical image segmentation require relatively few er classes (tumor, vessel, organs, etc.) in typical types of images (MRI, CT, X-ra y , etc.), higher performance can b e obtained with a fewer num b er of images. In addition, b ecause segmentation provides explainable information on medical judgmen t than simply classifying images, studies on medical image segmentation are very activ e in a wide range of medical fields [1] [29]. The most p opular CNN based mo del in medical segmentation is U-Net, whic h is also called enco der-decoder arc hitecture. A detailed description of U-Net follows in the next section. Also, there are v ariations of U-Net for medical image segmentation suc h as 3D U-Net [30], V-Net [31], H-DenseUNet [32], etc. Ho wev er, there has b een no study related to transmitting v arious lev els of features extracted from enco ders by p erforming multiple p o oling and up-sampling in a single blo c k to generate multi- sized feature maps. 7 3. T-Net: enco der-decoder in enco der-deco der architecture Before describing T-Net in detail, w e introduce the basic structure of U-Net and explain the structural limitation. U-Net is a symmetric structure, as its name implies, an enco der that extracts a feature and a deco der that restores a feature to a mask. The difference with FCN is that as the depth of the enco der increases, the num b er of filters increases as the general classification CNN mo del, and con versely , the n umber of filters decreas es as the deco der reac hes the prediction lay er. Figure 2 shows the basic structure of U-Net. Figure 2: Basic structure of U-Net There are v arious deformation mo dels of U-Net at presen t, but the basic structure do es not deviate muc h from Figure 2. That is, the enco der gradually reduces the size of the feature-map in order to extract the high-level features, while in the deco der, the size of the feature-map gradually increases to matc h the size of the mask. Unlike the classification in which the extracted high-level features are directly connected to the prediction lay er, the segmentation requires 8 a process of restoring to the prediction la yer, which creates a noisy b oundary mask different from the shap e of the ob ject in the original image. Therefore, in U-Net, there is a concatenate la yer that connects feature-maps of the same size in enco der and deco der. Supp ose b oth the width and heigh t of input image are h . Let E i b e the i -th blo c k of the encoder, and halv e the width and height of the feature-map to w ards E n . Assume E 1 b e a direct con volutional connection to the input image to ha v e a feature-map of size h . Likewise, the i -th block of the deco der is called D i , and for con v enience, let a blo ck near the prediction lay er b e D 1 . And D i doubles the width and height of the feature-map by up-sampling in the direction of D 1 . Therefore, E i and D i of U-Net ha ve feature-map of the following sizes. S(E i ) = S(D i ) = h 2 i-1 (1) Because the concatenate lay er connects the same sized con v oluted la y er, the con- catenated lay er in U-Net is only one-to-one matching of E i and D i . Ho wev er, as the depth of the enco der b ecomes deep er, the high-level feature of the orig- inal image is extracted, whereas the corresp onding deco der blo c k just started restoring. On the other hand, the earliest blo c k of the enco der extracts the lo w-level feature, but the matching deco der blo c k connected is the blo c k closest to the prediction. In other words, U-Net connects low-lev el features close to the prediction la yer and connects high-level features far to the prediction la yer. This is an inevitable limit for a single set of enco der-decoder architecture. 3.1. Enc o der-de c o der in enc o der-de c o der (EDiED) In order to o v ercome the structural simplicit y of U-Net, we prop ose the enco der-decoder in enco der-decoder (EDiED) architecture. The purp ose of EDiED is to ensure that the v arious levels of features extracted from the encoder are deliv ered during the training of the deco der. T o do this, the unmatched E i and D j need to b e concatenated to eac h other. The Figure 3 shows the simplest T-Net, whic h is named T3-Net. 9 Figure 3: Structure of T3-Net with PPU and UUP W e named it T3-Net b ecause there are three p o oling and up-sampling in the single con volution blo c k. Likewise, if there are 5 p o oling and up-sampling, it is T5-Net and if there are 5 times in enco der and 3 times in deco der, it is T53-Net. Dep ending on the order of p o oling and up-sampling, the same T3-Net can be in v arious forms. W e name the block in the order of P (po oling) and U (up-sampling) app earing in the blo c k. That is, if E i of T3-Net is comp osed of p o oling, up-sampling, and p o oling, it is called PUP i , and in the case of D i , it is called UPU i . As can b e inferred from EDiED, PUP and UPU can b e regarded as small-scale enco der-deco ders existing in enco der and deco der, resp ectiv ely . Like U-Net, E i reduces the size of the final feature-map in half, so the sum of n ( P ) and n ( U ) must b e o dd, and n ( P ) is one more than n ( U ). Lik ewise, D i needs to double the size of the feature-map, so n ( U ) is one more 10 than n ( P ). Therefore, E i that can exist in T3-Net are PUP i and PPU i , and D i are UPU i and UUP i . Assuming that P and U are general stride 2 p o oling and up-sampling, the feature-map sizes of E i and D i that can exist in T3-Net are as follo ws. S(E i ) = S(PPU i ) = { h 2 i-1 , h 2 i , h 2 i+1 } S(E i ) = S(PUP i ) = { h 2 i-1 , h 2 i } S(D i ) = S(UUP i ) = { h 2 i-3 , h 2 i-2 , h 2 i-1 } S(D i ) = S(UPU i ) = { h 2 i-2 , h 2 i-1 } (2) F rom equation 2, T3-Net with E i and D i with PPU i and UUP i resp ectiv ely has E i-1 , E i , E i+1 and D i+1 , D i+2 and D i+3 blo c ks with feature-map size h /2 i . Th us, when compared to U-Net, T3-Net can add up to nine times more concate- nate lay ers b et ween enco der and decoder. And concatenation of these v arious com binations improv es segmentation performance by transferring v arious lev- els of extracted features to the decoder’s restore pro cess. Figure 3 sho ws the arc hitecture of T3-Net where E i and D i are PPU i and UUP i . 