A Diverse Clustering Particle Swarm Optimizer for Dynamic Environment: To Locate and Track Multiple Optima
In real life, mostly problems are dynamic. Many algorithms have been proposed to handle the static problems, but these algorithms do not handle or poorly handle the dynamic environment problems. Although, many algorithms have been proposed to handle …
Authors: Zahid Iqbal, Waseem Shahzad
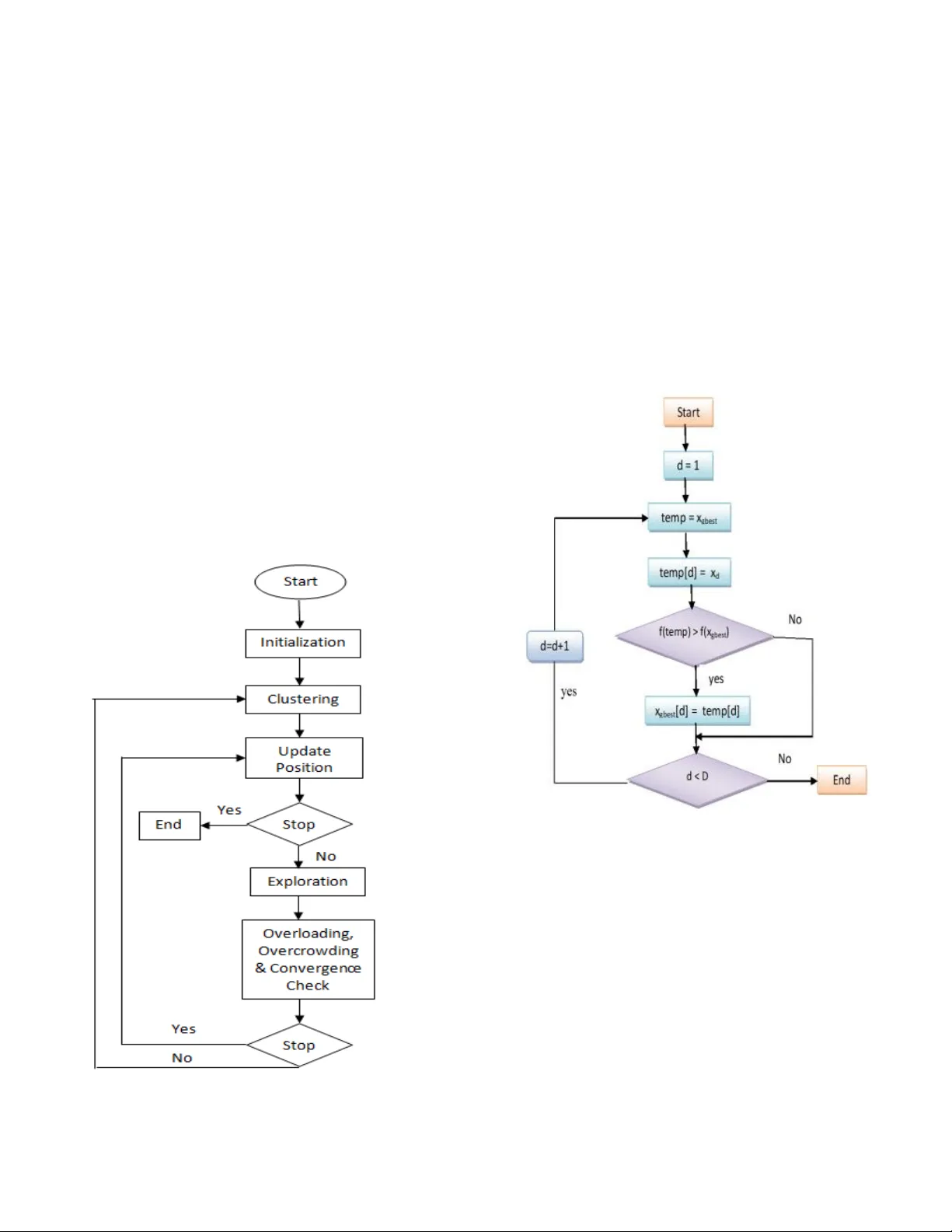
1 Abstract — In real life, mostly p roblems are dynamic. Many algorithms hav e been p roposed to ha ndle the static problems, but these algorithms do not handle or p oorly handle t he dyna mic environment problems . Although, many algorithms have been proposed to handle dynamic problems but still, there are some limitations or drawbacks in every algorithm regarding diversity of particles and tracking of already found optima. To ov ercome these limitations/drawbacks, we h ave pro posed a n ew e fficient algorithm to handle t he dynamic e nvironment effectively by tracking and locating multiple optima and by improving the diversity and convergence speed o f algorithm. In this algorithm, a new method has been proposed which explore th e undiscovered areas of search spa ce to in crease the diversity of algorithm. This algorithm also uses a method to ef fectively handle the overlapped and overcrowded particles. Branke has proposed moving peak benchmark which is commonly used MBP in literature. We also have performed different experiments on Moving Peak Benchmark. After comparing the exper imental results wi th different sta te o f art algorithms, it was seen that our algorithm performed more efficiently. Index Terms — Classical Optimization Techniques, Clustering, Particle Swarm Optimizer, Dynamic Environment, Diversity, tracking optima I. I NTRODUCTION lot of work has been done and is in prog ress in EA s for static en vironment [1]. But, recently, research in EA s is taking tu rn towards dynamic en vironment bec ause mo st o f the real wor ld problems which we f ace in daily life ar e dynamic.in static enviro nment, no record is maintain ed fo r the changing optima instead we just locate the optima but in d ynamic environment, we have to not only locate the multiple optima but also have to track the trajectory of ch anging op tima in search space. Several techniques in evolutionary schemes have been developed to add ress dynamic optimization problems. These schemes inclu de diversity schemes [2 ] [3] [ 4], memory schemes [5] [6] [7] multi-population schemes [8] [9] a daptive Zahid Iqbal was with Departme nt of IT in university of Punjab. Now he i s with Faculty of Comp uting an d IT in Un iversity of Gujrat, Punjab, Pakistan ; (e -mail: zahid.iqbal @uog.edu.pk). Waseem S hahzad is with N ational University of Com puter a nd Emer ging Sciences. (waseem.s hahzad@nu. edu.pk) schemes [ 10 ] [ 11 ] [ 12 ] mu lti-objective optimizatio n methods [ 13 ] [ 14 ] [ 15] and problem chang e detec ting approaches [16] and prediction schemes [17]. PSO has bee n very commonly used d ue to its attractive features like ease of implementation and no gradient information needed. It is being used to solve a large number of optimization prob lems although some of these problems can also be solved by genetic algorithms, n eural networks etc. So, it can be used where we do not h ave gradient or wh ere usag e of gradient can be costly. Basic PSO is a stoch astic opti mization techniq ue which has been perform ed well for static op timization problem s [18]. But diversity lo ss is the m ain li mitation o f basic PSO to hand le dynamic environment. The gbest particle pl ays a critical ro le to reduce the d iversity of the basic PSO. It stron gly attracts the other particles, so they