Pairs Trading with Nonlinear and Non-Gaussian State Space Models
This paper studies pairs trading using a nonlinear and non-Gaussian state-space model framework. We model the spread between the prices of two assets as an unobservable state variable and assume that it follows a mean-reverting process. This new model has two distinctive features: (1) The innovations to the spread is non-Gaussianity and heteroskedastic. (2) The mean reversion of the spread is nonlinear. We show how to use the filtered spread as the trading indicator to carry out statistical arbitrage. We also propose a new trading strategy and present a Monte Carlo based approach to select the optimal trading rule. As the first empirical application, we apply the new model and the new trading strategy to two examples: PEP vs KO and EWT vs EWH. The results show that the new approach can achieve a 21.86% annualized return for the PEP/KO pair and a 31.84% annualized return for the EWT/EWH pair. As the second empirical application, we consider all the possible pairs among the largest and the smallest five US banks listed on the NYSE. For these pairs, we compare the performance of the proposed approach with that of the existing popular approaches, both in-sample and out-of-sample. Interestingly, we find that our approach can significantly improve the return and the Sharpe ratio in almost all the cases considered.
💡 Research Summary
**
This paper introduces a novel framework for pairs trading that departs from the conventional linear‑Gaussian assumptions by employing a nonlinear, non‑Gaussian state‑space model. The spread between two assets, denoted as an unobservable state variable (x_t), evolves according to a flexible transition equation
(x_{t+1}=f(x_t;\theta)+g(x_t;\theta),\eta_t)
where (f(\cdot)) can represent a simple Ornstein‑Uhlenbeck drift, a quadratic drift, or the more general Ait‑Sahalia specification, and (g(\cdot)) captures conditional heteroskedasticity through ARCH‑type structures. The innovation term (\eta_t) is allowed to follow heavy‑tailed distributions such as Student‑t or generalized error distributions, thereby accommodating skewness, excess kurtosis, and volatility clustering observed in financial series.
Because the model is both nonlinear and non‑Gaussian, standard Kalman filtering is inapplicable. The authors therefore develop a “Quasi‑Monte Carlo Kalman Filter” (QMC‑KF). The key steps are: (1) approximate the possibly non‑Gaussian density of (\eta_t) by a Gaussian mixture obtained via relative‑entropy minimization; (2) generate low‑discrepancy Halton sequences transformed by Box‑Muller to sample from the predictive distribution; (3) update the state estimate using weighted averages of the simulated particles, yielding filtered spread (\bar{x}t) and an associated covariance matrix; (4) compute the log‑likelihood across the sample and obtain maximum‑likelihood estimates of the parameters (\psi=(\gamma,\theta,\sigma\varepsilon)). This procedure is computationally efficient, converges rapidly, and provides a real‑time estimate of the latent spread that serves as the trading signal.
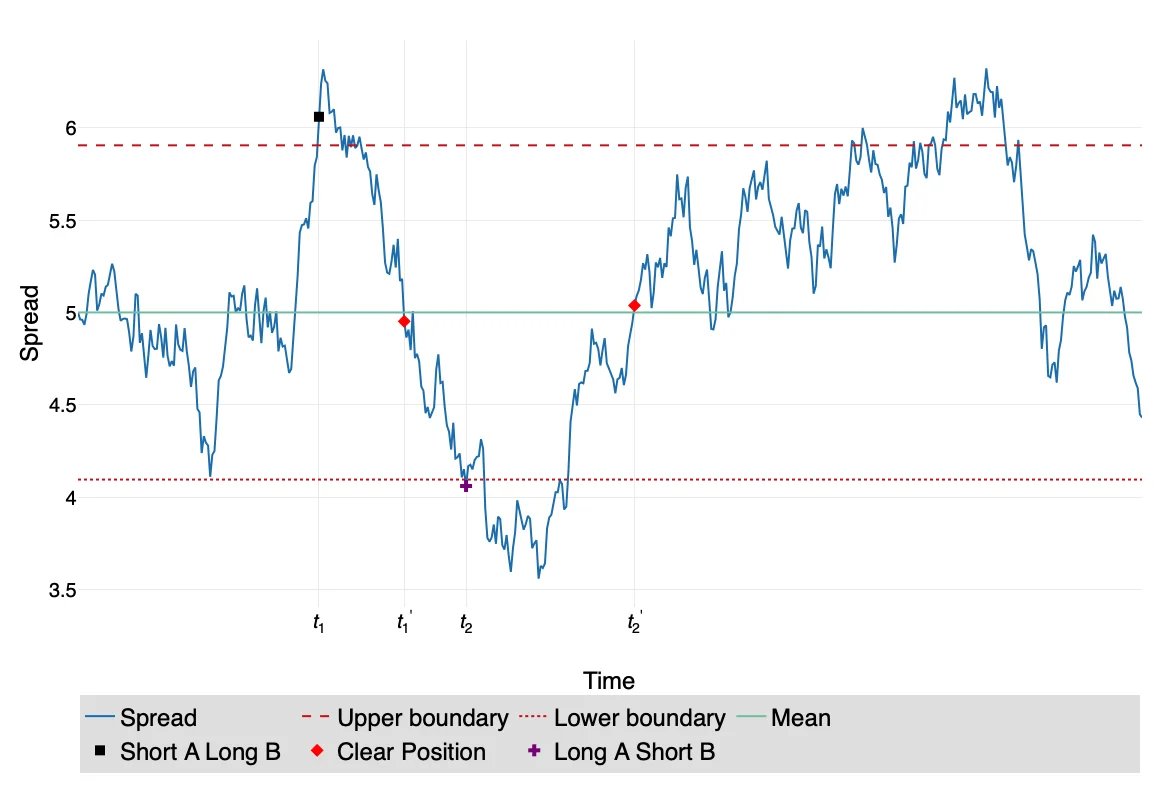