3.2. Consider ations for designing T-Net T-Net can exist in v arious forms dep ending on the n umber and order of p ooling and up-sampling that build up E i and D i . Ho wev er, even if n ( P ) and n ( U ) increase, what is needed to obtain v arious sizes of feature-maps is con tinuous p ooling or up-sampling. In other w ords, ev en though the depth of the blo ck can b e increased b y placing P and U alternately , the sizes of the feature-maps generated are the same. The following equation shows the sizes of the feature-maps when alternating b et w een P and U . S(PUP i ) = S(PUPUP i ) = S(PUPUP ... PUP i ) = { h 2 i , h 2 i-1 } S(UPU i ) = S(UPUPU i ) = S(UPUPU ... UPU i ) = { h 2 i-2 , h 2 i-1 } (3) On the other hand, it should also b e taken into consideration that if the con tinuous P or U are long-lasting, the depth of E i can not b e deep ened. F or 11 example, consider T7-Net, where E i is PPPPUUU i . Supp ose that the size h of the original image is 256, which we normally deal in CNN classification. In this case, the feature-map sizes of E i are as follo ws. S(PPPPUUU i ) = { 256 2 i-1 , 256 2 i , 256 2 i+1 , 256 2 i+2 , 256 2 i+3 } (4) That is, the size of the smallest feature-map in the third enco der blo ck becomes 4 (256/64). Empirically , it is not recommended that the size of the last feature- map of the enco der b e reduced to less than 8. In the semantic segmentation problem, this is because w e can extract the high-level feature as we reduce the feature-map, but it will be difficult to restore it to the mask. Also, repeated placemen t of p o oling or up-sampling at short depths has the disadv antage of making the shape of the feature-map to o simple before extracting sufficien t lev els of features. F or example, considering the E i of the PPPUU structure in whic h the con v olution and p o oling lay ers are arranged three times, the size of the feature-maps may v ary , but b y reducing the size of the feature-map b y one- eigh th in the same blo c k, this structure is insufficient as an enco der. Therefore, w e configured only up to T5-Net in the ev aluation and set the smallest feature- map size of the enco der not to b e smaller than 8. And E i in T5-Net is designed as PPUPU structure instead of PPPUU to av oid more than tw o contin uous p ooling lay ers. The last p oint to consider when designing T-Net is that the P and U of the encoder and deco der need not be symmetric. That is, there is no problem in configuring the enco der with PPUPU and the deco der with UUP . How ev er, since the purpose of EDiED is to transfer the v arious lev els of features extracted from the enco der to the deco der, it is recommended that the length of the blo c k constituting the enco der is longer than the deco der. In other words, T53- Net delivers more feature levels to the deco der than T35-Net. Therefore, we added T53-Net as a comparison with U-Net. In T53-Net, the enco der blo ck is comp osed of PPUPU and the deco der blo ck is comp osed of UUP . As a result, the T-Nets we hav e configured for comparison with U-Net are T3-Net, T5-Net, and T53-Net. The structure of T3-Net is in Figure 3, and the structure of T5- 12 Net is sho wn in Figure 4. T53-Net is the same as replacing T5-Net decoder with UUP instead of UUPUP in Figure 4. Figure 4: Structure of T5-Net with PPUPU and UUPUP 4. Optimized T-Net for main v essel segmentation In this section, w e describ e an optimized T-Net structure for main vessel segmen tation in coronary angiography . Figure 5 shows the detailed structure of optimized T-Net. The o verall pro cess of glaucoma detection is as follo ws. First, angiogra- ph y images are augmen ted for regularization of the mo del. And w e train the augmen ted images on optimized T-Net by the mini-batc h size. The mo del is 13 Figure 5: Optimized T-Net structure for main vessel segmentation impro ved to minimize the v alidation loss and finally , the performance of the mo del is ev aluated using the test-set. 4.1. Data augmentation Our data consists of 4,700 gra yscale images with a size of 512 x 512. This is a small n um b er compared to general datasets suc h as ImageNet [28] or MS COCO 14 [17], and without prop er augmentation, the mo del will inevitably face o v erfitting problem. F ortunately , b ecause coronary angiography is taken in a defined form with a sp ecific purpose, ov erfitting can b e a voided with augmen tation ev en with 4,700 images. The effect of preven ting o v erfitting can also b e confirmed through the training loss of the optimized T-Net in the result section. In addition, w e train the model by resizing an image in a classification problem, but since the prediction of segmen tation is done by pixel levels, resizing is not recommended if GPU memory allows. Therefore, we used the size of the input image as the original 512 x 512. Our image augmentation p olicy is as follo ws. First, we zo om-in and zo om-out an image at a random ratio within ± 20%. And the heigh t and width of the image are shifted at a random ratio within ± 20% of image size 512 x 512. Next, we rotate the angiography image within ± 30 ◦ at random rates. Finally , b ecause the brightness of the angiography image can v ary , the brightness is also changed within ± 40% at random rates. Figure 6 sho ws images when each augmentation p olicy is applied to a single image at a maxim um rate. Figure 6: V essel images result from data augmentation 15 4.2. T-Net optimization for main vessel se gmentation In this section, w e describ e the sp ecific structure and fine-tuning parameters of optimized T-Net for main vessel segmen tation. First, w e set the o v erall T-Net structure to T5-Net. This is b ecause we compared U-Net, T3-Net, T5-Net, and T53-Net under the same conditions, and as a result, T5-Net sho wed the b est p erformance. How ev er, the image used in the comparison is resized to 256 x 256 in order to shorten the training time, and the structure of optimized T-Net is adv anced from that of T5-Net. The structures of T3-Net, T5-Net, and T53-Net designed for comparison with U-Net are describ ed in detail in the result section. The optimized T-Net consists of fiv e enco der blo c ks ( E i ) and deco der blo c ks ( D i ), respectively . E i is composed of PPUPU i , and D i is composed of UUPUP i . Eac h p o oling or up-sampling la yer is preceded by a conv olutional lay er ( C ). That is, the