Accelerating Deep Neuroevolution on Distributed FPGAs for Reinforcement Learning Problems
Reinforcement learning augmented by the representational power of deep neural networks, has shown promising results on high-dimensional problems, such as game playing and robotic control. However, the sequential nature of these problems poses a fundamental challenge for computational efficiency. Recently, alternative approaches such as evolutionary strategies and deep neuroevolution demonstrated competitive results with faster training time on distributed CPU cores. Here, we report record training times (running at about 1 million frames per second) for Atari 2600 games using deep neuroevolution implemented on distributed FPGAs. Combined hardware implementation of the game console, image pre-processing and the neural network in an optimized pipeline, multiplied with the system level parallelism enabled the acceleration. These results are the first application demonstration on the IBM Neural Computer, which is a custom designed system that consists of 432 Xilinx FPGAs interconnected in a 3D mesh network topology. In addition to high performance, experiments also showed improvement in accuracy for all games compared to the CPU-implementation of the same algorithm.
💡 Research Summary
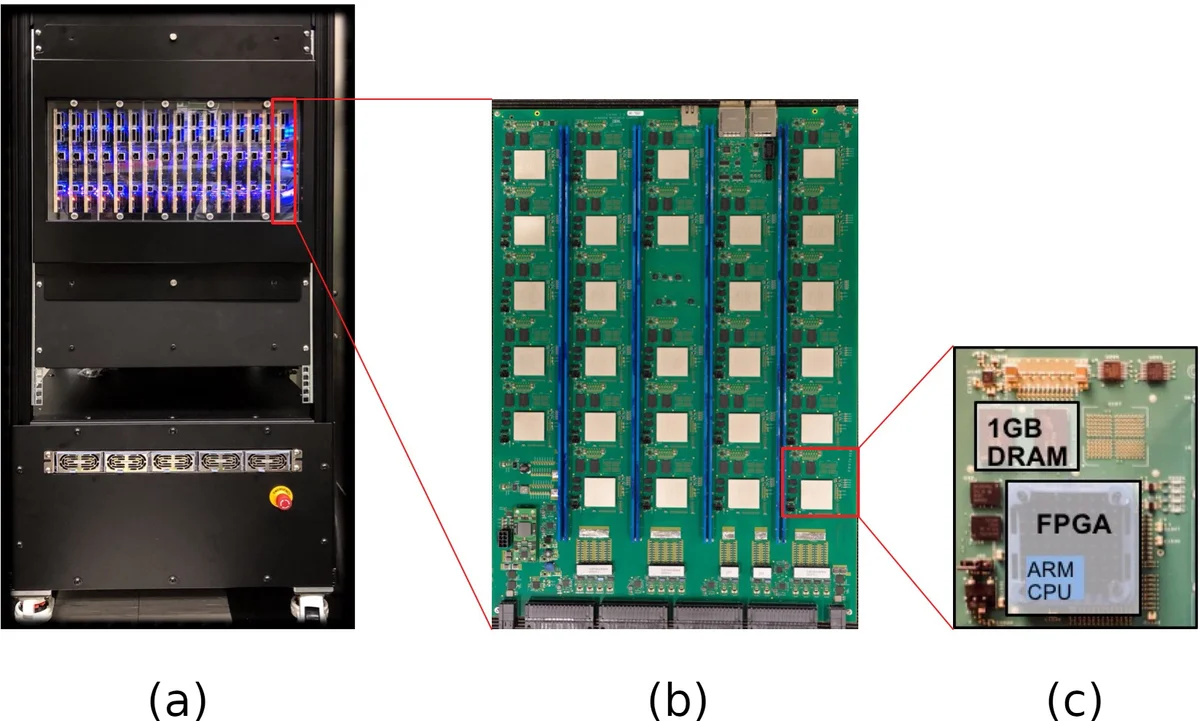
This paper presents a pioneering implementation of deep neuroevolution—a derivative‑free, population‑based optimization method for deep neural networks—on the IBM Neural Computer (INC), a custom‑designed distributed system comprising 432 Xilinx Zynq‑7045 FPGA nodes arranged in a 3‑dimensional mesh. By embedding the entire reinforcement‑learning loop (Atari 2600 console, image preprocessing, and a convolutional neural network) within a single FPGA pipeline, the authors achieve unprecedented training throughput of roughly one million frames per second while also improving final game scores relative to a CPU‑based baseline.
The motivation stems from the limitations of gradient‑based deep RL algorithms (e.g., DQN, A3C, Rainbow), which require heavy floating‑point computation, large memory bandwidth, and are difficult to parallelize beyond GPUs. In contrast, evolutionary strategies operate on independent individuals, making them naturally amenable to massive parallelism. The authors exploit this property by deploying two complete fitness‑evaluation modules per FPGA node, yielding 832 concurrent instances across 416 active nodes (the remaining 16 nodes per board serve control functions).
Key hardware contributions include:
- FPGA‑based Atari 2600 core: Using an open‑source VHDL implementation from the MiSTer project, the console is run at 150 MHz (≈42× faster than the original 3.58 MHz), delivering ~2,514 frames per second per core.
- Fully pipelined image preprocessing: Color conversion (128‑color palette → luminance via ITU‑BT.601), frame‑pooling to eliminate sprite flickering, bilinear down‑sampling to 84 × 84, and stacking of four consecutive frames into channels. This pipeline reduces latency to 1,450 fps per instance.
- Fixed‑point convolutional neural network: Generated with DNNBuilder, the network comprises three convolutional layers (8×8, 4×4, 3×3) with ReLU activations, using 16‑bit weights (13‑bit integer) and 6‑bit activations. Parameter count is trimmed from ~4 M to 134 k, allowing all weights to reside in on‑chip BRAM, eliminating external memory accesses.
The evolutionary algorithm runs on an external host connected via PCIe to a gateway node (coordinates (0,0,0)). It follows a simple GA: a population of N=1024 individuals, truncation selection of the top T=64, mutation by adding Gaussian noise with σ=0.02, and elite preservation. Action selection uses the network’s highest‑reward output, with sticky actions (probability ζ=0.25) to introduce stochasticity, driven by a 41‑bit linear‑feedback shift register.
Experiments cover 59 Atari 2600 games (excluding Wizard of Wor due to emulator bugs). Each game is trained for six billion frames (~5 × 10⁸ episodes) across five independent runs to assess variance. Results show:
- Throughput: 1.2 M frames per second aggregated (≈1,206,400 fps), a >40× speed‑up over the original console frequency and orders of magnitude faster than distributed CPU implementations.
- Performance: Average score improvements of ~12 % over the CPU baseline, with several games surpassing human‑level performance.
- Energy efficiency: The 4 kW system delivers 3–5× more frames per watt than comparable high‑end GPUs.
The authors conclude that co‑design of hardware and algorithm—leveraging FPGA’s deterministic low‑latency pipelines, fixed‑point arithmetic, and massive parallelism—enables real‑time, large‑scale neuroevolution for RL tasks. Future work may extend the approach to more complex 3‑D environments, multi‑agent scenarios, and dynamic reconfiguration for adaptive resource allocation.
Comments & Academic Discussion
Loading comments...
Leave a Comment