Two benchmark trading strategies are described. Strategy A opens a position when the filtered spread exceeds an upper bound (U) (short the first asset, long the second) or falls below a lower bound (L) (long the first, short the second), and closes the position when the spread reverts to its mean (C). Strategy B triggers trades when the spread crosses the bounds from the opposite side and switches positions immediately, holding the portfolio until the next crossing. Traditional rule‑setting methods—ad‑hoc sigma‑rules and first‑passage‑time (FPT) based thresholds—are reviewed, but they are shown to be sub‑optimal for the proposed nonlinear, heteroskedastic setting.
To determine optimal thresholds (U) and (L) for any chosen objective (maximizing expected cumulative return, Sharpe ratio, Calmar ratio, etc.), the authors employ a Monte‑Carlo simulation of the filtered spread paths. For each simulated path, the candidate trading rule is applied, and performance metrics are recorded. By searching over a grid of threshold values, the rule that optimizes the chosen objective is identified. This simulation‑based approach accommodates the full complexity of the model and yields customized trading rules for each asset pair.
Empirical evaluation proceeds in two stages. First, the method is applied to two well‑known pairs: PepsiCo (PEP) vs. Coca‑Cola (KO) and iShares MSCI Taiwan ETF (EWT) vs. iShares MSCI Hong Kong ETF (EWH). Using daily data, the proposed approach achieves annualized returns of 21.86 % (Sharpe 2.95) for PEP/KO and 31.84 % (Sharpe 3.89) for EWT/EWH, substantially outperforming a conventional linear‑Gaussian OU model (13.11 %/1.10 and 14.80 %/1.13 respectively).
Second, the authors examine all possible pairs among the five largest and five smallest U.S. banks listed on the NYSE, generating 45 distinct pairs. Both in‑sample and out‑of‑sample tests reveal that the new framework improves returns and Sharpe ratios for almost every pair. Notably, pairs of small banks exhibit higher volatility, providing more trading opportunities and larger alphas than pairs of large banks.
The paper’s contributions are fourfold: (1) a comprehensive nonlinear, non‑Gaussian state‑space model that captures heavy tails, volatility clustering, and nonlinear mean reversion; (2) a Quasi‑Monte Carlo Kalman filtering algorithm for efficient estimation of the latent spread and model parameters; (3) a simulation‑based procedure for deriving optimal trading thresholds tailored to specific performance objectives; and (4) extensive empirical evidence demonstrating superior profitability and risk‑adjusted performance relative to existing methods.
The authors acknowledge that the richer model entails higher computational demands, which may limit its direct application to ultra‑high‑frequency trading without further algorithmic optimization. They also suggest future work on robustness checks, model selection criteria, and extensions to multi‑asset portfolios. Overall, the study provides a rigorous and practical advancement for statistical arbitrage practitioners seeking to exploit complex dynamics in asset price spreads.
Comments & Academic Discussion
Loading comments...
Leave a Comment