actual PPUPU is CPCPCUCPCU , but it is called PPUPU for con venience. Let P E i k b e the k-th p o oling or up-sampling lay er that app ears in E i , and similarly define U E i k , P D i k , U E i k , where i ∈ { 1,2,3,4,5 } and k ∈ { 1,2,3,4,5 } . The sizes of the feature-maps constituting E 1 is as follo ws. S ( E 1 ) = S ( { P E 1 1 , P E 1 2 , U E 1 3 , P E 1 4 , U E 1 5 } ) = { 512 , 256 , 128 , 256 , 128 } (5) Lik ewise, the sizes of feature-maps from E 2 to E 5 are as follo ws. S ( E 2 ) = { 256 , 128 , 64 , 128 , 64 } S ( E 3 ) = { 128 , 64 , 32 , 64 , 32 } S ( E 4 ) = { 64 , 32 , 16 , 32 , 16 } S ( E 5 ) = { 32 , 16 , 8 , 16 , 8 } (6) As previously defined, the deco der blo c k b ecomes D1 near the prediction, and the blo ck close to the conv olutional lay ers of center b ecomes D5. Therefore, the 16 sizes of feature-maps from D 5 to D 1 are as follo ws. S ( D 5 ) = { 16 , 32 , 64 , 32 , 64 } S ( D 4 ) = { 32 , 64 , 128 , 64 , 128 } S ( D 3 ) = { 64 , 128 , 256 , 128 , 256 } S ( D 2 ) = { 128 , 256 , 512 , 256 , 512 } S ( D 1 ) = { 256 , 512 , 1024 , 512 , 1024 } (7) Since the S ( P D 1 5 ) is 1024, the size of next con volutional lay er’s feature-maps b ecome 512. Therefore, connecting this conv olutional lay er to the final con vo- lutional lay er with four filters and applying a softmax function to the result, a feature-map of size 512 x 512 x 4 is generated. This represents the bac kground, LAD, LCX, and R CA scores for the 512 x 512 size mask. And each of these scores is compared with the actual class as pixel-by-pixel, and the total loss is used for the gradient calculation of the next ep o c h. Next, we explain how the concatenate lay ers are constructed based on the abov e feature-maps sizes and describ e the sp ecific parameters for fine-tuning. 4.2.1. Conc atenate layers in optimize d T-Net In optimzized T-Net, concatenate lay ers are connected immediately after up-sampling lay ers of U D i 1 and U D i 2 . In case of U D 4 1 , the size of feature- map after the up-sampling is 64, and the lay ers of the enco ders having such feature-map size is as follo ws. 64 = S ( E i ) = { S ( P E 4 1 ) , S ( P E 3 2 ) , S ( P E 3 4 ) , S ( U E 2 3 ) , S ( U E 2 5 ) } (8) If there are la yers of the same size in the enco der blo c k, w e concatenate the preceding lay er only in order to reduce GPU memory consumption. Therefore, the la yers concatenated with U D 4 1 are P E 4 1 , P E 3 2 , and U E 2 3 . Likewise, U D 4 2 is concatenated with P E 3 1 , P E 2 2 , and U E 1 3 . Figure 7 shows the concatenate la yers b etw een enco der and deco der blocks. F rom Figure 7, we can observe that T-Net delivers v arious levels of features to the deco der. In case of U-Net, the enco der blo c k connected to D 4 is only E 4 , 17 Figure 7: The concatenate lay ers in optimized T-Net but T-Net connects D 4 with all blo c ks in the enco der except the E 5 . Assume that the first concatenate lay ers list for D i is M 1 ( D i ) and the second list is M 2 ( D i ). Than the lists of concatenate la yers in optimized T-Net are as follo w. M 1 ( D 5 ) = { P E 5 1 , P E 4 2 , U E 3 3 } , M 2 ( D 5 ) = { P E 4 1 , P E 3 2 , U E 2 3 } M 1 ( D 4 ) = { P E 4 1 , P E 3 2 , U E 2 3 } , M 2 ( D 4 ) = { P E 3 1 , P E 2 2 , U E 1 3 } M 1 ( D 3 ) = { P E 3 1 , P E 2 2 , U E 1 3 } , M 2 ( D 3 ) = { P E 2 1 , P E 1 2 } M 1 ( D 2 ) = { P E 2 1 , P E 1 2 } , M 2 ( D 2 ) = { P E 1 1 } , M 1 ( D 1 ) = { P E 1 1 } (9) M 2 ( D i ) do es not exist b ecause the size of the feature-map is 1024 and there is no matc hing enco der la yer with the same size. 4.2.2. Short-cut c onne ctions in optimize d T-Net In optimized T-Net, the num b er of filters in the conv olutional la y er of E 1 starts from 32, and doubles in the next blo c k. Short-cut connection is a concept prop osed in ResNet [33], which has the effect of preven ting the p erformance degradation caused by deeply stacking the conv olutional lay ers. Therefore, re- cen t CNN mo dels necessarily include short-cut connections, and they also form short-cut connections that connect all the con volutional lay ers within a block, suc h as DenseNet [15]. Short-cut connections result in the addition b etw een 18 la yers, requiring the same num b er of filters as feature-maps of the same size. In case of optimized T-Net, the second and fourth, third and fifth la yers of all E i and D i ha ve the same num b er of filters as the same feature-map size, resp ectiv ely . Through the equation 6-8, the first lay er in the next blo ck has a feature-map of the same size as the second and fourth lay ers of the previ- ous blo c k. Therefore, an additional short-cut connection is p ossible by making only the first conv olutional lay er equal to the n umber of filters of the previous blo c k b efore double the num b er of filters of the next blo ck. Figure 8 shows how short-cut connections are constructed in three consecutiv e enco der blo c ks. Figure 8: Short-cut connections in encoder blo c ks of optimize T-Net Finally , the num ber of filters and size of feature-maps constituting eac h blo c k of optimized T-Net is as follo w. The num ber in paren theses is the size of the 19 feature-map. F ( E 1 ) = { 32(512) , 32(256) , 32(128) , 32(256) , 32(128) } F ( E 2 ) = { 32(256) , 64(128) , 64(64) , 64(128) , 64(64) } F ( E 3 ) = { 64(128) , 128(64) , 128(32) , 128(64) , 128(32) } F ( E 4 ) = { 128(64) , 256(32) , 256(16) , 256(32) , 256(16) } F ( E 5 ) = { 256(32) , 512(16) , 512(8) , 512(16) , 512(8) } F ( Ce ) = { 1024(16) , 512(16) } F ( D 5 ) = { 512(16) , 512(32) , 512(64) , 512(32) , 512(64) } F ( D 4 ) = { 256(32) , 256(64) , 256(128) , 256(64) , 256(128) } F ( D 3 ) = { 256(64) , 128(128) , 128(256) , 128(128) , 128(256) } F ( D 2 ) = { 128(128) , 64(256) , 64(512) , 64(256) , 64(512) } F ( D 1 ) = { 64(256) , 32(512) , 32(1024) , 32(512) , 32(1024) } F ( Pr ) = { 32(512) , 4(512) } (10) where Ce denotes tw o con volutional la yers in the cen ter and Pr refers the last t wo conv olutional la yers b efore final prediction. 