Learning to Blindly Assess Image Quality in the Laboratory and Wild
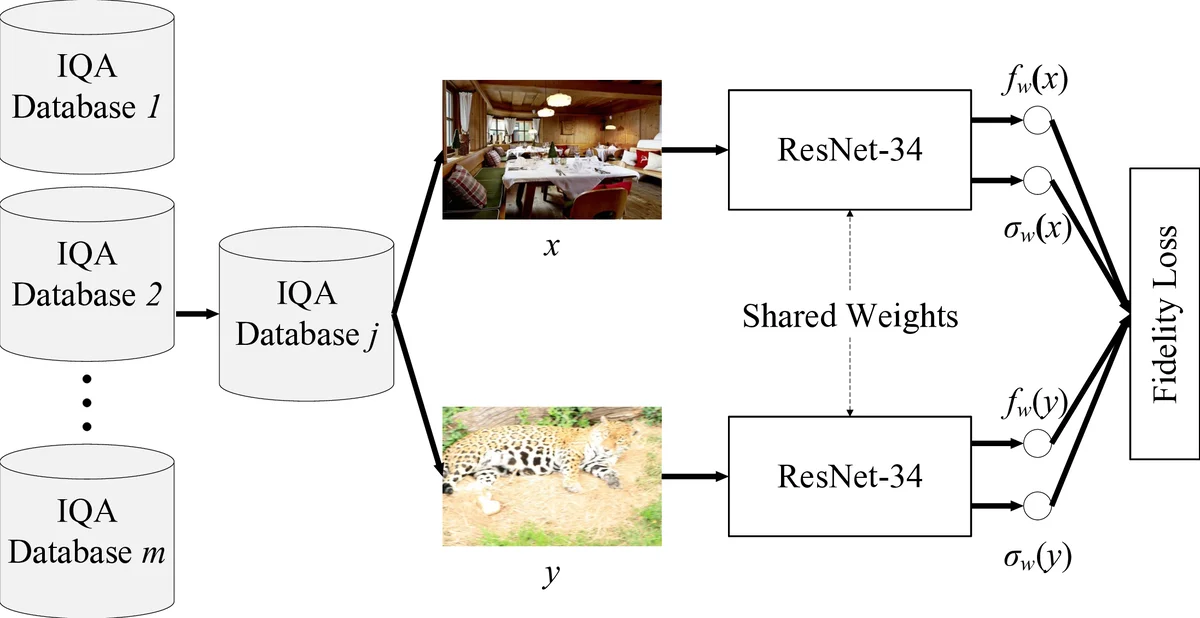
Computational models for blind image quality assessment (BIQA) are typically trained in well-controlled laboratory environments with limited generalizability to realistically distorted images. Similarly, BIQA models optimized for images captured in the wild cannot adequately handle synthetically distorted images. To face the cross-distortion-scenario challenge, we develop a BIQA model and an approach of training it on multiple IQA databases (of different distortion scenarios) simultaneously. A key step in our approach is to create and combine image pairs within individual databases as the training set, which effectively bypasses the issue of perceptual scale realignment. We compute a continuous quality annotation for each pair from the corresponding human opinions, indicating the probability of one image having better perceptual quality. We train a deep neural network for BIQA over the training set of massive image pairs by minimizing the fidelity loss. Experiments on six IQA databases demonstrate that the optimized model by the proposed training strategy is effective in blindly assessing image quality in the laboratory and wild, outperforming previous BIQA methods by a large margin.
💡 Research Summary
This paper addresses a fundamental limitation of current blind image quality assessment (BIQA) methods: models trained on synthetic distortions in controlled laboratory settings fail to generalize to realistic, “in‑the‑wild” distortions, and vice‑versa. Existing attempts to combine multiple IQA databases for training are hampered by the need to realign subjective score scales (MOS/DMOS) across databases, which requires additional subjective experiments.
The authors propose a novel training strategy that (1) constructs a massive pairwise training set by randomly sampling image pairs within each of six publicly available IQA databases (LIVE, CSIQ, TID2013 – synthetic; BID, LIVE Challenge, KonIQ‑10K – realistic) and (2) assigns each pair a continuous quality‑difference probability derived from the Thurstone model. Specifically, for images x and y with mean opinion scores μ(x), μ(y) and standard deviations σ(x), σ(y), the probability that x is perceived better than y is p(x,y)=Φ((μ(x)−μ(y))/√
Comments & Academic Discussion
Loading comments...
Leave a Comment