prematur ely co nverge on the local optima o r global optima towards th e gbest particle. Whereas for DOPs, these particles should locate m ore and m or e local optima so that they m ay help in nex t environment. Diversity can b e increases b y using multi-popu lation method so in this method mu ltiple clusters cover diff erent peaks. But, then , we have to face the p roblems like how to g uide th e particles to move toward s a sub region, how to determin e numb er o f particles in a cluster, how to determine the number of clusters and so on. Recently, a clusterin g PSO has bee n proposed by Yang a nd Li to handle these problems in [ 19]. They have used the nearest neigh bor l earning strategy for training th e particles and hierarchal cl ustering meth od to locate and track m ultiple optima in dynamic environment. They employ the cluster ing in two phases 1) rough clustering and 2) refining clu stering. Although in [20], they have simplified their ap proach by removing the training meth od and employing th e clustering method in one step. Because instead using refining clustering, same objective can be ac hieved by using a threshold max_subsize which con trols th e number o f par ticles in a cluster. Second, training process was rem oved because there was no further need of it in [ 20] so in this way, computational resources can be used for local search. At last, in experimental study section, differ ent comparison s have been p erformed between our proposed method and recently published algorithm CPSO. A Diverse Clustering Particle Swarm Optimizer for Dynamic Environm ent : T o Locate and T rack Multiple Optim a Zahid Iqbal, Wase em Shahzad Member, IEEE A 2 II. R ELATED W ORK Basic alg orithm can be describe s in the following way , a swarm of particles fly to fin d the peaks in search space. Each particle k eeps record of its own best position in t he search space, which is called pbest p osition of a p article. Each particle also keeps record of best value, called lbest value, which is the best value among all pbest values of all particles. In each iteratio n, each particle updates its velocity and position and move toward s the lbest. The v elocity equ ation has social component as well as cognitive component. Setting a small social co mponen t and larg e cognitive component may help th e particles to exploit the search space effectiv ely and to avoid to stuck in local minim a. Whereas setting a lar ge social component and sm all co gnitive co mponent may h elp the particles to quick ly conver ge o n global optim a. Different versions of PSO have been proposed so different v ariations o f velocity equation have been pro posed. In [21] velocity and position of particles is u pdated in the f ollowing way. Fig 1. Basic PSO (1) ( 2) Here is called cognitiv e component and is called social com ponent. Where w : inertial weigh t . η 1 , η 2 : acceleration co nstants. r 1 , r 2 : random numbers. x d i ( t) : position of p article i in dimension d at time t. x d i ( t + 1): position of par ticle in dimension d at time t+1. v t i : velocity of particle i in dimension d at time t. v d i ( t + 1) : velocity of particle i in dimension d at time t+1. pbest d i : pbest of particle i in dimension d. gbest d : gbest of th e group. r 1 € U (0, 1) and r 2 € U (0, 1) in combin ation with 0 < c 1 , c 2 v ≥ 2 are used to d etermine the maximu m step that a p article can take in each iteration. w € U(0,1) deter mines the effect of the previous v elocity on new calculated velo city. The framework o f the or iginal PS O is shown in Basic PSO algorithm. Accor ding to Kennedy, if we remove t he social co mponent from the equation (2) i.e. use of the cognition only model degrades the performance of the swarm [22]. This may be due to fact that there is no interaction between diff erent particles. But when we use the so cial only model then it gives the performance b etter than original PSO on specific pr oblems. Basically, ther e are two main versions of th e PSO: lbest model an d gbest model . They are categ orized on their neighborhood . In gbest model, n eighborhood co nsists of whole swarm so each particle can share inf ormation with any other par ticle whereas in lbest m odel, neig hborhood consists of only some fixed particles. Both models giv e different performance on different problems. Acc ording to Kennedy and Eberh art [22] and Poli et al. [23 ], gbest model results in faster co nvergence but have a high prob ability of getting stuck in local optima. Wher eas lbest mo del have less chances of getting stu ck in local optima but also have slow convergence speed. III. P ROPOSED T EC HNIQUE Our algorithm work s in the following way: Algorithm starts b y generatin g a cradle swar m. After gen erating clusters using single linkage hierarchal clustering method, these clusters ex ploit those sub -regions of search space which are covered by these clusters. Then overlapping, overcrowd ing and convergence check are perf ormed on these clusters to control the redundancy. At th e en d of each iteratio n, if an environmental change is detected then a new cradle swarm is generated with reservation of p ositions of converged clusters of previous environments. In cluster b ased PSO algorithms, number of clusters and size of clusters play an important role. If we distribute too many clusters in search space, then it may be wastage o f computation al resources. On the other hand , if there ar e too small clu sters then alg orithm may n ot lo cate th e p eaks efficiently. To overcome this p roblem, different methods have been used to gen erate multiple clusters e. g. sing le link age 3 hierarchal clustering : Shengxiang Yang and Changhe Li '10 [20], k- means clustering algorithm: Ken nedy’00 [9], shifting balance GA (SBGA): Opp acher and Wineberg ’99, Self - organizing scouts (SOS) GA: Branke et al ’00, nbest PSO an d niching PSO (NichePSO): Brits ’02, Speciation based P SO (SPSO): Parr ott and Li ’ 04 [23], Charged PSO (mCPSO) a nd quantum swarm optimization (mQSO): Blackwell and Branke ’06 [2 5]. Each clustering m ethod h as different pros and cons. For example, number of clusters must be predefined in k - means, mCPSO and mQSO. B ut it is ver y difficult to know th e optimum value of k for a specific popu lation and it is usually problem dependent. Setting non -optimum value of k can result in improper number of clusters. For SPSO, mCPSO, and mQSO, the search rad ius must be given b y experiment al results. Similarly, NichePSO and SPSO, create the clusters without an alyzing th e d istribution of population. We ar e following the Sing le Lin kage Hier archal Clustering method. We have compared this with other methods of creating multiple clu sters and found that it is more suitab le to automatically cr eate p roper number of clusters in different areas of search space. This meth od works for any dynamic environment especially for un detectable dynamic environments. Fig 2. Flow Chart o f DCPSO The clusterin g method works in following way. First a list G is cr eated of size cradle swarm in such a way that each cluster in G co ntains ju st one particle of cradle swarm. T hen FindNearestPair alg orithm is ca lled iteratively to fin d a such pair of clu sters which have shortest distance between them and total nu mber of particles in b oth clu sters does not exceed by a specific thr eshold (max sub size) .Once such p air has been found then these two clusters are merged together. This process