4.2.3. Fine-tuning T-Net for optimization Con volutional la yers of optimized T-Net consist of conv olution, batch nor- malization [34], and activ ation function. The activ ation function uses softmax only in the last con volutional lay er and the others use ReLU [35]. The weigh ts of the conv olution are initialized by He initialization [36]. F or up-sampling, transp osed conv olution [21] and bi-linear up-sampling are the most common metho ds. As a result of the exp eriment, there w as no significan t difference in p erformance b etw een tw o. The detailed p erformance comparison result apply- ing each metho d in optimized T-Net is explained in the next section. Ho wev er, w e used bi-linear up-sampling b ecause transp osed conv olution requires num b er of free parameters. In general, Dice Similarity Co efficient score ( DSC ) is the p erformance metric for semantic segmentation problems. The definition of the DSC is describ ed in 20 the result section. The commonly used loss function in deep learning is cross en tropy loss ( CEL oss ). How ever, CEL oss has a disadv an tage in that loss cannot b e easily impro v ed when a large num ber of background pixels are included, whic h corresp onds to most medical image segmentation problems. Therefore, the following loss function DSCL oss is used to provide a balance b et ween CEL oss and DSC . D S C Loss = 1 + α C E Loss − D S C (11) Where α is a co efficien t for adjusting the scale of DSCL oss which set to 0.1 in this pap er. More sp ecifically , 1 - DSC attempts to reduce the loss of the pixels corresp onding to the vessels, and α CEL oss tries to reduce the ov erall pixel loss, including the bac kground. In the case of the optimizer function, we used the Adam [37] and set the initial learning rate to 0.0001. In addition, we reduced the learning rate with a factor of 0.5 if the v alidation loss do es not improv e for the last 5 ep o c hs. 5. Results A total of 4,700 coronary angiography images of patients who visited Asan Medical Center w ere ev aluated. All patients participating in the study pro vided written informed consent and the institutional review b oard of Asan Medical Cen ter appro ved the study . Exp erts with more than five y ears of exp erience split the main vessels (LAD, LCA, RCA) from the ostium to the distal site b y using The CAAS QCA system (Pie Medical Imaging BV, the Netherlands) [38]. Of the 4,700 angiography images, 1,987 (42.3%) w ere LAD, 1,307 (27.8%) w ere LCX, and 1,406 (29.9%) w ere RCA. F rom the total num ber of 4,700 an- giograph y images, 3,755 images (80%) were randomly split in to train-set and 945 images into (20%) test-set with the similar class distribution. 945 test-set images consisted of 393 LAD, 271 LCX, and 281 R CA images. V alidation-set consists of 565 images which corresp ond to ab out 15% of the train-set. As a result, 3,190 train-set images consisted of 1,349 LAD, 876 LCX, and 965 R CA 21 images. Likewise, of the 565 v alidation-set images, 245 images are LAD, 160 images are LCX, and 160 images are RCA. The softw are and hardw are environmen t for the ev aluation are as follo ws. W e tested on a 64GB serv er with t w o NVIDIA Titan X GPUs and an In tel Core i7-6700K CPU. The op erating system is Ubuntu 16.04, and the developmen t of the CNN mo del uses Python-based mac hine learning libraries including Keras [39], Scikit-learn [40], and T ensorFlo w [41]. 5.1. Evaluation setup The ev aluation of this pap er pro ceeds from tw o p erspectives. The first is to compare U-Net and T-Nets under the same conditions. In other w ords, it is to see ho w the p erformance of the main v essel segmentation differs in the most basic U-Net and T-Net structures. Therefore, unlike the optimized T-Net, the size of the image is resized to 256 x 256 to improv e the training sp eed, and the depth of the enco der and deco der is fixed to 3. The learning rate w as fixed at 0.0001 regardless of the v alidation loss, and no short-cut connection w as used. Likewise, since there is no reduction in the learning rate, the max ep och is 50, whic h corresp onds to half of the optimized T-Net. That is, the goal of the first ev aluation is to compare the performance of pure U-Net with that of T-Nets, to the greatest exten t, excluding other p erformance-enhancing factors. Ho wev er, the loss function uses the same DSCL oss as optimized T-Net b ecause con vergence is faster than using CEL oss . The T-Nets used in the comparison is T3-Net, T5-Net, and T53-Net. Unlike T-Nets, U-Net uses tw o consecutiv e con volutional lay ers to maintain the num b er of w eights in each blo ck similar to that of T3-Net. Figure 9 shows the schematic structure of the four mo dels used for the U-Net and T-Nets comparisons. The second is to ev aluate the optimized T-Net that exhibits the maxim um p erformance of the main vessel segmen tation in coronary angiography . First, Opt-Net is T-Net with all the fine-tuning metho ds describ ed in section 4. Briefly , the conv olutional lay er is connected with short-cut connections, the loss func- tion is DSCL oss , and uses bi-linear up-sampling. The T-Nets compared to 22 Figure 9: Schematic structures of U-Net, T3-Net, T5-Net, and T53-Net. Opt-Net are mo dels with removing tw o metho ds. Opt-Net 1 uses transp osed con volution instead of bi-linear up-sampling and Opt-Net 2 do es not hav e the short-cut connections. Other unsp ecified metho ds apply equally to all mo dels. More sp ecifically , the loss function is DSCL oss , data augmen tation is applied, the learning rate has a factor of 0.5 with 5 ep o c hs patience, and the maxim um ep och is 100. 5.2. Evaluation metrics The ev aluation of the main vessel segmen tation w as based on the following three metrics: Dice Similarity Co efficien t score ( DSC ), sensitivit y ( Se ), and precision ( Pr ). Dice Similarity Co efficient score, also called F1-score, means the harmonic mean of sensitivity and precision. Generally , in the semantic seg- men tation problem, we use the name DSC rather than F1-score. Sensitivity , also kno wn as the true positive rate or recall, measures the p ercentage of p os- itiv es that are correctly identified as the main vessel. Precision measures the 23 p ercen tage of positives that are predicted as the main vessel. In the case of accuracy and sp ecificit y , it is not generally included in ev aluation metrics for seman tic segmentation problem b ecause the class corresp onding to negative is a background. These metrics are defined with the following three terminolo- gies. How ever, since there are three types of main vessels, all ev aluation metrics are in to four differen t categories. That is, metrics for all types of main v essels (ALL), LAD, LCX, and R CA. • T rue Positiv e( TP ): The num b er of pixels in an angiograph y image cor- rectly iden tified as main vessels. • F alse Positiv e( FP ): The num b er of pixels in an angiograph y image incor- rectly iden tified as main vessels. • F alse Negative( FN ): The num ber of pixels in an angiograph y image incor- rectly iden tified as background D ice similar ity coef f icient ( D S C ) = 2 × P r × S e P r + S e S ensitiv ity ( S e ) = T P T P + F N × 100(%) P recision ( P r ) = T P T P + F P × 100(%) (12) In addition, loss and DSC according to ep o c h are graphically represen ted, and visualizations of mo del weigh ts and predicted mask with an actual mask are included. Detailed descriptions of the graphs and visualizations are pro vided in the follo wing section. 5.3. Evaluation r esults of U-Net and T-Nets T able 1 summarizes the ev aluation results of U-Net and T-Nets compared under the same condition explained in the previous section. The highest o verall DSC was 0.815 for T5-Net, 0.08 higher than T53-Net, 0.028 higher than T3-Net and 0.095 higher than U-Net. T5-Net and T53-Net did not sho w significan t p erformance differences in LAD and RCA, but T5-Net obtained 0.023 higher DSC in LCX segmen tation. Comparing T3-Net and U- Net, T3-Net was 0.067 higher than U-Net based on ov erall DSC . The difference 24 ALL LAD Metho d DSC Se (%) Pr (%) DSC Se (%) Pr (%) T53-Net 0.807 81.10 81.89 0.805 79.96 82.73 T5-Net 0.815 80.93 83.74 0.804 79.77 82.87 T3-Net 0.787 81.01 78.62 0.786 80.21 79.08 U-Net 0.720 75.39 71.52 0.733 76.25 72.78 LCX R CA Metho d DSC Se (%) Pr (%) DSC Se (%) Pr (%) T53-Net 0.730 75.52 72.68 0.883 88.08 89.60 T5-Net 0.753 75.70 77.08 0.890 87.58 91.39 T3-Net 0.697 73.83 69.20 0.874 89.00 87.05 U-Net 0.565 63.86 54.10 0.853 85.27 86.55 T able 1: Comparison results b etw een U-Net and T-Nets in performance betw een U-Net and T3-Net, whic h is the most similar in terms of the n umber of weigh ts and structurally , demonstrates that v arious concatenate la yers enhance performance. Considering that T3-Net has low er performance than T53-Net or T5-Net, the num b er of up-sampling la yers of the decoder blo ck to which the concatenate lay er is connected is also imp ortant. That is, T3-Net is concatenated to the first up-sampling lay er of the decoder blo ck, but T5-Net and T53-Net are concatenated in the first and second up-sampling lay ers. This mak es it clear that the p erformance of T53-Net is closer to T5, despite the fact that T53-Net is a half-mixed structure of T5 and T3. The difference b et w een U-Net and T-Net is more evident when comparing segmen tation performance for each vessel. First, the smallest p erformance gap b et w een T-Net and U-Net is R CA segmentation, and R CA has higher o verall p erformance than LAD or LCX. The highest DSC in the R CA segmen tation is 0.890 in T5-Net, 0.037 higher than the low est DSC from U-Net. On the other hand, in LCX segmen tation, T5-Net achiev e 0.753 DSC while U-Net sho ws only 0.565 DSC . This means that LCX segmen tation is the most difficult and RCA 25 segmen tation is the easiest problem. In other words, T-Net achiev es higher p erformance than the U-Net in a more difficult problem, which is LCX segmen- tation. Figure 10 show box plots for ov erall DSC , sensitivity , and precision for U-Net and T-Nets, resp ectiv ely . Figure 10: Box plots for comparison of U-Net and T-Nets 26 The solid line in the b ox represents the median v alue and the dotted line rep- resen ts the mean v alue. The rounded p oints ab o v e and b elo w the b o x represent outliers of 5% and 95%, resp ectiv ely . Other expressions follow the definition of the general b o x plot. In T able 1, T53-Net and T5-Net show ed similar p erfor- mance on av erage, but the b o x plot shows that T5-Net achiev es a fairly higher p erformance throughout the test-set. This is also the basis for our decision to design the optimized T-Net with T5-Net as the basis. Figure 11 sho w the v alidation DSCL oss and v alidation DSC for each ep o c h while training U-Net and T-Nets. As with the ab o ve p erformance analysis, we can see that T-Net p erforms better than U-Net. In other words, w e can see that DSCL oss of U-Net con verges at a higher v alue than those of T-Nets. Figure 11: V alidation loss and DSC of U-Net and T-Nets In the comparison betw een U-Net and T-Nets, the last thing to ev aluate is to visualize how the actual w eights of eac h mo del are trained. Therefore, w e visualized ho w the w eights of the conv olutional lay er that constitutes each deco der blo c k are activ ated for the same input image. Figure 12 are visualization of w eight activ ation for U-Net, T3-Net, T5-Net, and T53-Net. 27 Figure 12: Visualization of weigh t activ ation for U-Net and T-Nets 28 First, w e set the one of RCA vessel as the input image which sho ws relativ ely little p erformance difference than LAD and LCX vessels. What we wan t to see in Figure 12 is from which deco der starts to segment the mask clearly . The T-Nets b egin to show the outline of the mask from the b eginning of the deco der ( D 3 ), but D 3 in U-Net is almost invisible. In D 2 , the weigh ts in T-Nets are fairly clear, but those of U-Net are still unclear. And in D 1 , T-Nets activ ate the w eights similar to mask, but U-Net still activ ates the other vessels of the original image. This means that T-Net accurately predicts the mask from the b eginning deco der blo ck, which is possible through v arious concatenate lay ers b et w een enco der and deco der blo cks. More sp ecifically , all the blo c ks of the enco der are connected to D 3 , so early prediction can b e p erformed since the lo w-level to high-level features extracted from the encoder are transmitted to D 3 . 5.4. Evaluation r esults of optimize d T-Net for main vessel se gmentation T able 2 summarizes the optimized T-Net for three types of main vessel seg- men tation in coronary angiography . ALL LAD Metho d DSC Se (%) Pr (%) DSC Se (%) Pr (%) Opt-Net 0.890 88.32 90.50 0.884 86.57 91.17 Opt-Net 1 0.875 86.24 89.91 0.878 85.11 91.56 Opt-Net 2 0.865 87.10 87.13 0.855 84.49 87.88 LCX R CA Metho d DSC Se (%) Pr (%) DSC Se (%) Pr (%) Opt-Net 0.860 86.68 86.23 0.927 92.50 93.63 Opt-Net 1 0.831 83.10 84.53 0.914 91.10 92.58 Opt-Net 2 0.818 84.74 80.68 0.923 93.04 92.28 T able 2: Ev aluation results of optimized T-Net 29 The ov erall p erformance is b est for Opt-Net follow ed by Opt-Net 1 and Opt- Net 2 . Opt-Net is more efficient than Opt-Net 1 b ecause the segmentation p er- formance is b etter and trained with few er free-parameters. Comparing the total n umber of free-parameters, Opt-Net has 43,570,372 free-parameters and Opt- Net 1 has 55,883,236, which is ab out 28.26% more than Opt-Net. Based on the o verall DSC , Opt-Net is the b est at 0.890 follow ed by Opt-Net 1 and Opt-Net 2 . In addition, Opt-Net is alw ays b etter in all three metrics, with the exception of precision for LAD and sensitivity for RCA. Opt-Net 2 , which remov ed short-cut connections, shows a 0.025 low er DSC than Opt-Net. That is, adding a short- cut connection has reasonable effect on p erformance improv emen t. The DSC of Opt-Net is 0.170 higher than the DSC of U-Net in T able 1. F rom T able 1 and 2, prop osed T-Net p erforms b etter than U-Net in the main vessel segmentation problem, and the optimized T-Net sho ws the highest p erformance. The segmen tation performance of each main v essel shows the highest DSC in R CA, follow ed by LAD and LCX. This is in the same order as T able 1, with the highest DSC of 0.927 for RCA segmentation, whic h is an excellen t segmen tation p erformance. The highest DSC for LCX is 0.860, which is 0.295 higher than U- Net, whic h has the low est DSC in T able 1. In the LAD segmen tation, Opt-Net’s DSC is 0.884, an improv emen t of 0.151 ov er U-Net in T able 1. Figure 13 sho w b o x plots of DSC , sensitivit y , and precision for eac h main v essel and o verall vessel. Bo x plots also sho w that the segmentation p erformance of the LCX is lo w er than that of the other t w o main vessels. Considering that the n umber of LCX and RCA images is 1,307 and 1,406 resp ectiv ely , this difference is not due to clas s imbalance. This is b ecause unlike R CA, which is relativ ely easy to segmen t with no branc hing, LAD and LCX are more difficult to segment b ecause they are separated from single vessel. Also, b ecause of the small n um b er of LCX images compared to LAD, there is p erformance difference b etw een tw o v essels. The R CA segmen tation sho ws high performance in the en tire test-set as w ell as the highest av erage DSC seen in the T able 2. That is, the in ter-quartile range (IQR) is very narrow and is formed near 0.9 DSC , where IQR means the difference b et w een 75-th and 25-th p ercen tiles. The p erformance of LAD 30 segmen tation is intermediate betw een R CA and LCX and very similar to the distribution of o verall p erformance. Figure 13: Box plots for optimized T-Net 31 Figure 14 sho w the loss and DSC of the Opt-Net training pro cess for eac h train-set and v alidation-set. The part where the loss and DSC fluctuate in the staircase form is the ep o c h where the learning rate is halv ed b ecause there is no impro vemen t in the v alidation DSC during the last five ep o c hs. Figure 14: Loss and DSC of optimized T-Net Ov erall, we can observe that the v alidation loss and DSC improv ed con- tin uously ov er 100 ep ochs. How ever, we hav e exp erimen tally found that the minim um v alidation loss is formed betw een 80 and 100 ep o c hs and is not im- pro ved m uc h thereafter. Of course, if we increase the reduction factor of the learning rate and lengthen the patience epo ch, the performance can b e impro v ed with longer ep o c hs. Ho wev er, w e did not p erform an additional ev aluation with longer ep ochs because it to ok to o m uc h time b ecause our serv er p erformance w as limited. This effect is clearly observed near the 30 ep o ch of Figure 14. T able 3 compares the results of the prop osed optimized T-Net with the pre- vious main v essel segmen tation study . Jo’s study only p erformed LAD v essel segmen tation, so no p erformance comparison is p ossible in LCX and R CA ves- sels. F rom T able 3, proposed T-Net in the LAD segmen tation ac hieved 0.208 32 higher DSC than Jo’s approac h. In addition, Jo used U-Net, whic h is similar to the U-Net structure used for comparison with T-Net in this pap er. Under the same conditions, T5-Net show ed 0.071 higher DSC for LAD segmentation than that of U-Net. Therefore, it can b e said that T-Net’s segmen tation p erformance is b etter than U-Net in the main vessel segmen tation problem. ALL LAD Metho d DSC Se (%) Pr (%) DSC Se (%) Pr (%) Prop osed 0.890 88.32 90.50 0.884 86.57 91.17 T5-Net 0.815 80.93 83.74 0.804 79.77 82.87 U-Net 0.720 75.39 71.52 0.733 76.25 72.78 Jo et al [13] - - - 0.676 60.70 80.00 LCX R CA Metho d DSC Se (%) Pr (%) DSC Se (%) Pr (%) Prop osed 0.860 86.68 86.23 0.927 92.50 93.63 T5-Net 0.753 75.70 77.08 0.890 87.58 91.39 U-Net 0.565 63.86 54.10 0.853 85.27 86.55 Jo et al [13] - - - - - - T able 3: Comparison results b etw een prop osed metho d with previous study Figure 15 is the visualization of w eight activ ation for Opt-Net. Unlike Figure 12 with U-Net and T-Nets, we included entire blo c ks including enco der and deco der. W e can see the pro cess of predicting the final mask from the first enco der blo c k through the intermediate conv olution lay er and then through the deco der blo ck. In the first enco der blo ck, low-lev el features such as the contour of the blo od vessel are observ ed, and the higher-level features other than the outline of the blo od vessel are extracted as the next encoder mov es. When we reac h the cen ter, activ ation of w eigh ts is no longer similar to the original image’s shap e. In case of U-Net, only the information of the last encoder is concatenated to the first deco der blo ck D 5 . Ho wev er, since all encoder blo cks, except E 1 , are connected with D 5 , T-Net outputs activ ation close to the mask image from the 33 b eginning of restoring pro cess. As a result, subsequent deco der blo c ks fo cus on more sophisticated restoration of the mask, resulting in higher p erformance. In other w ords, the closer the latter stage of the decoder, the clearer the differences in the activ ation of main vessels and background. Figure 15: Visualization of weigh t activ ation for Opt-Net Finally , we show the predicted results of LAD, LCX, and R CA segmentation 34 of U-Net, T-Nets, and Opt-Net with actual masks in Figure 16 through 18. Although these examples are not the en tire test-set, but are sufficient to show the p erformance differences b etw een U-Net, T-Nets, and Opt-Net. F rom the figures, U-Net and T-Net do not differ greatly in the role of the enco der to extract high-lev el feature suc h as main v essel p osition under the same condition. Ho wev er, there is a p erformance gap in the restoration of the actual mask due to the differen t levels of features passed to the deco der Figure 16: Visualized LAD segmentation prediction results Figure 17: Visualized LCX segmentation prediction results 35 Figure 18: Visualized RCA segmentation prediction results 6. Conclusion In this pap er, w e prop osed T-Net con taining a small enco der-deco der inside the enco der-decoder structure (EDiED). T-Net ov ercomes the limitation that U-Net, which is the most popular model, can only ha ve a single set of the concatenate lay er b etw een enco der and deco der block. T o b e more precise, the U-Net symmetrically forms the concatenate lay ers, so the lo w-lev el feature of the enco der is connected to the latter part of the deco der, and the high-lev el feature is connected to the b eginning of the deco der. T-Net arranges the p o oling and up-sampling appropriately during the enco der pro cess, and lik ewise during the deco ding pro cess so that feature-maps of v arious sizes are obtained in a single blo c k. As a result, all features from the low-lev el to the high-level extracted from the enco der are delivered from the b eginning of the deco der to predict a more accurate mask. W e ev aluated T-Net for the problem of segmenting three main v essels (LAD, LCX, RCA) in coronary angiograph y images. The exp eriment consisted of a comparison of U-Net and T-Nets under the same conditions, and an optimized T-Net for the main v essel segmen tation. As a result, under the same conditions, T-Net recorded a DSC of 0.815, 0.095 higher than that of U-Net, and the optimized T-Net recorded a DSC of 0.890 which w as 0.170 higher than that 36 of U-Net. In addition, we visualized the weigh t activ ation of the conv olutional la yer of T-Net and U-Net to show that T-Net actually predicts the mask from earlier deco ders. Therefore, we exp ect that T-Net can b e effectively applied to other similar medical image segmen tation problems. Although this pap er only in tro duces a 2-dimensional T-Net structure, the structure of 3-D T-Net is the same. Only the conv olutional lay er and the p o oling la yer change from the existing 2-D to 3-D. Therefore, W e will apply 3-D T-Net to 3-D medical image segmen tation problems in future work. Ac kno wledgments This research w as supp orted by In ternational Research & Dev elopment Pro- gram of the National Researc h F oundation of Korea(NRF) funded b y the Min- istry of Science, ICT&F uture Planning of Korea(2016K1A3A7A03952054) and supp orted by Basic Science Researc h Program through the National Researc h F oundation of Korea(NRF) funded by the Ministry of Education (2016R1D1A1A 02937565) and the National Research F oundation of Korea(NRF) grant funded b y the Korea gov ernmen t(MSIT)( NRF-2017R1A2B3009800) and Institute for Information & communications T echnology Promotion(I ITP) gran t funded b y the Korea gov ernmen t(MSIT) (2018-0-00861, Intelligen t SW T echnology Dev el- opmen t for Medical Data Analysis) References [1] G. Litjens, T. Ko oi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi, M. Ghafo o- rian, J. A. V an Der Laak, B. V an Ginneken, C. I. S´ anc hez, A surv ey on deep learning in medical image analysis, Medical image analysis 42 (2017) 60–88. [2] O. Ronneberger, P . Fisc her, T. Brox, U-net: Conv olutional net works for biomedical image segmentation, in: International Conference on Medical image computing and computer-assisted interv en tion, Springer, 2015, pp. 234–241. 37 [3] W orld Health Organization, Cardiov ascular diseases (cvds) (2017). URL https://www.who.int/news- room/fact- sheets/detail/ cardiovascular- diseases- (cvds) [4] T. V os, C. Allen, M. Arora, R. M. Barb er, Z. A. Bhutta, A. Brown, A. Carter, D. C. Casey , F. J. Charlson, A. Z. Chen, et al., Global, re- gional, and national incidence, prev alence, and y ears lived with disability for 310 diseases and injuries, 1990–2015: a syste matic analysis for the global burden of disease study 2015, The Lancet 388 (10053) (2016) 1545–1602. [5] H. W ang, M. Naghavi, C. Allen, R. M. Barb er, Z. A. Bh utta, A. Carter, D. C. Casey , F. J. Charlson, A. Z. Chen, M. M. Coates, et al., Global, re- gional, and national life exp ectancy , all-cause mortality , and cause-sp ecific mortalit y for 249 causes of death, 1980–2015: a systematic analysis for the global burden of disease study 2015, The lancet 388 (10053) (2016) 1459–1544. [6] E. Nasr-Esfahani, S. Samavi, N. Karimi, S. R. Soroushmehr, K. W ard, M. H. Jafari, B. F elfeliyan, B. Nallamothu, K. Na jarian, V essel extraction in x-ray angiograms using deep learning, in: 2016 38th Annual interna- tional conference of the IEEE engineering in medicine and biology so ciety (EMBC), IEEE, 2016, pp. 643–646. [7] B. F elfelian, H. R. F azlali, N. Karimi, S. M. R. Soroushmehr, S. Sama vi, B. Nallamothu, K. Na jarian, V essel segmen tation in lo w contrast x-ray angiogram images, in: 2016 IEEE International Conference on Image Pro- cessing (ICIP), IEEE, 2016, pp. 375–379. [8] S. W ang, B. Li, S. Zhou, A segmentation metho d of coronary angiograms based on multi-scale filtering and region-growing, in: 2012 In ternational Conference on Biomedical Engineering and Biotechnology , IEEE, 2012, pp. 678–681. [9] F. M’hiri, L. Duong, C. Desrosiers, M. Cheriet, V esselwalk er: Coronary 38 arteries segmentation using random walks and hessian-based vesselness fil- ter, in: 2013 IEEE 10th International Symp osium on Biomedical Imaging, IEEE, 2013, pp. 918–921. [10] Y. Li, S. Zhou, J. W u, X. Ma, K. Peng, A no v el metho d of v essel segmenta- tion for x-ray coronary angiography images, in: 2012 F ourth In ternational Conference on Computational and Information Sciences, IEEE, 2012, pp. 468–471. [11] J. F. O’Brien, N. F. Ezquerra, Automated segmen tation of coronary v essels in angiographic image sequences utilizing temp oral, spatial, and structural constrain ts, in: Visualization in Biomedical Computing 1994, V ol. 2359, In ternational So ciet y for Optics and Photonics, 1994, pp. 25–38. [12] H. R. F azlali, N. Karimi, S. R. Soroushmehr, S. Shirani, B. K. Nallamothu, K. R. W ard, S. Samavi, K. Na jarian, V essel segmentation and catheter detection in x-ray angiograms using sup erpixels, Medical & biological en- gineering & computing 56 (9) (2018) 1515–1530. [13] K. Jo, J. Kweon, Y.-H. Kim, J. Choi, Segmen tation of the main v essel of the left anterior descending artery using selectiv e feature mapping in coronary angiograph y , IEEE Access 7 (2019) 919–930. [14] K. Simon yan, A. Zisserman, V ery deep conv olutional netw orks for large- scale image recognition, arXiv preprin t [15] G. Huang, Z. Liu, L. V an Der Maaten, K. Q. W einberger, Densely con- nected conv olutional netw orks, in: Pro ceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708. [16] M. Everingham, L. V an Go ol, C. K. I. Williams, J. Winn, A. Zisserman, The pascal visual ob ject classes (v o c) c hallenge, International Journal of Computer Vision 88 (2) (2010) 303–338. 39 [17] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P . P erona, D. Ramanan, P . Doll´ ar, C. L. Zitnic k, Microsoft coco: Common ob jects in con text, in: Europ ean conference on computer vision, Springer, 2014, pp. 740–755. [18] J. Long, E. Shelhamer, T. Darrell, F ully conv olutional net works for se- man tic segmentation, in: Pro ceedings of the I EEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440. [19] A. Krizhevsky , I. Sutskev er, G. E. Hin ton, Imagenet classification with deep conv olutional neural net works, in: Adv ances in neural information pro cessing systems, 2012, pp. 1097–1105. [20] C. Szegedy , W. Liu, Y. Jia, P . Sermanet, S. Reed, D. Anguelov, D. Er- han, V. V anhouck e, A. Rabinovic h, Going deep er with conv olutions, in: Pro ceedings of the IEEE conference on computer vision and pattern recog- nition, 2015, pp. 1–9. [21] F. Y u, V. Koltun, Multi-scale con text aggregation b y dilated conv olutions, arXiv preprin t [22] L.-C. Chen, G. P apandreou, I. Kokkinos, K. Murphy , A. L. Y uille, Semantic image segmentation with deep conv olutional nets and fully connected crfs, arXiv preprin t [23] L.-C. Chen, G. P apandreou, I. Kokkinos, K. Murph y , A. L. Y uille, Deeplab: Seman tic image segmentation with deep conv olutional nets, atrous conv o- lution, and fully connected crfs, IEEE transactions on pattern analysis and mac hine intelligence 40 (4) (2018) 834–848. [24] H. Zhao, J. Shi, X. Qi, X. W ang, J. Jia, Pyramid scene parsing net work, in: Pro ceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2881–2890. [25] Z. W u, C. Shen, A. V an Den Hengel, Wider or deeper: Revisiting the resnet mo del for visual recognition, Pattern Recognition 90 (2019) 119–133. 40 [26] L.-C. Chen, Y. Zh u, G. P apandreou, F. Schroff, H. Adam, Encoder-deco der with atrous separable conv olution for seman tic image segmen tation, in: Pro ceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 801–818. [27] L.-C. Chen, G. P apandreou, F. Schroff, H. Adam, Rethinking atrous conv o- lution for seman tic image segmentation, arXiv preprint [28] O. Russako vsky , J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy , A. Khosla, M. Bernstein, et al., Imagenet large scale vi- sual recognition challenge, In ternational journal of computer vision 115 (3) (2015) 211–252. [29] B. H. Menze, A. Jak ab, S. Bauer, J. Kalpathy-Cramer, K. F arahani, J. Kirby , Y. Burren, N. P orz, J. Slotb o om, R. Wiest, et al., The m ultimo dal brain tumor image segmentation b enc hmark (brats), IEEE transactions on medical imaging 34 (10) (2015) 1993–2024. [30] ¨ O. C ¸ i¸ cek, A. Ab dulk adir, S. S. Lienk amp, T. Brox, O. Ronneb erger, 3d u- net: learning dense volumetric segmen tation from sparse annotation, in: In- ternational conference on medical image computing and computer-assisted in terven tion, Springer, 2016, pp. 424–432. [31] F. Milletari, N. Na v ab, S.-A. Ahmadi, V-net: F ully conv olutional neural net works for v olumetric medical image segmen tation, in: 2016 F ourth In- ternational Conference on 3D Vision (3D V), IEEE, 2016, pp. 565–571. [32] X. Li, H. Chen, X. Qi, Q. Dou, C.-W. F u, P .-A. Heng, H-denseunet: hybrid densely connected unet for liver and tumor segmentation from ct volumes, IEEE transactions on medical imaging 37 (12) (2018) 2663–2674. [33] K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recog- nition, in: Pro ceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778. 41 [34] S. Ioffe, C. Szegedy , Batch normalization: Accelerating deep net w ork train- ing b y reducing internal cov ariate shift, arXiv preprint [35] V. Nair, G. E. Hin ton, Rectified linear units impro ve restricted b oltzmann mac hines, in: Proceedings of the 27th international conference on mac hine learning (ICML-10), 2010, pp. 807–814. [36] K. He, X. Zhang, S. Ren, J. Sun, Delving deep into rectifiers: Surpassing h uman-level p erformance on imagenet classification, in: Pro ceedings of the IEEE in ternational conference on computer vision, 2015, pp. 1026–1034. [37] D. P . Kingma, J. Ba, Adam: A metho d for sto c hastic optimization, arXiv preprin t [38] J. Haase, J. Escaned, E. M. v an Swijndregt, Y. Ozaki, E. Gronenschild, C. J. Slager, P . W. Serruys, Exp erimen tal v alidation of geometric and den- sitometric coronary measurements on the new generation cardiov ascular angiograph y analysis system (caas ii), Catheterization and cardiov ascular diagnosis 30 (2) (1993) 104–114. [39] F. Chollet, keras, https://github.com/fchollet/keras (2015). [40] F. P edregosa, G. V aro quaux, A. Gramfort, V. Mic hel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. W eiss, V. Dub ourg, et al., Scikit-learn: Mac hine learning in python, Journal of machine learning research 12 (Oct) (2011) 2825–2830. [41] M. Abadi, P . Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghema wat, G. Irving, M. Isard, et al., T ensorflow: A system for large- scale machine learning, in: 12th { USENIX } Symp osium on Op erating Sys- tems Design and Implemen tation ( { OSDI } 16), 2016, pp. 265–283. 42
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment