Practical Constraint Solving for Generating System Test Data
The ability to generate test data is often a necessary prerequisite for automated software testing. For the generated data to be fit for its intended purpose, the data usually has to satisfy various logical constraints. When testing is performed at a system level, these constraints tend to be complex and are typically captured in expressive formalisms based on first-order logic. Motivated by improving the feasibility and scalability of data generation for system testing, we present a novel approach, whereby we employ a combination of metaheuristic search and Satisfiability Modulo Theories (SMT) for constraint solving. Our approach delegates constraint solving tasks to metaheuristic search and SMT in such a way as to take advantage of the complementary strengths of the two techniques. We ground our work on test data models specified in UML, with OCL used as the constraint language. We present tool support and an evaluation of our approach over three industrial case studies. The results indicate that, for complex system test data generation problems, our approach presents substantial benefits over the state of the art in terms of applicability and scalability.
💡 Research Summary
The paper tackles the problem of generating synthetic test data for system‑level testing, where the data must satisfy rich, first‑order‑logic‑style constraints expressed in UML class diagrams and OCL. Traditional constraint‑solving approaches such as exhaustive SAT‑based tools (Alloy) or constraint‑programming translations (UML‑to‑CSP) struggle with scalability when the models contain many inter‑dependent objects, quantifiers, and collection operations. To overcome these limitations, the authors propose a hybrid solving framework that combines meta‑heuristic search with Satisfiability Modulo Theories (SMT).
The core of the approach is a preprocessing step that converts all OCL constraints into Negation Normal Form (NNF). In NNF, logical operators are pushed to the top of the expression tree, making it straightforward to partition the constraint into sub‑formulas. Each sub‑formula is classified as either “search‑friendly” (e.g., involving complex collection manipulations, non‑linear arithmetic, or user‑defined functions) or “SMT‑friendly” (e.g., linear integer/real arithmetic, Boolean combinations). Search‑friendly parts are handed to a meta‑heuristic engine (genetic algorithm, particle swarm, etc.), while SMT‑friendly parts are translated into SMT‑LIB format and solved by a state‑of‑the‑art SMT solver (Z3). The two solvers run iteratively: the search engine proposes candidate assignments, the SMT solver checks the SMT‑friendly portion and returns a model that is fed back to the search engine, thereby pruning the search space and avoiding local minima.
The authors implemented this methodology in a tool called PLEDGE (PracticaL and Efficient Data GEnerator for UML). PLEDGE automates the entire pipeline: model loading, NNF conversion, sub‑formula partitioning, execution of the search and SMT phases, and integration of the partial solutions into a complete instance model. Users can configure search parameters (population size, mutation rate, number of generations) to adapt the process to specific domains.
Evaluation is performed on three industrial case studies:
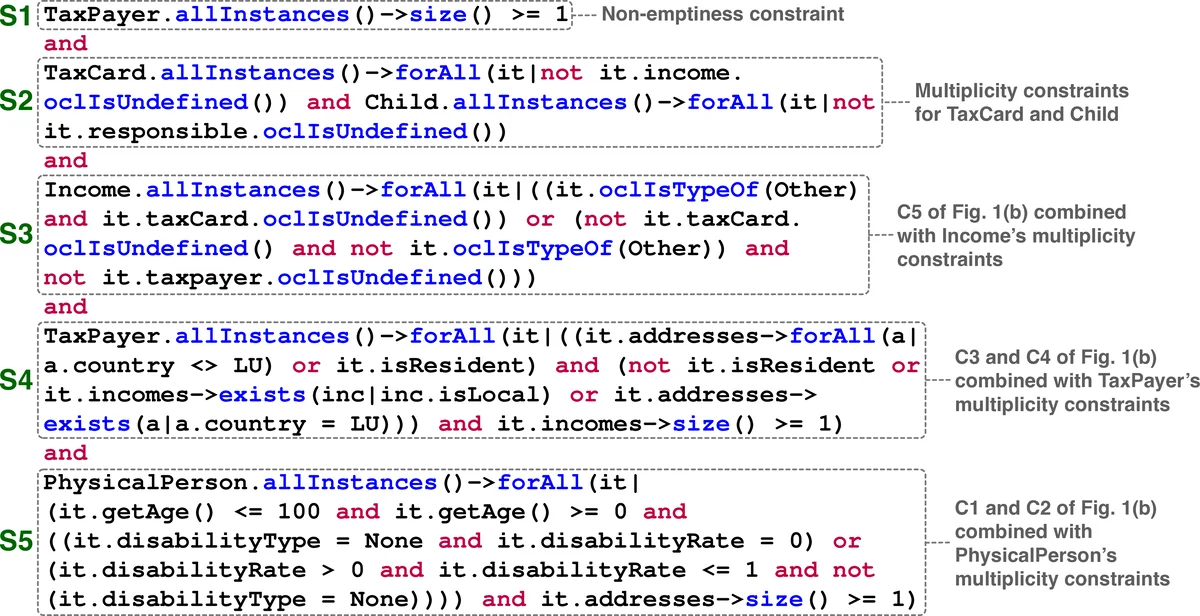
- Luxembourg government’s personal income‑tax management system (complex tax‑payer, income, address relationships, heavy use of quantifiers).
- A medical‑insurance claim processing system (large numbers of patients, treatments, and cost calculations, extensive collection operations).
- An automotive parts‑management system (massive inventories, supplier relationships, and intricate business rules).
For each case, the goal was to generate instance models ranging from 100 000 to 1 000 000 objects while satisfying all diagrammatic and OCL constraints. The authors compare PLEDGE against Alloy, UML‑to‑CSP, a pure meta‑heuristic baseline, and a pure SMT baseline. Results show that PLEDGE consistently outperforms the alternatives: it solves the instances 2–5 times faster, achieves a success rate above 95 % (versus 60‑80 % for the competitors), and can handle problem sizes that cause memory or timeout failures in the other tools. Ablation experiments demonstrate that removing either the search component or the SMT component degrades performance by 30‑70 %, confirming the complementary nature of the two techniques.
The paper also discusses limitations. Currently, the approach does not fully support non‑linear real arithmetic, higher‑order functions, or external API calls that may appear in OCL. The effectiveness of the meta‑heuristic depends on parameter tuning, which may require domain‑specific expertise. Future work is outlined: extending the SMT front‑end to additional theories (e.g., string regular expressions, non‑linear arithmetic), developing adaptive strategies that dynamically decide which sub‑formulas to assign to which solver, broadening support to other modeling languages such as Ecore or SysML, and integrating test‑objective‑driven generation (e.g., targeting specific coverage criteria).
In summary, the paper makes a significant contribution to model‑based test data generation by introducing a practical, scalable hybrid constraint‑solving technique that leverages the strengths of both meta‑heuristic search and SMT solving. The empirical evidence from real‑world industrial systems validates the approach’s applicability and demonstrates that it can bridge the gap between expressive, first‑order‑logic constraints and the need for large‑scale, automatically generated test data in practice.
Comments & Academic Discussion
Loading comments...
Leave a Comment