Unpaired Motion Style Transfer from Video to Animation
💡 Research Summary
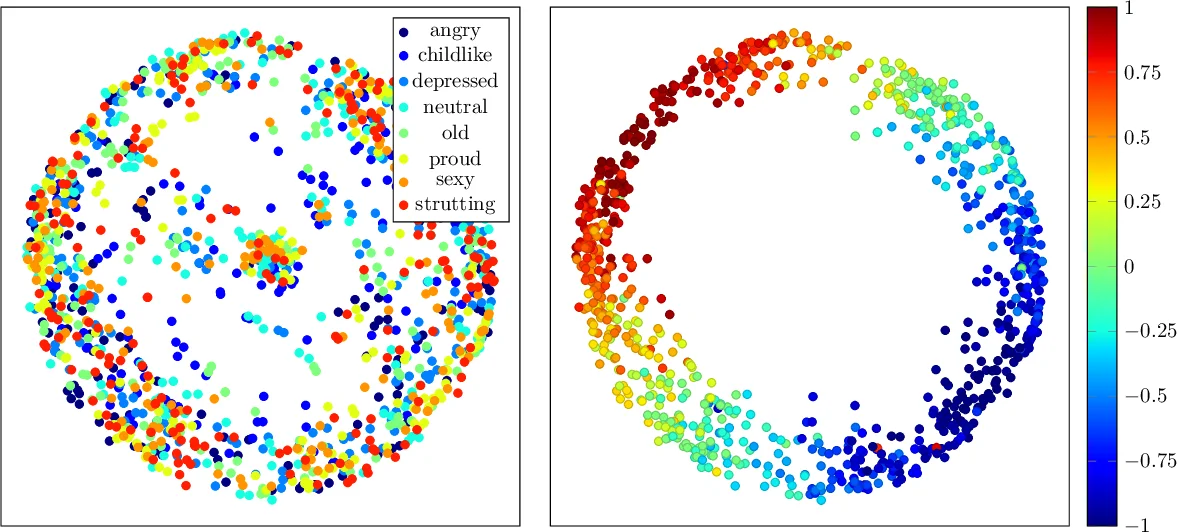
The paper tackles the long‑standing problem of motion style transfer without relying on paired or heavily annotated datasets. The authors propose a generative framework that learns from an unpaired collection of motion clips, each labeled only with a style tag. The core idea is to disentangle a motion sequence into two latent codes: a content code that captures the underlying kinematic trajectory, and a style code that encodes stylistic attributes such as rhythm, amplitude, and emotional tone.
The content encoder processes 3‑D joint rotations using a stack of temporal convolutional layers, producing a high‑dimensional time‑series feature map. The style encoder can ingest either 3‑D joint positions or 2‑D joint projections extracted from ordinary video; two separate encoders are trained to map both modalities into a shared style embedding space. This joint embedding enables the system to extract style directly from video frames, bypassing any 3‑D reconstruction pipeline.
During decoding, the content feature map is transformed back into joint rotations by further temporal convolutions. Crucially, the style code modifies only the second‑order statistics (mean and variance) of each channel of the deep feature map via temporally‑invariant Adaptive Instance Normalization (AdaIN). By keeping the temporal shape of the features unchanged while adjusting their statistics, AdaIN injects the desired style without disturbing the motion’s geometric structure. This is an adaptation of the AdaIN mechanism originally introduced for image style transfer, now extended to the temporal domain.
Training is driven by two complementary losses. A content consistency loss forces the network to reconstruct the original motion when the style input shares the same label as the content input, ensuring that the content code truly captures motion geometry. A style separation loss encourages distinct style codes for clips with different style labels, promoting a clean factorization. Instance normalization in the encoders and a limited dimensionality for the content code prevent the trivial solution of copying the input directly.
The authors evaluate the method on standard motion capture datasets and compare it against state‑of‑the‑art paired approaches. Quantitative metrics (e.g., style classification accuracy, reconstruction error) and qualitative visualizations show that the unpaired model matches or exceeds the performance of supervised baselines. More importantly, the system can transfer unseen styles at test time, using as few as a single reference clip, and can extract styles from 2‑D video footage alone. The paper also demonstrates style interpolation and a notion of “style distance” within the learned embedding, highlighting the flexibility of the representation.
Overall, the contribution lies in (i) eliminating the need for paired motion data, (ii) enabling few‑shot or even one‑shot style transfer for previously unseen styles, and (iii) allowing style extraction directly from video without 3‑D reconstruction. The combination of temporal convolutions, AdaIN‑based style modulation, and a shared 2‑D/3‑D style embedding makes the approach both technically novel and practically valuable for interactive character animation in games, film, and virtual reality.
Comments & Academic Discussion
Loading comments...
Leave a Comment