Learning Spatial-Spectral Prior for Super-Resolution of Hyperspectral Imagery
Recently, single gray/RGB image super-resolution reconstruction task has been extensively studied and made significant progress by leveraging the advanced machine learning techniques based on deep convolutional neural networks (DCNNs). However, there has been limited technical development focusing on single hyperspectral image super-resolution due to the high-dimensional and complex spectral patterns in hyperspectral image. In this paper, we make a step forward by investigating how to adapt state-of-the-art residual learning based single gray/RGB image super-resolution approaches for computationally efficient single hyperspectral image super-resolution, referred as SSPSR. Specifically, we introduce a spatial-spectral prior network (SSPN) to fully exploit the spatial information and the correlation between the spectra of the hyperspectral data. Considering that the hyperspectral training samples are scarce and the spectral dimension of hyperspectral image data is very high, it is nontrivial to train a stable and effective deep network. Therefore, a group convolution (with shared network parameters) and progressive upsampling framework is proposed. This will not only alleviate the difficulty in feature extraction due to high-dimension of the hyperspectral data, but also make the training process more stable. To exploit the spatial and spectral prior, we design a spatial-spectral block (SSB), which consists of a spatial residual module and a spectral attention residual module. Experimental results on some hyperspectral images demonstrate that the proposed SSPSR method enhances the details of the recovered high-resolution hyperspectral images, and outperforms state-of-the-arts. The source code is available at \url{https://github.com/junjun-jiang/SSPSR
💡 Research Summary
The paper addresses the challenging problem of single‑image super‑resolution (SR) for hyperspectral imagery (HSI), where the number of spectral bands can reach several hundreds and training data are scarce. Directly applying state‑of‑the‑art gray/RGB SR networks to HSIs is infeasible because (i) the high spectral dimensionality leads to an explosion of parameters and over‑fitting, and (ii) such networks ignore the strong inter‑band correlations that are essential for preserving spectral fidelity. To overcome these issues, the authors propose a novel framework called SSPSR (Spatial‑Spectral Prior Super‑Resolution).
Key components of SSPSR are:
-
Spatial‑Spectral Prior Network (SSPN) – a deep residual‑in‑residual architecture that stacks multiple Spatial‑Spectral Blocks (SSB). Each SSB contains two parallel branches: a conventional 2‑D spatial residual module that extracts texture and edge information, and a spectral attention residual module that learns channel‑wise (i.e., band‑wise) attention weights, thereby emphasizing informative spectral relationships while suppressing redundant ones. The two branches are fused and passed through short and long skip connections, ensuring stable gradient flow.
-
Group Convolution with Parameter Sharing – the input HSI is split into several overlapping spectral groups (e.g., four groups). A lightweight sub‑network with identical weights processes each group. This design dramatically reduces the total number of learnable parameters, making the model trainable on limited HSI datasets while still capturing intra‑group spectral patterns.
-
Progressive Upsampling – instead of a single large upscaling step (e.g., 8×), the network first performs a modest upsampling (typically 2×) within each group, followed by a global upsampling stage that brings the feature maps to the final resolution. After each group‑level upsampling a “reconstruction” layer converts the intermediate features back to image space, allowing the global SSPN to refine and fuse them. This staged approach mitigates information loss and stabilizes training for high scaling factors.
-
Loss Function – the primary objective is an L1 reconstruction loss, complemented by a spectral angle mapper (SAM) regularizer that penalizes angular deviations between the predicted and ground‑truth spectra, thus preserving spectral signatures.
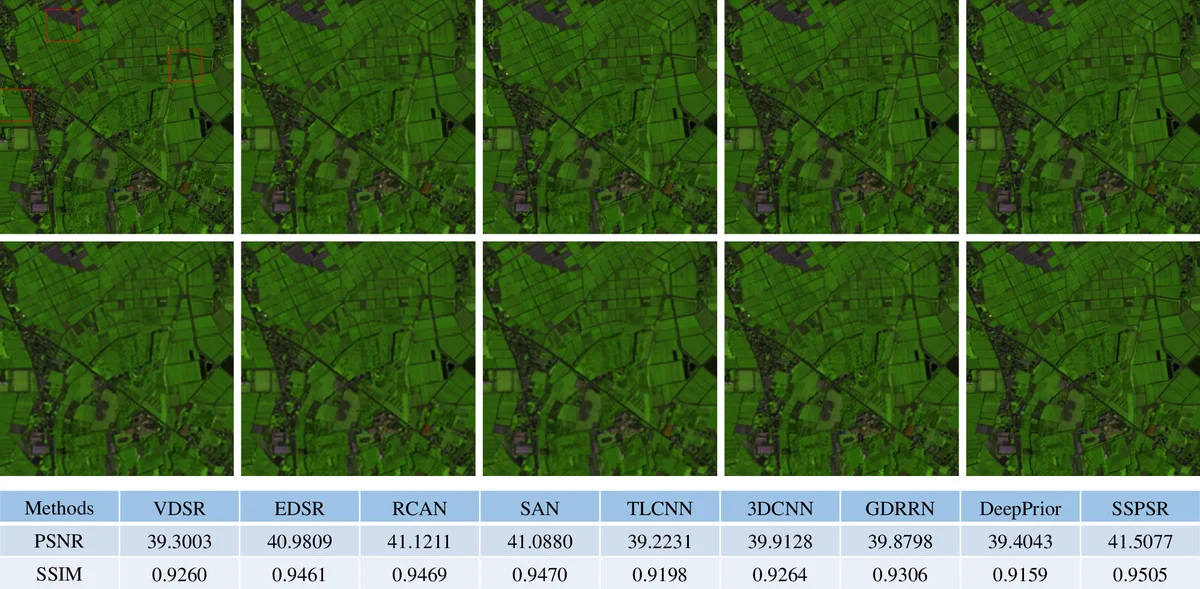
The authors evaluate SSPSR on two public HSI benchmarks (CAVE and ICVL) for 2×, 4×, and 8× upscaling. Quantitative results show consistent improvements over recent deep‑learning baselines such as 3‑D CNN‑based SR, GDRRN, and adapted RCAN, with PSNR gains of 0.3–0.7 dB, SSIM improvements of 0.01–0.03, and SAM reductions exceeding 10 %. Importantly, SSPSR achieves these gains with roughly 30 % of the parameters of comparable 3‑D models and reduces inference time by about 20 %.
Ablation studies confirm the necessity of each design choice: removing group convolution leads to severe over‑fitting, discarding progressive upsampling degrades high‑factor SR performance, and omitting the spectral attention module harms spectral fidelity.
In summary, SSPSR introduces a “spatial‑spectral prior” paradigm that jointly exploits spatial textures and inter‑band correlations while remaining computationally efficient and robust to limited training data. The code is publicly released, facilitating reproducibility and future extensions such as multi‑frame HSI SR, temporal HSI sequences, or integration with sensor‑specific noise models. The work represents a significant step toward practical, high‑quality hyperspectral super‑resolution without reliance on auxiliary high‑resolution modalities.
Comments & Academic Discussion
Loading comments...
Leave a Comment