contin ues until all clusters in G have particles more than 1 . By using the max subsize threshold , number o f clusters and size of each cluster is automatically determin ed. As described in algorithm PSO. A linear decreasing schem e has been also used f or inertia w to fast the conver gen ce process as in [21 ]. w = w max – {(w max - w min ) * c_itr} / r itr (3) Fig 3. Updatio n of gbest of a cluster Here, w max = upper bound of inertia w min = lower bo und of inertia c_itr =cou nt cluster iteration , r itr = number of iteratio ns remaining before environment change To calculate th e remaining iterations r itr = (U cf – evals) / p_size where U cf = change frequen cy i.e. environment will ch ange after these fitess evaluation s p_size = total p articles in all clusters includin g cradle swarm We have used a dif ferent method to upd ate local best of each cluster d uring exploration [20 ]. In traditional way, when 4 a lbest position of a cluster is updated then all dimensions of this lbest are replaced with new position. In this w ay, some dimensions may have prom ising information which will be lost due to updating of all dimension s of lbest. To over come this prob lem, useful information is extracted from improved dimensions of improved particles rather than all dimensions of a lbest are updated. When a new position is found , each dimension of lbest is ch eck iteratively. We replace the dimension of lbest with corresponding d imensional valu e of particle if a better fitness value is found. After updating the pbest an d lb est of particles of all clusters, a new tech nique is used to up date the lbest o f worst cluster am ong oth er clusters as shown in Algo rithm 2. A worst clu ster is identified based on the fitn ess of its lbest p osition. First a worst clu ster is id entified. We extract u seful in formation from b est dimen sions of lbest of other clusters. We iteratively u pdate the d imensions of lb est of worst clu ster, if we found better fitness valu e ag ainst that position. Once lbest of worst cluster has b een u pdated then all particles of wo rst clusters ar e moved to that updated lbest. We ca n, also, use the co ncept of co nfidence v alue i.e. if we found a new position ; we set its con fidence valu e to 1 and if, again, this position comes then its confidence v alue will be incremented and so on. If we get a position with confidence value high er than or eq ual to 2 then we move the particles of worst cluster to th at new position. Normally o verlapping check is per formed based on th e radius of the cluster. Distance b etween lbest o f clusters is calculated and if this distance is less than the radius of the clusters then they are comb ined or an y one is removed. In this method, it is assumed th at each clu ster just cov ers one peak. But, in real scenar io, a cluster can co ver more than one peak so the merging o r removin g the cluster is not an efficien t method. To check overlapping of different clusters, we h ave used a method defined in [20]. In this meth od, first we find two overlapp ing clusters and calculate the o verlapping ration between these two clusters. To calculate ratio of cluster a , we find number o f par ticles of clu ster a within the r adius o f cluster b and v ice v ersa. After ca lculating the percentage, smaller per centage is taken an d if this p ercentage is les s tha n a specific threshold R then both clu sters ar e merged together. We do this pro cess for all clusters. After hand ling the overlapped clusters, ov ercrowding ch eck is performed o therwise too man y particles may search for a single peak so this can be wastage of resources. In this method, we remove a specific num bers of particles from a cluster if nu mber of particles it con tained bypass a specific threshold. Here max_sub si ze is a threshold value. A convergence check is perf ormed to ide ntify w hether a cluster has con verged or not. For this purpose, we set a small threshold value. If the rad ius o f a cluster is less than this small threshold value, th en we consid er that clu ster as a co nverged cluster. We save it s lbest to trac k th e mo vements in nex t environment. Fig 4. Finding a new best position When we perform convergence and overlapping check then there can be a scenario that we are with no clusters. So, to handle this specific case, we repopulate the main clu ster with some random p articles. Every dynamic PSO must b e able to d etect the environmental changes [2 6]. Ther e are different approaches to detect environmental change. For example, we can use the deteriorat ion in p opulation performance or time averaged best performance [27]. We m ay use some monitoring par ticles in fitness space. We can iteratively check the fitness of these particles. If fitness of these particles chan ges then we can say that an environmenta l change has o ccurred. We can also reevaluate th e pbest of each particle b efore u pdating [23]. Similarly, ther e are other ap proaches too. I n this paper, we are using lbest positions to detect environ mental chan ge. We simply reevaluate th e lbest particles ov er all clusters. If an environmental ch ange is detected, we save the lbest of each remaining clusters. Then add these saved lbest into a new generated main cluster. Then again clustering is per formed o n the new gen erated cluster. IV. E XPERIMENTAL S TUDY Th e default conf igurations which we have u sed in our proposed algorithm are given in Table 1. We have per formed the experiments on MPB problem proposed by Branke because it is the widely u sed dynamic b enchmark. I n this moving peak ben chmark problem, a peak can change its height, width , and loca tion. This MPB pro blem can be defined as: 5 Fig 5. Apply ing overcrowding check for a cluster (4) H i (t): height of peak i at time t W i (t): width o f peak i at time t X ij (t): jth element of locatio n of peak i p: number of p eaks. Table 1: M PB Problem Settin gs Parameter Name Parameter Value Number of dim ensions, D 5 H [30,70] Shift length, s 1.0 Height severity 7.0 Width severity 1.0 Peak shape Cone p (no. of peaks) 10 U cf (change frequency ) 10000 Basic function No Correlation co efficient, λ 0 S [0,100] W [1,12] I 50 The peak can move in any direction with velo city v i (t). This is given belo w: (5) Where s : shift length, d etermines severity of problem r : random vecto r λ : correlated p arameter . A peak upd ate its position , heig ht an d wid th in the following ways: H i (t) = H i (t − 1) height severity σ ( 6) W i (t) = W i (t − 1) width severity σ ( 7) X ij (t) = X ij (t − 1) + v i (t) ( 8) Here σ no rmal distribution rando m numb er with mean 0 and variation of 1. To calculate p erformance of algorith m, offline error is used. Where h n = best value of n th environment N = total envir onments f n = optimal solution of n th environment We first fin d diff erences b etween b est solutions and optim al solutions per en vironmental chan ge then we find average of all these d ifferences. Fitness evalu ations are calculated by multiplying change freq uency with total number of environments i.e. fitn ess evaluation s = N * U cf For our experiments, we have set N = 100 and U cf = 10 6 and average of 5 0 runs with different seeds is tak en for these experimen ts. V. R ESULTS Different experiments have been p erformed with different configuration s. MPB problems have been used for experimen ts with default settings. Different combinations of M and N are used where M deno tes size