Latent-variable Private Information Retrieval
In many applications, content accessed by users (movies, videos, news articles, etc.) can leak sensitive latent attributes, such as religious and political views, sexual orientation, ethnicity, gender, and others. To prevent such information leakage, the goal of classical PIR is to hide the identity of the content/message being accessed, which subsequently also hides the latent attributes. This solution, while private, can be too costly, particularly, when perfect (information-theoretic) privacy constraints are imposed. For instance, for a single database holding $K$ messages, privately retrieving one message is possible if and only if the user downloads the entire database of $K$ messages. Retrieving content privately, however, may not be necessary to perfectly hide the latent attributes. Motivated by the above, we formulate and study the problem of latent-variable private information retrieval (LV-PIR), which aims at allowing the user efficiently retrieve one out of $K$ messages (indexed by $\theta$) without revealing any information about the latent variable (modeled by $S$). We focus on the practically relevant setting of a single database and show that one can significantly reduce the download cost of LV-PIR (compared to the classical PIR) based on the correlation between $\theta$ and $S$. We present a general scheme for LV-PIR as a function of the statistical relationship between $\theta$ and $S$, and also provide new results on the capacity/download cost of LV-PIR. Several open problems and new directions are also discussed.
💡 Research Summary
This paper introduces and formalizes a novel framework called Latent-variable Private Information Retrieval (LV-PIR), which addresses a critical privacy-efficiency trade-off in secure data retrieval. The motivating problem is that a user’s access to certain content (e.g., movies, news articles) can reveal sensitive latent attributes about them, such as political views or religious affiliation. Classical information-theoretic Private Information Retrieval (PIR) prevents this by completely hiding the index of the requested message, which inherently hides any correlated latent variable. However, in the canonical single-database setting, this perfect privacy comes at the prohibitive cost of requiring the user to download the entire database to retrieve one message.
The authors’ key insight is that perfect secrecy of the message index (θ) may be an overly strict requirement if the ultimate goal is to protect the latent variable (S). LV-PIR relaxes the privacy objective: it guarantees that no information about the sensitive latent variable S is leaked to the database, while still allowing the user to efficiently retrieve one of K messages. The privacy condition is defined information-theoretically as ensuring zero mutual information between the database’s view (query and answer) and the latent variable S.
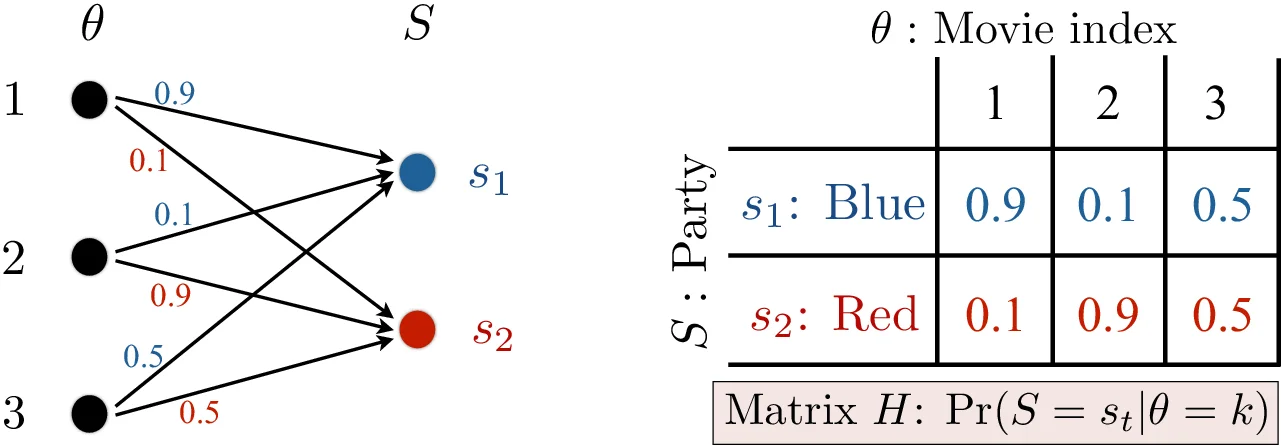
The core technical contribution lies in leveraging the statistical correlation between the message index Θ and the latent variable S, modeled by a conditional probability matrix H where H_{s,k} = Pr(S=s | Θ=k). The proposed LV-PIR scheme exploits the structure of this matrix. For a given latent variable value s, there is a set of message indices that could potentially lead to it. The user’s query is designed to always appear as a request for a message within this “plausible set” corresponding to a fixed, obfuscated value of S. By doing so, the database’s response is constrained to information encoded over this plausible set, not the entire database. This effectively hides S, as the query reveals nothing beyond a fixed, pre-determined latent state. Concurrently, the download cost is reduced because the user only needs to download data proportional to the size of this plausible set, which can be significantly smaller than K.
The paper provides a general coding scheme based on this principle and analyzes the fundamental limits of LV-PIR. A key result is the characterization of the capacity (the maximum achievable download rate) of LV-PIR. The authors show that the capacity is lower-bounded by the conditional entropy H(Θ|S), which represents the remaining uncertainty about the desired message index even when the latent variable is known. This value can be substantially larger than the classical PIR capacity of 1/K, demonstrating the potential for dramatic efficiency gains when the correlation between Θ and S is strong. The work rigorously establishes a new privacy-efficiency trade-off where redefining the privacy constraint (from hiding Θ to hiding S) enables significant performance improvements. The discussion concludes by outlining promising future directions, including extensions to multi-database settings, more general privacy metrics, and practical considerations for modeling real-world correlations.
Comments & Academic Discussion
Loading comments...
Leave a Comment