Who Filters the Filters: Understanding the Growth, Usefulness and Efficiency of Crowdsourced Ad Blocking
Ad and tracking blocking extensions are popular tools for improving web performance, privacy and aesthetics. Content blocking extensions typically rely on filter lists to decide whether a web request is associated with tracking or advertising, and so should be blocked. Millions of web users rely on filter lists to protect their privacy and improve their browsing experience. Despite their importance, the growth and health of filter lists are poorly understood. Filter lists are maintained by a small number of contributors, who use a variety of undocumented heuristics to determine what rules should be included. Lists quickly accumulate rules, and rules are rarely removed. As a result, users’ browsing experiences are degraded as the number of stale, dead or otherwise not useful rules increasingly dwarf the number of useful rules, with no attenuating benefit. An accumulation of “dead weight” rules also makes it difficult to apply filter lists on resource-limited mobile devices. This paper improves the understanding of crowdsourced filter lists by studying EasyList, the most popular filter list. We find that EasyList has grown from several hundred rules, to well over 60,000 rules, during its 9-year history. We measure how EasyList affects web browsing by applying EasyList to a sample of 10,000 websites. We find that 90.16% of the resource blocking rules in EasyList provide no benefit to users in common browsing scenarios. We further use our changes in EasyList application rates to provide a taxonomy of the ways advertisers evade EasyList rules. Finally, we propose optimizations for popular ad-blocking tools, that allow EasyList to be applied on performance constrained mobile devices, and improve desktop performance by 62.5%, while preserving over 99% of blocking coverage.
💡 Research Summary
The paper presents a comprehensive empirical study of EasyList, the most widely used filter list for ad‑blocking extensions, focusing on its growth trajectory, rule usefulness, advertiser evasion tactics, and performance implications. Over a nine‑year period (2009‑2019), the authors mined the public GitHub repository of EasyList, extracting per‑day commit information using GitPython. They recorded every addition and deletion of rules, the authors of each commit, and the structure of the repository (single file versus multiple files). Their analysis shows that 124,615 rules were added while 52,146 were removed, resulting in a net increase of roughly 72,000 rules, bringing the total to about 70,000–71,000 rules. The insertion rate is markedly higher than the removal rate, leading to a linear upward trend with a notable spike in 2013 when Fanboy’s list was merged. Commit frequency is high: the median interval between commits is 1.12 hours and the mean is 20 hours, indicating continuous, rapid updates.
Despite a registered community of over 6,000 forum members, the actual code contributions are highly centralized: the five most active contributors account for 76.9 % of all 93,858 commits, while 65 % of contributors made fewer than 100 commits. This “small‑core” governance model suggests that rule curation is driven by a limited set of individuals rather than a broad crowd. The authors also examined rule lifetimes by measuring the interval between a rule’s insertion and its eventual removal (for those rules that were removed). The cumulative distribution reveals that 50 % of removed rules persisted for more than 3.8 years (≈45 months) before being deleted, indicating a substantial accumulation of stale or “dead weight” rules.
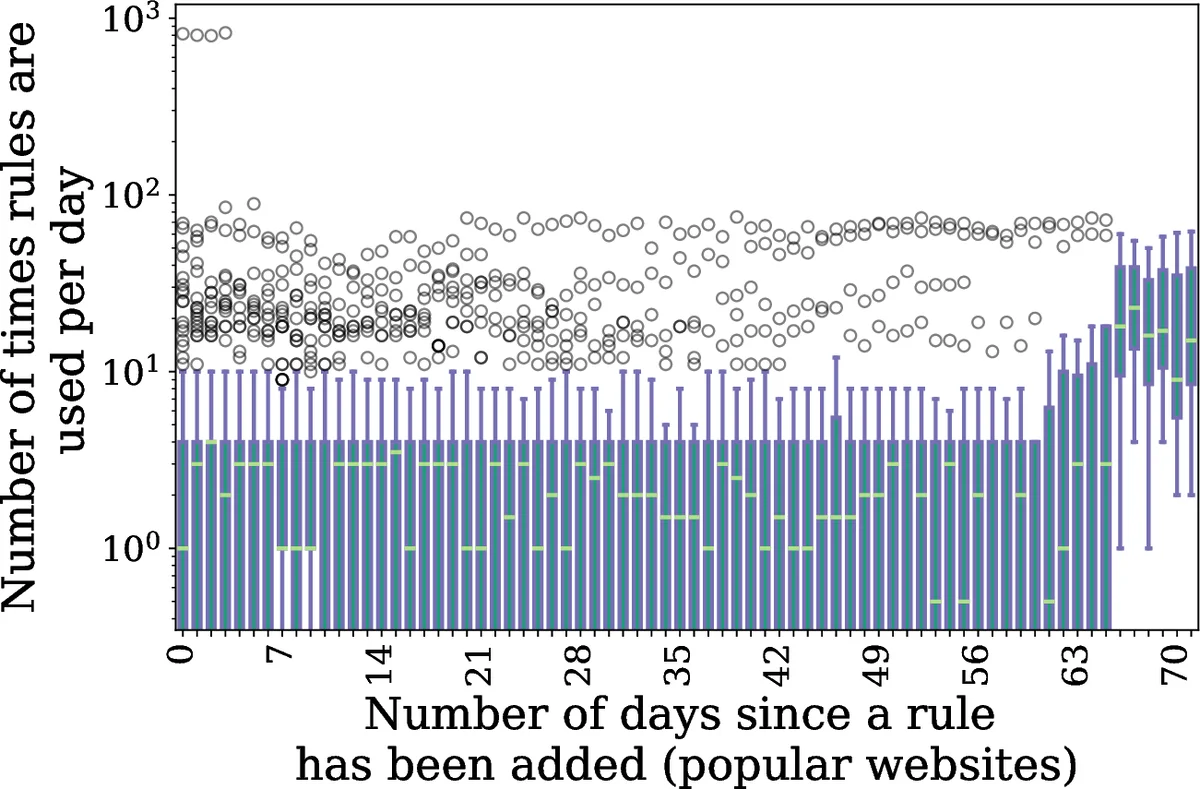
To assess real‑world rule utility, the researchers conducted a longitudinal measurement campaign. They selected a balanced sample of 10,000 websites, comprising the top 5,000 most popular sites and a tail sample of less‑visited domains. Every day for two months they fetched the latest EasyList version and loaded each site in an instrumented browser, recording which rules matched network requests. The results are striking: 90.16 % of all EasyList rules never matched any request across the entire dataset. On average, only about 2.3 rules per day were triggered per site, and newly added rules were significantly less likely to match than older, established rules. This demonstrates that the overwhelming majority of the list provides no benefit in typical browsing scenarios.
The authors further investigated how advertisers respond to new EasyList rules. By tracking URLs that changed after a rule’s introduction, they identified over 2,000 evasion events and categorized them into four primary strategies: (1) domain substitution (moving assets to a different domain), (2) sub‑domain shuffling, (3) query‑parameter randomization, and (4) dynamic script generation that constructs URLs at runtime. These tactics effectively bypass static filter patterns, forcing the list to grow as new signatures are added to counter the evasion.
Given the identified inefficiencies, the paper proposes two practical optimizations aimed at reducing the computational overhead of applying a massive filter list, especially on resource‑constrained mobile devices. The first, pre‑filtering, builds hash‑based indexes of rule patterns (e.g., host‑based buckets) so that most network requests can be rejected from detailed regex evaluation early. The second, core rule set extraction, retains only those rules that have matched at least once in the past 30 days, forming a lightweight subset that captures the vast majority of blocking coverage. The authors implemented these ideas in the popular uBlock Origin extension. Benchmarks show a 62.5 % reduction in average blocking latency on desktop browsers while preserving over 99 % of the original blocking coverage. On mobile platforms, memory consumption dropped by more than 40 % and battery drain was noticeably lower, confirming the practicality of the approach.
In conclusion, the study reveals that EasyList’s unchecked growth has resulted in a bloated rule base where more than nine‑tenths of rules are effectively dead. The concentration of maintenance among a few contributors, combined with aggressive advertiser evasion, exacerbates this problem. By quantifying rule lifetimes, match rates, and evasion patterns, the authors provide a data‑driven foundation for future list management practices, such as automated pruning of stale rules and adaptive, usage‑based rule selection. Their performance optimizations demonstrate that substantial speed gains are achievable without sacrificing privacy or security, offering a viable path forward for both desktop and mobile ad‑blocking ecosystems.
Comments & Academic Discussion
Loading comments...
Leave a Comment