of cr adle swarm and N denotes size of su b-swarm. Table 2 shows offline error with average of 50 runs. Total numbers of generated clu sters are shown in Table 3. Number of survived clu sters are shown in Fig 4. Survived clusters contain both converged and non- converged clu sters. Table 4 shows numb er of found pe a ks. 6 Table 2: O ffline Error with different valu es of parameters N = 2 N = 3 N = 4 N = 5 N = 7 M = 10 3.76 4.46 4.83 7 5.3 M = 30 1.75 1.97 2.46 3.5 3.4 M = 50 1.4 1.39 1.77 1.6 2.54 M = 70 1.48 1.01 1.47 1.51 1.95 M=100 2.3 1.5 1.1 1.2 1.76 If a peak is within search radius of a cluster then we consider it to be fou nd by algor ithm. We h ave used this measure because it perform s very well for our experiments i.e. when performance of algorithm is compared with different configuration values of M and N then it gives very good results. Table 3: Nu mber of Clusters generated N = 2 N = 3 N = 4 N = 5 N = 7 M = 10 5 5 3 2.39 3 M = 30 16 12.5 8 7 5.5 M = 50 25.5 17 14 12 8.5 M = 70 38 26.5 20 17 11 M= 100 55 33 28 22 17 Fig. 6. Off line Error It ca n be seen from T able 2 and Fig 6 that configuration plays very vital role in performance of DCPSO. If we set value o f M very h igh or very low while value of N rema ins fixed, then performance of DCPSO also chang es. It was obs erved from experimen ts that wher e size of cradle swarm M is set to 7 0 and max imum sub -swarm size is set to 30 then our algorithm g ives optimum results. Table 4: Nu mber of Peaks Found N = 2 N = 3 N = 4 N = 5 N = 7 M = 10 3.8 3.16 2.8 2.41 2.32 M = 30 5.99 5.5 4.54 4.12 3.6 M = 50 6.89 6.45 5.67 5.04 4.58 M = 70 8 7.25 6.42 5.9 5.21 M= 100 7.26 7.75 7 6.48 5.76 Analysis of Table 3 and Table 4 sh ows that DCPSO found more peak s when we set population size larger. In fact, when we set population size larger , then more clusters are g enerated, and more peaks are found by algo rithm so performance of DCPSO also increases. But to ach ieve optim al results, we have to set ch ange frequen cy acco rding to problem otherwise we may get different results. Comparison o f DCPSO and CPSO We hav e compar ed o ur results with latest clustering PSO for dynamic environment [20] . A com parison of CPSO and DCPSO is g iven in Fig 8. We h ave perf ormed this ex periment with defau lt configuration s setting the size of population 70 and the cluster size (m ax_si ze) eq ual to 3 for CPSO a nd DCPSO. Fig. 7. Sur vived Clusters We can see in Fig 8 that with these configuration setting our p roposed algorithm perf orms better in all comparisons i.e. it g enerates more clusters, found more peaks, giv e less o ffline error and resu lt in more number of survived sub swarms. Fig 8. Comp arison of CPSO and D CPSO If we take car eful analysis of this co mparison an d other experimen ts then we can see that these resu lts also suppo rt our idea/concep t that by using explore_area() method, our algorithm try to find out the undiscovered area and then exploit th ose ar ea(s) to find m ore pea ks in the search space. Although, there is no guarantee that it will alwa ys find an undiscover ed area because it is also possibility that new created cluster may overlap with some existing cluster(s) so in this case we perform overlapping check. But, still, o ur algorithm try to perform better b y in creasing the div ersity of the alg orithm as we hav e discussed before that due to 0 2 4 6 8 N = 2 N = 3 N = 4 N = 5 N = 7 M = 10 M = 30 M = 50 M = 70 M=100 0 10 20 N = 2 N = 3 N = 4 N = 5 N = 7 M = 100 M = 70 M = 50 M = 30 M = 10 No. of clus ters generate d No. of survived cluste rs No. of peaks found Offline error 24.4 8.45 7.15 1.06 26.5 9 7.25 1.01 DCPSO CPSO 7 environment change and overlapping, overcrowding and convergence check, the population size and numb er of cl usters may decrease an d, in this situation, it b ecomes very d ifficult for any algorithm to locate and track multiple peaks. So , if our algorithm does not find a new location then , still, it tries to improve its p erformance. By tak ing an alysis of all experimen ts, it can be seen that performance of DCPSO vary if we change initial popu lation size o r if cluster size is changed. So, we hav e to set op timal configuration according to p roblem to achiev e optimal results . It was seen that our algorithm gives opti m al results when we set cradle swarm size to 7 0 and sub-swarm size to 3 with default configu ration on MPB problem . A. Conclusion and Future work Many Particle Swar m Optimizer algorithms are present currently for Dynam ic Optimization pr oblems. Many researchers have used multi swarm method to locate and track multiple o ptima in dyn amic environmen t. But, there are also some issues which nee ds to be consider ed when using multi swarm meth od; For examp le, how clusters sho uld be cr eated, how p articles of d ifferent clusters sho uld be guided to divert them to a specific sub-reg ion, how number of clusters should be determin ed and so on. Our proposed DCPSO p erfo rms very well for dynamic environment by ef ficiently f inding and tracking multipl e peaks. For generating proper number o f clusters, a single linkage hier archical clustering schem e is used. Then to exploit the un discovered sub regions and to m ove particles to specific sub reg ions, a local search method is u sed. Our algorithm als o uses a d ifferent learning strategy to speed up searching and convergence process. Then our algorithm extract s th e best information by exploring the undiscov ered r egions o f search space to find a new best position and to improve the diversity of clusters by m aintain ing clusters strength. DCPSO also used a scheme to handle dyn amic environmen t b y using best positions of p revious environment in new environment. Based o n experimental results, we can conclude that our proposed algorithm performs very well in terms o f finding and tracking multiple optima in dy namic environment. We hav e compared performance of our algo rithm with CPSO and found that our algorithm outperforms then CPSO w.r.t. ch ange severity in search space. Finally, accord ing to experiment s, DCPSO is a g ood optimizer for dynamic environments specially when there are multiple chan ging peaks in dynamic fitness landscape. Altho ugh, DCPSO is per forming very well still there are some issues which can be addressed in fu ture. E.g. during convergen ce ch eck, conv erged clu sters are removed which results in reduction of population size. Although we add some particles random ly but still th ere is p ossibility that these particles may be attracted by existing clusters. So mor e work needs to be do ne. We have set f ixed value of sub -swarm size in o ur algorithm which is not a g ood approach so more work can be done to make it self- adaptive. R EFERENCES [1] K. E. Parsopo ulos and M. N. Vrahatis, ” Recent approaches to global optimizatio n problems thro ugh particle swarm optimization”, Na tural Comp ut., vol. 1, n o. 2 -3, 2002, pp. 235-306. [2] H. G. Cobb and J. J. Grefenstette , ”Genetic algorithms for tracking changing envi ronme nts”, in Proc. 5th I nt. C onf. Ge netic Algorithms,19 93, pp. 523530. [3] J. J. Grefe nstette, ”Genetic alg orithms for changin g environments” , in Proc. 2nd I nt. Conf. Parallel Problem Solving Nature, 1 992, p p. 137144. [4] S. Ya ng, ”Genetic algorithms w ith memory and elitism -based immi- grants in dynamic environments”, Evol. Comput., vol. 16, no. 3, pp. 385416 , 2008. [5] J. Bran ke, ”Memory enhanced evolutionary algorithms for changing optim ization problems” , in Proc. Congr. Evol. Comput., vol. 3. 1999, pp. 18751882. [6] S. Yang, ”Associative memory scheme for genetic algorithms in dynamic environm ents”, i n Proc. EvoWorks hops: Appl. Evol.Comput., LN CS 3907. 20 06, pp. 7887 99. [7] S. Yang a nd X. Yao, ”Population -based i ncremental learning with associative memory for dynamic environments”, IEEE Trans. Evol. Comput. ,vol. 12, no. 5, pp. 542561, Oct . 2008. [8] J. Branke, T. Kauler, C. Schmidt, and H. Schmeck, ”A multipopulation approach t o dynamic optimization pro blems”, in Proc. 4th I nt. Conf. Adaptive Comput. Des. Manuf., 2000, pp. 299308. [9] S. Yang and X. Yao, ”Experimental study on po pulation -based incremental l earning algorit hms for dy namic optim ization problems”, Soft Comp ut., vol. 9, no. 11, pp. 815 834, Nov. 2005. [10] R. W. Morrison and K. A . De J ong, ”Triggered hypermutatio n revisited”, in Pro c. Congr. Ev ol. Comput., 20 00, pp. 102510 32. [11] S. Yang and H. Richter, ”Hyper -learning for population-based incremental learn ing in dynamic environm ents”, in Proc. Congr. Evol. Comput. , 2009, pp. 6 82689. [12] S. Yang a nd R. Tinos, ”Hyper -selection in dynamic environments”, in Proc. Congr. Evol. Comput., 2008, p p. 31853192. [13] L. T. Bui, H. A. Abba ss, and J. Branke, ”Multio bjective optimization f or dy namic envir onments”, in Proc. Congr. Evol. Comput., vol. 3 . 2005, pp. 2349 2356. [14] Zahid Iqbal et al. , “Eff icient Machine L earning Techniques for Stock Market Prediction”, Int. J. Engineering and Research Applications (I JERA) vol. 3, I ssue 6, Nov-Dec 2013, pp.855-867. [15] Zahid I qbal, Za far Mehmood , Muddesar Iqbal , Muhammad Ali , Naveed Anwar But t , “ A Systematic Mapping Stud y on OCR Techniques ”, Internationa l journal o f Computer Science & Network Solut ions, vol. 2, I ssue 1, 2014, pp. 65-81. [16] H. R ichter, ”Detecting change in dynamic fitness landscapes”, in Proc. Congr. Ev ol. Comput., 2009, pp. 16 131620. [17] Zahid Iqbal, R. Ilyas, W. Shahzad, Z.M.Khattak and J.Anjum, “Efficient Ma chine Le arning algorithms for stoc k price prediction (Accepted for p ublication) ”, Intern. Jour. of Engine ering and Research Applicat ion, to be pu blished. [18] K. E. Parsopoulos an d M. N. Vrahatis, ”Rece nt approaches to global optimizatio n problems thro ugh particle swarm optimization”, Na t. Compu t., vol . 1, nos. 23, p p. 235306, 200 2. [19] C. Li and S. Ya ng, ”A clustering particle sw arm optimizer for dynamic optimizatio n”, in Proc. Congr. Evol. Comput., 2009, pp. 439446. [20] Shenxiang Yang and Changhe Li, ”A clustering p article swarm optimizer for locating and tracking multiple optima in dynamic environment”,I EEE Trans. E vol. Comput., vol. 14, no. 6, Dec 2010. [21] Y. Sh i, R. Eberhart, ”A modified particle swarm optimizer”, in Proc. IEEE C onf. Evol. Comp ut., 1998, p p. 6973. [22] J. Kennedy, ”T he particle swarm: S ocial adaptatio n of knowledge”, i n Proc. Congr. Evol. Comput., 1997, pp. 3033 08. [23] J. Kennedy and R. C. Eberhart, ”Swarm Intellige nce”, San Mateo, CA: Morgan Kaufm ann, 2001 . [24] D. Parrott a nd X . Li, ”Loca ting and tracking m ultiple dynamic optima by a particle swarm m odel using sp eciation”, I EEE Trans . 8 Evol. Comput. , vol. 10, no. 4, pp. 44045 8, Aug. 2006. [25] T. M. Blackwell and J. Branke, ”Multiswarms, exclusion, and anticonvergence in d ynamic environments”, IEEE Trans. E vol. Comput., vol. 1 0, no. 4, pp. 459472, A ug. 2006. [26] H. R ichter, ”Detecting change in dynamic fitness landscapes”, in Proc. Congr. Ev ol. Comput., 2009, pp. 16 131620. [27] J. Branke, ”Evolutionary Optimi zation in Dynam ic Environme nts”, Norwell, MA: K luwer, 2002.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment