A Crowdsourcing Framework for On-Device Federated Learning
Federated learning (FL) rests on the notion of training a global model in a decentralized manner. Under this setting, mobile devices perform computations on their local data before uploading the required updates to improve the global model. However, …
Authors: Shashi Raj P, ey, Nguyen H. Tran
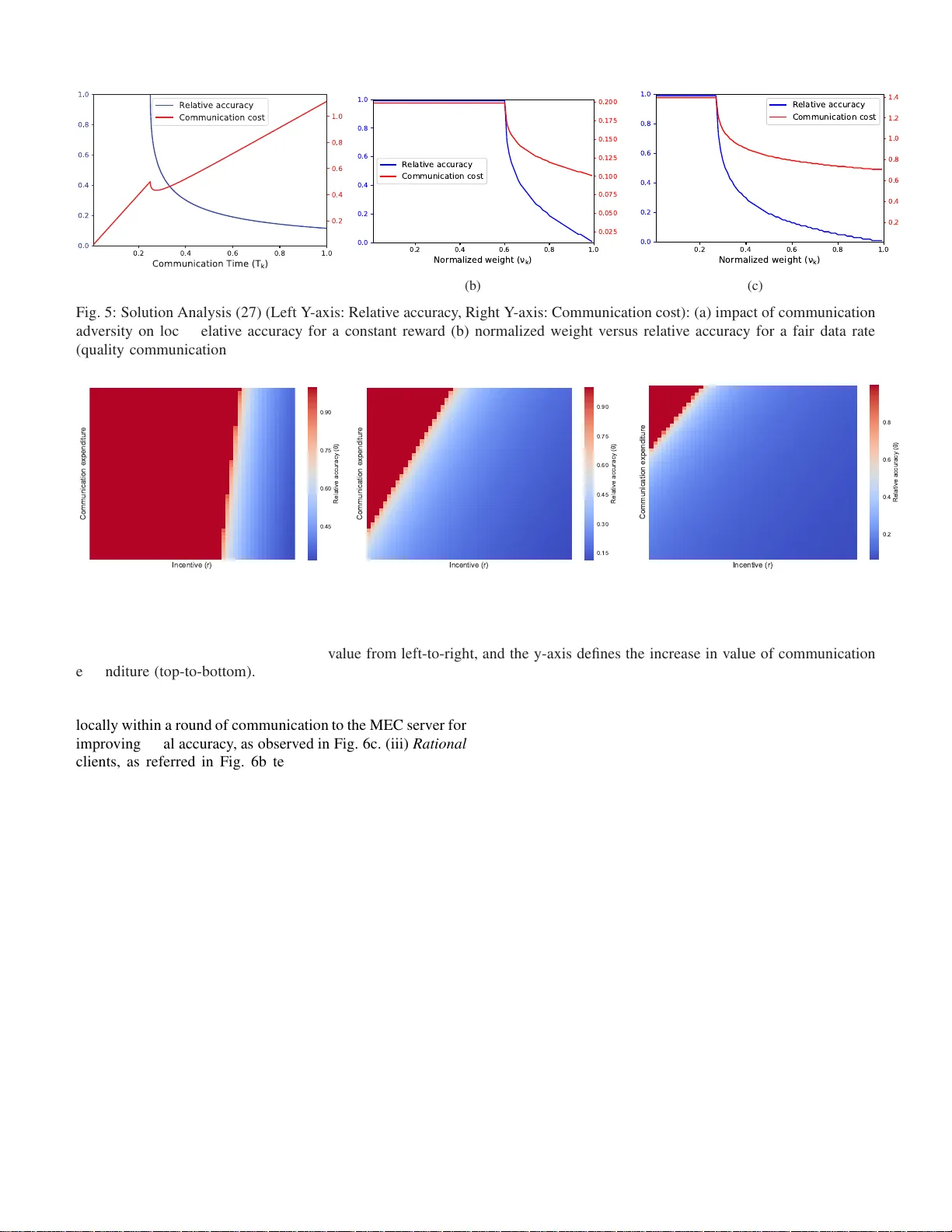
1 A Cro wdsourcing Frame w ork for On-De vice Federated Learning Shashi Raj Pandey , Student Member , IEEE, Nguyen H. Tran, Sen ior Memb er , IEEE, Mehdi Ben nis, S e - nior Member , IEEE, Y an Kyaw T un , Au nas Manzoor , a nd Choong Seon Hon g, Senior Member , IEEE Abstract —Federa ted learning (FL) rests on th e notion of training a global model in a decentralized manner . Under this setting, mobile devices perform co mputations on th eir local data befor e uploading the required updates to improv e the global model. Howev er , when the particip ating clients implement an uncoordinated computation strategy , the difficulty is to h andle the communication efficiency (i.e., the numb er of comm uni- cations per iteration) while exchanging the model parameters during aggr egation. Therefo re, a key challen ge in FL is how users participate to build a high-quality global model with communication efficiency . W e tackle this issue by f ormulating a utility maximization problem, and p ropose a n ov el crowdsourcing framewo rk to lev erage FL that consid ers th e communication effi- ciency du ring parameters exchange. First, we show an incentive- based i n teraction between th e crowdsourc ing platform and the participating client’s i ndependen t strategies for training a global learning model, where each sid e maximizes i t s own benefi t. W e fo rmulate a two-stage Stackelberg game to analyze such scenario and fi nd the game’ s equilib ria. Second, we fo rmalize an admission control scheme f or participating clients to ensure a level of local accuracy . S imulated results demonstrate the efficacy of our proposed soluti on with up to 22 % gain in t h e offered reward. Index T erms —Decentralized machine lear ning, f ed erated learning (FL), mobile cro wdsourcing, incentive mechanism, Stackelberg game. I . I N T RO D U C T I O N A. Ba ckgr ound and motiva tion Recent years have admittedly witnessed a tr e mendou s growth in the use of M achine Learnin g ( ML) technique s and Manuscript recei ve d May 19, 2019; revised September 7, 2019, De- cember 17, 2019 and January 13, 2020; accepte d January 28, 2020. Date of publica tion......; date of current version ....T his work was supported by Institut e of Informatio n & communicat ions T echnology Planning & Ev aluation (IITP) grant funded by the Korea gove rnment (MSIT) (No. 2019-0-01287, Evolv able Deep Learning Model Generati on Platform for Edge Computing) and the National Research Foundat ion of Korea (NRF) grant funded by the Ko rea gov ernment (MSIT) (NRF-2017R1A2A2A0500 0995). A prelimina ry versi on of this work has been presented at IE E E GLOBECOM 2019 [1]. (Corr esponding author: Choong Seon Hong.) Shashi Raj Pandey , Y an Kya w Tun, Aunas Manzoor , and Choong Seon Hong are with the Department of Computer Sci ence and Engineering, Ky ung Hee Unive rsity , Y ongin-si, Gyeonggi-do 17104, Rep. of Korea, e-mail: { shashiraj , ykya wtun7, aunasmanzoor , cshong } @khu.ac .kr. Nguyen H. Tran is with the School of Computer Science, The Univ ersity of Sydney , NSW 2006, Australia, and also with the Department of Computer Science and Engineerin g, Kyun g Hee Univ ersity , Seoul 17104, South Kor ea (email: nguyen.tran@ sydney .edu.au). Mehdi Benni s is with the Center for W ireless Communicati ons, Univ ersity of Oulu, 90014 Oulu, Finland, and also with the Department of Computer Science and Engineerin g, Kyun g Hee Univ ersity , Seoul 17104, South Kor ea (email: mehdi.bennis@ou lu.fi). its ap plications in mobile d evices. On o ne han d, accor ding to Internatio nal Data Corpor ation, the shipments of smartp h ones reached 3 billion s in 2018 [2], which implies a l arge cr owd of mobile u sers generating perso nalized data via interaction with m obile applicatio n s, or with th e use of in- built sensors (e.g., cameras, microp hones and GPS) exploited efficiently by mobile cr owdsensing parad igm (e.g., for ind oor lo calization, traffic mon itoring, navigation [3], [4], [5], [6]). On the oth er hand, mob ile d evices are g etting empowered extensively with specialized hard ware arch itectures an d com puting en gines such as the CPU, GPU and DSP (e.g ., energy efficient Qualcomm Hexagon V ector eXtensions o n Snap drago n 8 35 [7]) f or s olving di verse machin e learnin g problems. Gartn er predicts that 80 percent of sm a rtphon es will h ave o n-device AI capabilities by 202 2. W ith d e dicated chipsets, it will em power smartphon e makers to achieve market gain by offering mo re secured facial recogn itio n system, the ability to u nderstand user b ehaviors an d o ffer pre d ictiv e future [8 ]. This m eans on- device intelligence will be ubiqu itous! In the backd rop to these exciting possibilities with on- device intelligen ce, a White House report on princip le of da ta minimization had been published in 201 2 to advocate the priv acy of consumer data [9]. The direct application of this is the ML tech nique that leav es the train in g data distributed on the m obile devices, called F ed erated Learn ing [7 ], [10], [11], [12], [1 3]. Th is te c h nique unleashes a new collabora tive ecosystem in ML to b uild a shared learning model while keep - ing the train ing data lo cally on u ser d evices, w h ich comp lies with the data minim iza tion principle and pro tects user data priv acy . Unlike the conv entional ap proach es of collecting all the trainin g data in one place to train a learnin g model, the mobile users (p a rticipating clients) perf orm co mputation for the updates on th eir local trainin g data with th e curren t glob al model parameters, which are then aggregated an d bro adcasted back by the c entralized coord inating server . This is an iterati ve process that und ergoes until an accu racy level o f the learning model is r eached. By th is way , FL deco u ples the trainin g process to learn a global model by eliminating the mob ility of local tr a ining data. In another report, research organizatio ns estimate that over 90% of the da ta will be stored and processed locally [1 4] (e. g., at the network edge) , which pr ovides an immen se expo su re to extract the benefits of FL. Also, b ecause of the hug e mar ket potential o f the un tapped private data, FL is a pro m ising tool to explo it mor e p e r sonalized service orien ted ap plications. Local compu tations at th e d evices and their comm unication 2 with the centralized co ordinatin g server are inter leav ed in a complex man ner to build a g lobal learning model. Therefo re, a commu nication-e fficient FL f r amework [ 12], [ 15] requ ires solving sev eral ch allenges. Furth ermore , be c ause of limited data p e r device to train a high -quality lea r ning mode l, the difficulty is to incentivize a large n umber o f mo bile users to ensur e co operatio n . This imp ortant aspect in FL has b e e n overlooked so far , where the q uestion is h ow can we motivate a number of participating clients, co llectively pr oviding a lar ge number o f da ta samples to en able FL witho ut sh aring their private data? Note th a t, b o th par ticip ating clients and the server can ben efit from training a g lobal model. Howe ver, to f ully reap th e benefits of h igh-qu ality upd ates, th e multi- access edge computing (MEC) server has to incentivize clients for participatio n. In p articular, under hetero geneou s scenarios, such as a n ad a p tiv e and cognitive-communication network, client’ s particip ation in FL can spu r collabora tio n and p rovide benefits for ope r ators to accelerate an d d eliv er n e twork-wide services [16]. Similarly , clients in g eneral a re n ot con cerned with the reliability an d scalab ility issues of FL [ 17]. Th erefor e, to incentivize users to par ticipate in the co llaborative training, we require a market place. For this purp o se, we presen t a value-based comp ensation m e chanism to the participatin g clients, such as a b ounty (e. g., data discount pack age), as p er their lev el of participatio n in the crowdsourcing framework. This is reflected in term s o f local accu racy level, i.e. , quality of solution to th e local subp r oblem , in which the framework will protect the mod el from imper fect upd ates b y restricting the clients try ing to compr omise the mod el ( for instance, with ske wed data because of its i.i.d natu re or data poison ing) [3]. Moreover , we cast the global loss min imization prob lem as a p rimal-du al optimization pr oblem, in stead of adopting traditional gradien t d escent learning algo r ithm in the federated learning setting (e.g., Fed A v g [15]). This enables in (a) p roper assessment of the quality of the local solution to improve personalizatio n and fairness amongst the pa r ticipating clien ts while tra ining a glob al model, (b ) effective d ecouplin g of the local solvers, ther eby b alancing com munication and com puta- tion in the distributed setting. The goal o f this pa per is two-fold: First, we for malize an incentive me chanism to d ev elop a par ticipatory fr amew ork for mobile clien ts to perf o rm FL f or imp r oving th e glo bal mod el. Second, we addr e ss the challen g e of maintain ing co mmunica - tion efficiency while exchanging the mo del para meters with a nu mber of par ticipating clien ts dur ing aggregation . Spec ifi- cally , commu nication efficiency in this scen ario accoun ts for commun ications per iteratio n with an arb itrary algorith m to maintain an acceptable accuracy level for the glob al mode l. B. Con tributions In this work, we d esign and an alyze a n ovel crowdsourcin g framework to realize the FL vision. Specifically , o u r con tribu- tions are summarized as follows: • A crowdsourcing framework to enable c o mmunication -efficient FL . W e d esign a crowdsourcing framework, in which FL p articipating clients iter ativ ely solve the local learning subp roblems f or an accuracy lev el subject to an offered incentive. W e then establish a c o mmun ic a tion- efficient co st model f o r the p articipating clients. W e th en formu late an incentive mechanism to induce th e n e cessary interaction be tween the MEC server and the participating clients fo r th e FL in Section IV . • Solution a pproach using Stackelberg game . W ith the offered incentive, the p articipating clien ts indepe n dently choose their strategies to solve th e loca l su bprob lem for a cer tain accuracy level in orde r to m inimize the ir p a rtic- ipation co sts. Correspon dingly , the MEC server builds a high q uality ce n tralized m odel ch aracterized by its utility function , with the data distributed over the par ticipating clients by offering the rew ard. W e exp lo it this tig htly coupled m otiv es of th e p articipating clien ts and the MEC server as a two-stage Stackelberg game. Th e equ ivalent optimization problem is character ized a s a mixed- boolean progr amming wh ich req uires an exponen tial co m plexity effort f or fin ding the solution . W e a n alyze the game’ s equilibria and prop ose a lin e a r co mplexity algor ith m to obtain th e optimal solution. • Participant’s response analysis and case study . W e next ana lyze the r e sponse beh avior of the particip a ting clients via the solutio ns of the Stackelberg g a me, an d establish the efficacy of ou r proposed framework via case stud ies. W e show that the lin ear-complexity solu tio n approa c h attains the same p e r forman ce as the mixed- boolean pro grammin g p roblem . Furth ermore, we show that o ur m echanism d esign can ach iev e th e o ptimal solution wh ile outperform ing a heuristic approach for attaining the max im al utility with up to 2 2% of gain in the o ffered rew ard. • Admission co ntrol strateg y . Finally , we show that it is significant to have certain par ticipating clients to guaran - tee the commun ication efficiency f or an a c curacy lev el in FL. W e fo rmulate a prob a b ilistic m odel fo r thr eshold accuracy estimatio n a n d find the correspo nding numb er of particip ation required to build a hig h -quality learning model. W e analyze the impact of th e num b er of p artic- ipation in FL while d etermining the th reshold accur acy lev el with closed-f orm solu tions. Finally , with num erical results we demon strate the structure o f admission contro l model fo r d ifferent configu r ations. The remaind er of this pap er is o rgan ized as follows. W e revie w related work in Section II, and present the system model in Section I II. In Section IV , we fo rmulate a n incentive mechanism with a two-stage Stackelberg game, an d inv estigate the Nash eq uilibrium o f th e g ame with simulation results in Section V . An ad mission con trol strategy is formulated to define a minimum local acc uracy level, and numer ica l analysis is p resented in Section VI . Finally , co nclusions ar e drawn in Section VII. I I . R E L A T E D W O R K The un precede n ted a m ount of data necessitates the use o f distributed comp utational framework to provide solutions f o r various machin e lear ning application s [1 1]–[15]. Using dis- tributed optimization techn iq ues, researches on decentr a lized 3 machine learning largely focused on com p etitiv e a lg orithms to train learnin g m odels the numbe r of cluster nod e s [ 18], [19], [20], [21], with balanced and i.i.d data. Setting a d ifferent motiv ation, FL recently has attracted an increasing interest [7], [11], [12], [13], [15], [22] in which collaboratio n of the number of d evices with non-i.i.d and unbalan c ed data is adapted to train a learn ing mo del. In th e pioneerin g work s [1 1], [12], the autho rs presented the setting for fed erated o ptimization, an d related technical challeng es to understan d th e conver gence pro perties in FL. Existing work studied these issues. For example, W a n g, Shiqiang , et a l. [16] theoretically a nalyzed the c o n vergence rate of the distributed gradient de scen t. In this detailed work , the auth ors focus on deducin g the optimal glob al agg regation fr equency in a distributed learnin g setting to minim ize the loss fu n ction of the global pro b lem. Th eir problem co nsiders resource constrain e d edge comp uting system. Ho wev er , the setting d iffers with our pro p osed model where we h ave introdu ced the n otion of participatio n , an d propo sed a gam e theo r etic inter a c tion between the workers (par ticipating clien ts) an d th e m aster (MEC server) to attain a cost effective FL framework. E a rlier to this work, Mc M ahan, H. Bren dan, et al. in [1 5] prop osed a practical variant of FL where the glo b al aggr egatio n was synchro n ous with a fixed frequency . The authors confir m ed the effecti vene ss of th is appr oach u sing various datasets. Further- more, authors in [ 18] extended th e th eoretical tra ining c o n ver- gence analysis resu lts of [ 15] to genera l classes of d istributed learning appr o aches with co mmunicatio n and compu tatio n cost. For the deep learnin g architectur e where the objectives are no n-conve x, au thors in [ 23] propo sed an algorith m namely FedProx, a special case of Fed A v g where a surr ogate of the global objective functio n was used to efficiently ensure the empirical perfo rmance bou nd in FL setting. I n this work , the authors demo nstrated th e im provement in per forman ce as in their theo r etical assumption s, bo th in term s of ro bustness and conv ergence thro ugh a set of experimen ts. Recent work s adapt and extend th e co re con cepts in [11], [12], [1 5] to develop a com munication -efficient FL algor ithm, where each participatin g clients in the fed erated learning setting inde penden tly comp utes their local u p dates on the current model and com municates with a central server to aggregate the parameter s fo r the com p utation of a glo bal model. The fr amew ork uses Feder ated A veraging (FedA vg) algorithm to reduce comm unication costs. I n these regard, to characterize the comm unication and computation trade- off durin g m odel updates, distributed mach ine learnin g based on gradien t descent is widely used. In the m entioned work [11], a v ariant o f distributed stochastic gradien t descen t (SGD) was used to attain p arallelism and improved co mputation . Similarly , in [12], th e autho r s d iscussed abou t a family o f new rand omized meth ods combinin g SGD, with prim al an d dual variants such a s Sto chastic V ariance Reduced Gradien t (SVRG), Feder ated Stoch astic V ariance Reduced Gradient (FSVRG) and Stochastic Dual Coor dinate Ascent (SDCA). Further, in [24] th e au thors explained abo ut th e red undan cy in grad ient exchan ges in distributed SGD, and p roposed a Deep Gradien t Compre ssion (DGC) algo rithm to enhance commun ication efficiency in FL setting. The perfor m ance of parallel SGD and mini-b atch parallel SGD h ad been discussed in [25], [23] for fast con vergence an d ef fectiv e com munication round s. Howev er , autho rs in their recent work [25] argu e for the sufficient improvement in gene r alization perform ance with the v ariant of local SGD rather than th e large mini-b atch sizes, ev en in a n on-convex setting . In [ 2 6], th e author s propo sed the Distributed Ap proxim a te Newton (D ANE) alg orithm for precisely solvin g a general subp roblem av ailab le locally befo re av eraging their solutions. In th e recent work [27], th e autho r s designed a r obust me th od which applies the pr o posed p eriodic- av eraging SGD (P ASGD) techn ique to prev ent commu nication delay in the d istributed SGD setting. Th e idea in this work was to adap t the comm unication perio d such that it minimizes the optimiz a tio n error at each wall-clock time. T o this end, interestingly , in som e of the latest works such as [2 8], the authors have well-studied an d demo nstrated the priv acy risk scenario u n der collabor ated learning mechanism such as FL. In con trast to the ab ove research tha t has overlooked the participator y me th od to build a high- quality central ML model and its criticality , and p rimarily focu sed on the convergence of learning time with variants of learning algo rithms, our work a d dresses the challeng e in designin g a commu nication and computation al cost effecti ve FL framework b y explo ring a crowdsourcing structure. In this regard, few r e cent stud- ies h ave discu ssed about the participatio n to build a global ML mo del with FL as in [29], [30]. Basically , in [29] the authors pro posed a n ovel distributed appr oach based o n FL to lear n the network- wide qu e ue dyn amics in vehicu lar net- works for achieving ultra-reliab le low-latency commun ication (URLLC) v ia a jo int power and resou rce allocatio n prob lem. The veh ic les p articipate in FL to pr ovide in formatio n r e lated to sample events (i.e., qu eue lengths) to parameterize the distribution of extremes. In [30], the a uthors pr ovided new design principles to character ize edge-lear ning and highlighted importan t research opportun ities and applications with the new philosoph y f o r wireless commu nication called learning -driven communica tion . The author s also presented some of the signifi- cant case stud ies and demonstrated the effecti veness of d esign principles in this regards. Further, r e cent work [1 7] studied the bloc k -chained FL architectu re propo sing th e d ata reward and min ing reward m echanism f or FL. Howe ver , these works largely p rovide a laten cy analy sis for the r elated app lications. Our pap er f ocuses on the Stackelberg game-b ased incen ti ve mechanism d esign to r eveal the iteration strate g y of the par- ticipating clients by solving the loca l sub problem s f or build- ing a high -quality c e ntralized lear n ing model. Inter e stingly , incentive mechan ism has been studied for years in mo bile crowdsourcing/crowdsensing systems, esp ecially with auction mechanisms (e.g ., [ 31], [32], [33]), con tract a n d tou r nament models ( e .g, [34], [ 35]) and Stackelberg game-b ased incentive mechanisms suc h as in [36] an d [ 37]. However , the design goals were specific towards fair an d truth f ul data trading of distributed sensing tasks. In this regard, the novelty of our model is that we untangle and an a lyze the complex interaction scenario b etween the particip ating clients and the aggregating edge server in th e crowdsourcing framework to ob tain a cost- effecti ve global learnin g mod el with o ut sharing local datasets. Moreover , th e proposed incen ti ve mech anism mo d els such 4 MEC Server Plat f o r m t fo r m Loca l Model s local train i ng Glob a l Mode l Aggr e gator local parame ters pass o n glob al mo del para m eter L MBS- MUs assoc i ation Back haul Loca l data Parti cipatin g clien t s Fig. 1: Crowdsourcing fra mew ork for dec e n tralized m achine learning. interactions to e n able commu nication- efficient FL, wh ich is able to achieve a target accu racy , in considera tio n with the perfor mance metrics. Fur th er , we adopt the dual fo rmulation of the lear ning p roblem to better decom pose the global p roblem into distributed subp roblem s for fe derated comp utation acro ss the participa tin g c lients. I I I . S Y S T E M M O D E L Fig. 1 illustrate s our prop osed system model fo r th e crowd- sourcing framework to enab le FL. The mod e l con sists of a number of mobile clients associated with a b a se station h aving a cen tral coo rdinating server (MEC ser ver), acting a s a central entity . The server facilitates the computa tio n o f the para m eters aggregation, and feedbac k the glob al m o del updates in ea c h global iteration. W e consider a set of p articipating clients K = { 1 , 2 , . . . , K } in the crowdsourcing framework. The crowdsourcer (platfo rm) ca n in teract with m obile clients via an ap plication interface, and aims at leveraging FL to build a global ML mod el. As an example, consider a case wher e the crowdsourcer ( r eferred to as MEC ser ver he reafter, to av oid any confu sion) wants to build a ML mod el. Instead of just relying on av ailab le local d ata to train the glo bal mod el at the MEC server , the global model is constructed utilizin g the local training data available acro ss several d istributed mobile clien ts. Here, the g lo bal model parame te r is first sha r ed by the MEC server to train the lo cal mod e ls in each p a rticipating client. The local mod el’ s parame ters minimizing lo cal loss func tio ns are then sen t back as feedback , and ar e aggregated to update the g lobal model parameter . Th e proce ss co ntinues iteratively , until c o n vergence. A. F ederated Learnin g Backgr ou n d For FL, we consider unevenly partitioned tr a ining d ata over a large number of participa tin g clients to tr ain the local models under any arbitrar y learnin g algorithm . Each clien t k stores its loc al dataset D k of size D k respectively . Then , we d efine the training da ta size D = P K k =1 D k . In a typ ical superv ised learning setting , D k defines th e collection of data sam ples giv en as a set of input-ou tput pairs { x i , y i } D k i =1 , where x i ∈ R d is an inp ut sample vector with d features, a n d y i ∈ R is the labeled output value fo r th e sample x i . The learning problem , fo r an inp ut sample vector x i (e.g., th e pixels o f an image) is to find the mod el parameter vector w ∈ R d Algorithm 1 Federated Lea r ning Fra mew ork 1: Input: In itialize du al variable α 0 ∈ R D , D k , ∀ k ∈ K . 2: for each ag gregation r o und do 3: for k ∈ K do 4: Solve local subpr oblems (5 ) in par allel. 5: Update local variables as in (7). 6: end for 7: Aggregate to upd ate g lobal par ameter as in (8 ). 8: end for that chara c te r izes the ou tput y i (e.g., the lab eled ou tput of the image, such as the corr espondin g produ ct n ames in a store) with the loss fu nction f i ( w ) . Some examples of loss fun c tions include f i ( w ) = 1 2 ( x T i w − y i ) 2 , y i ∈ R for a linea r regre ssion problem and f i ( w ) = max { 0 , 1 − y i x T i w } , y i ∈ {− 1 , 1 } for support vector machine s. T he term x T i w is often called a linear mapping functio n . Therefo re, the loss functio n b ased on the local data of client k , termed local subprob lem is f o rmulated as J k ( w ) = 1 D k X D k i =1 f i ( w ) + λg ( w ) , (1) where w ∈ R d is th e local model p arameter, and g ( · ) is a regularizer f unction, commo nly expre ssed as g ( · ) = 1 2 k·k 2 ; ∀ λ ∈ [0 , 1] . This character izes the local mod el in the FL setting. Global Prob lem : At the M E C server, the g lobal prob lem can b e represen ted as the finite-sum objec tive o f th e form min w ∈ R d J ( w ) where J ( w ) ≡ P K k =1 D k J k ( w ) D . (2) Problems of such structure as in (2) where we aim to minimize an a verage of K loc al o bjectives are well-kn own as distributed consensus pr ob lems [3 8]. Solution F ra mework under F ederated L earning : W e recast the r egularized glo bal pro blem in ( 2) as min w ∈ R d J ( w ) := 1 D X D i =1 f i ( w ) + λg ( w ) , (3) and decom pose it as a dual op tim ization prob lem 1 in a distributed scenar io [39] am o ngst K participating clien ts. For this, at first, we d efine X ∈ R d × D k as a matr ix with column s having data points for i ∈ D k , ∀ k . Then, the corr espondin g dual op timization pro b lem of (3) f or a conve x lo ss func tion f is max α ∈ R D G ( α ) := 1 D X D i =1 − f ∗ i ( − α i ) − λg ∗ ( φ ( α )) , (4) where α ∈ R D is the dual variable mappin g to the prim al candidate vector , f ∗ i and g ∗ are the conv ex conjuga tes of f i and g respectively [4 0]; φ ( α ) = 1 λD X α . W ith the optimal value of dual variable α ∗ in ( 4 ), we h av e w ( α ∗ ) = ∇ g ∗ ( φ ( α ∗ )) as the optimal solution of (3 ) [ 3 9]. For th e ease of r epresentation , we will u se φ ∈ R d for φ ( α ) hereaf ter . W e con sider th at g is a strongly conve x function , i.e., g ∗ ( · ) is continu ous differentiable. Th en, the solution is obtained following an 1 The duali ty gap pro vides a certificate to the qual ity of loc al solutions and fac ilita tes distrib uted traini ng. 5 iterativ e appro ach to attain a glob al accu racy 0 ≤ ǫ ≤ 1 (i.e. , E [ G ( α ) − G ( α ∗ )] < ǫ ) . Under the distributed setting , we f urther defin e data parti- tioning notations fo r clients k ∈ K to represent the working principle of the fr amew ork. Let us d e fine a weight vector [ k ] ∈ R D at the loca l subp roblem k with its eleme n ts zer o for th e unavailable data points. Following the assumptio n of having f i as (1 /γ ) -smo oth and 1 -strongly con vex of g to ensure convergence, its conseq uences is the appro ximate solution to the local pr o blem k defined by the dual variables α [ k ] , [ k ] , character iz e d as max [ k ] ∈ R D G k ( [ k ] ; φ, α [ k ] ) , (5) where G k ( [ k ] ; φ, α [ k ] ) = − 1 K − h∇ ( λg ∗ ( φ ( α ))) , [ k ] i − λ 2 k 1 λD X [ k ] [ k ] k 2 is defined with a ma trix X [ k ] columns ha ving data points for i ∈ D k , and zer o padded oth erwise. Eac h participating client k ∈ K iterates over its com p utational resources u sing any ar b itrary solver to solve its lo cal prob lem (5) with a local relative θ k accuracy that characterizes th e quality o f th e loc a l solution, and p roduce s a ra n dom ou tp ut [ k ] satisfying E h G k ( ∗ [ k ] ) − G k ( [ k ] ) i ≤ θ k h G k ( ∗ [ k ] ) − G k (0) i . (6) Note that, with local (r elativ e) accura cy θ k ∈ [0 , 1 ] , th e value of θ k = 1 suggests that no impr ovemen t was mad e by the local solvers during successive local iter ations. Th e n , the local d ual variable is updated as follows: α t +1 [ k ] := α t [ k ] + t [ k ] , ∀ k ∈ K . (7) Correspon d ingly , each pa r ticipating client will bro adcast the local param eter d efined as ∆ φ t [ k ] := 1 λD X [ k ] t [ k ] , du ring each round o f co mmunica tio n to the MEC server . T h e MEC server aggregates the local p arameter (averaging) with the following rule: φ t +1 := φ t + 1 K X K k =1 ∆ φ t [ k ] , (8) and distributes the glo bal ch ange in φ to the participatin g clients, which is used to solve (5) in the next r ound of local iterations. This way we o bserve the decoupling of glo bal model param eter fr om the ne ed of local clients’ data 2 for training a global model. Algorithm 1 b riefly summ arizes the FL framework as an iterativ e process to solve the global p roblem char a cterized in (3) for a glo bal acc uracy level. T h e iterative p r ocess (S2)- (S8) of Algorithm 1 term inates when th e globa l accu racy ǫ is r eached. A participatin g clien t k strategically 3 iterates over its local training data D k to solve the loc al sub p roblem (5 ) up to an accuracy θ k . In each commu nication rou n d with the MEC server , the participating clients synchr o nously p a ss o n their par ameters ∆ φ [ k ] using a shared wireless channe l. Th e MEC server the n ag gregates th e loc a l m odel p a r ameters φ a s 2 Note that we consider the ava ilabi lity of quality of data with each partic ipati ng client for solving a correspondi ng local subproblem. Further relate d demonstrati on on dependenc y of the normalized data size and accurac y can be found in [41]. 3 Fe wer iteratio ns might not be sufficie nt to hav e an optimal local solution [16]. Client 1 MEC Server Client 2 ݎǡ Ԅ א Թ ௗ ߠ ʹ ǡ οԄ ଶ Participating Clients (Local Models) Global Model Client K Fig. 2 : In teraction environment o f f ederated learn ing setting under crowdsourcing f ramework. in (8), a n d broad casts th e glob a l p arameters required for the participating clien ts to so lve their local subp roblems for the next commu nication rou n d. W ith in th e framework, co nsider that each participating client uses any arbitrary optimiza- tion algo rithm (su c h as Stochastic Gradient Descen t (S GD) , Stochastic A verage Gradient (SAG), Stochastic V ariance Re- duced Gradien t (S VRG) ) to attain a relative θ accuracy per local subpr oblem. Then , for strong ly c o n vex objectives, the general u pper bo u nd on the num b er of iteratio ns is de p endent on local re lati ve θ accuracy of the local sub p roblem and the global m o del’ s accuracy ǫ as [1 2]: I g ( ǫ, θ ) = ζ · log( 1 ǫ ) 1 − θ , (9) where the local relativ e accur a cy measur e s th e quality of the local solu tion as defined in the earlier p aragrap hs. Fu rther, in this fo r mulation, we have replaced the term O (lo g( 1 ǫ )) in the numerato r with ζ · log( 1 ǫ ) , for a constant ζ > 0 . For fixed iterations I g at the MEC server to solve the global pr oblem, we observe in (9) that a very hig h local accuracy (small θ ) can significantly improve th e global accura cy ǫ . Howev er , e a c h client k has to spend excessive r esources in ter ms of local iterations, I l k to attain a small θ k accuracy as I l k ( θ k ) = γ k log 1 θ k , (10) where γ k > 0 is a param eter choice of clien t k that dep ends on the data size an d conditio n nu m ber of the local subpr oblem [42]. Theref o re, to ad dress this trad e-off, MEC server can setup an e c onomic in teraction environment ( a crowdsourcing framework) to m otiv ate the participating clients for improving the local relative θ k accuracy . Cor respond ingly , with the increased rew ard, th e participating c lien ts are motiv ated to attain better local θ k accuracy , which as obser ved in (9) can improve th e glo bal ǫ accuracy for a fixed nu mber of iterations I g of th e MEC server to solve the global problem. In this scenario , to capture the statis tical an d sy stem -level heteroge n eity , the correspon ding p e rforma n ce bo und in (9 ) for heteroge n eous responses θ k can be mo dified consider ing the worst-case respo nse o f th e par ticipating clien t as I g ( ǫ, θ k ) = ζ · log( 1 ǫ ) 1 − max k θ k , ∀ k ∈ K . (11) 6 Fig. 2 describ es an in teraction e n vironmen t inc orpor a ting crowdsourcing fr amework an d FL setting. In the following section, we will f u rther discuss in details about the prop osed incentive mechanism, and p resent the interactio n between MEC server an d participatin g clien ts as a two-stage Stack- elberg game. B. Cost Mod e l T raining on local data for a define d accur acy level incurs a cost for the par ticipating clients. W e discuss its significan ce with two typical co sts: the com puting cost an d the commu ni- cation cost. Computing cost: This co st is related to the nu mber of iterations perform e d b y client k on its local data to tr ain the local m odel for attaining a relative accur acy of θ k in a single round o f co mmunica tio n. With (10 ), we define the comp u ting cost fo r clien t k when it p erform s com putation on its local data D k . Communication co st: Th is cost is incu rred wh en client k interacts with MEC ser ver for p arameter upd ates to maintain θ k accuracy . During a rou nd of co mmunicatio n with the MEC server, let e k be th e size (in bits) o f local param eters ∆ φ [ k ] , k ∈ K in a floa tin g p oint repr esentation p roduc e d by the participating client k af ter pro cessing a min i-batch [21]. While e k is the same for all the participating clients under a specified learning setting of th e global prob lem, e ach p articipating clien t k ca n invest resour ces to attain specific θ k as define d in (10). Although the best cho ice would be to choose θ k such th at the local solution time is co m parable with the time expe n se in a sing le commu nication r ound, larger θ k will indu ce more round s of interaction between clients until global con vergence, as formalized in (9). W ith the in verse relation of g lobal iteration upon local relativ e accuracy in (9 ), we can characterize the total com - munication expenditur e as T ( θ k ) = T k (1 − θ k ) , (12) where T k as the time required f or the client k to com muni- cate with MEC server in each ro und of mode l’ s pa r ameter exchanges. Here , we n ormalize ζ > 0 in (9) to 1 as the constant ca n be absorbed in to T k for eac h rou nd of mod el’ s parameter exchang es whe n we characterize the co mmunic a tion expenditure in (12 ). Using first-order T ay lor’ s appr o ximation 4 , we can ap proxim ate the to tal commu nication cost as T ( θ k ) = T k · (1 + θ k ) . W e assume that clients are allocated or th ogon al sub-chan nels so that th ere is no in terferen c e between them 5 . Therefo re, the instantaneous d ata rate for client k can be expressed as R k = B log 2 1 + p k | G k | 2 N k , ∀ k ∈ K , (13) 4 First-order taylor’ s approximatio n for f ( θ ) = 1 1 − θ is f ( θ ) | θ = a = f ( a )+ f ′ ( a )( θ − a ) . For small θ , the approximati on results f ( θ ) | θ =0 = 1 + θ . 5 Note that the scenari o of possible delay introduced with interferenc e on poor wireless uplink channel can affect the local model update time. This can be mitigated by adjusting maximum waiting time as in [17] at MEC. where B is the total band width allocated to the client k , p k is the tr ansmission power of the client k , | G k | 2 is th e chann el gain between pa r ticipating client k and th e base station, and N k is the Ga ussian noise power at client k . Then fo r clien t k , using (13), we can c h aracterize T k for eac h round of commun ication with the MEC ser ver to upload the req uired updates as T k = e k B log 2 1 + p k | G k | 2 N k , ∀ k ∈ K . (14) (14) provides the dependen cy of T k on wir eless conditions and network con nectivity . Assimilating the ration ale behind ou r ear lier discussions, for a participatin g client with evaluated T k , the increa se in value of θ k (poor local accuracy) will contr ibute for a larger commun ication expenditur e. T his is becau se the p articipating client h as to in te r act mo re frequen tly with the MEC server (increased number of global iterations) to up date its local model parame ter for attaining rela tive θ k accuracy . Further, the autho rs in [43] have p r ovided the convergence analysis to justify th is relation ship and the co mmun ication cost mode l, though with a different techniq ue. Therefo re, the par ticipating client k ’ s co st for the re lative accuracy level θ k on the lo cal subpro blem is C k ( θ k ) = (1 + θ k ) · ν k · T k + (1 − ν k ) · γ k log 1 θ k , (15) where 0 ≤ ν k ≤ 1 is the normalized monetary weigh t for commun ication an d computin g costs (i.e. , $/ ro u nds of iter- ation). A smaller value of relative accuracy θ k indicates a high lo cal a ccuracy . Thus, there exists a trade-off between the commun ication and th e comp uting co st (1 5 ). A participatin g client can ad just its pref erence on each of these costs with the weight metric ν k . Th e high er value o f ν k emphasizes on the la rger ro unds of interactio n with the MEC server to adjust its lo c al model para meters f or the relativ e θ k accuracy . On the o ther hand , the high er value o f (1 − ν k ) reflects the increased number of iterations a t the local subprob lem to achieve the relative θ k accuracy . This will also sig n ificantly reduce the overall co ntribution of commun ication exp e nditure in the total cost f ormulatio n for the clien t. No te that the client cost over iterations co u ld not be th e same. Howev er , to m a ke the problem more tractable, according to (9) we consider minimizing the up per-bound of the cost in stead o f the actual cost, similar to appro a ch in [16]. I V . I N C E N T I V E M E C H A N I S M F O R C L I E N T ’ S P A RT I C I PA T I O N I N T H E D E C E N T R A L I Z E D L E A R N I N G F R A M E W O R K In this section, firstly , we present our motivation to realize the conce pt of FL by employing a crowdsourcing f ramework. W e next advocate an incentive m echanism requ ired to realize this setting o f d ecentralized lear n ing m odel with ou r propo sed solution ap proach . 7 A. In centive Mechanism: A T wo-Stage Stackelber g Game Ap- pr oach The MEC server will allocate r ew a rd to the participatin g clients to achieve optimal local accu r acy in consideration for improvin g com munication efficiency of the system. That means, the MEC server will plan to in centivize clien ts f or maximizing its own ben efit, i.e. , an im p roved glob al mo del. Consequently , upon rec e iving the ann o unced rew ard, any ra- tional client will individually max imize the ir own pro fit. Su ch interaction scen ario can be realized with a Stackelberg g ame approa c h . Specifically , we fo rmulate our pro blem as a two-stage Stackelberg game between the MEC server (leader) and par- ticipating clients (fo llowers). Under the cr owdsourcing fram e- work, the MEC server d esigns an incentive mech anism f or participating clients to attain a local co n sensus accuracy lev el 6 on the lo c al mod els while improvin g the p e rforma n ce o f a centralized m odel. Th e MEC server can not directly co ntrol the participating clien ts to maintain a local consensus accur acy lev el, and r equires an effecti ve in c entive plan to en roll clients for this setting. Clients (Stage II): The M E C server h as an advantage, being a leader with the first-move advantage influen cing th e followers for participation with a local co n sensus accura cy . It will at first ann ounce a u niform reward rate 7 (e.g., a fair data package discoun t as $/accur acy lev el) r > 0 fo r the partici- pating clients. Given r , a t Stage II, a ratio nal client k will try to improve the lo cal mo del’ s a ccuracy for max imizing its ne t utility by tra in ing over the local data with global param eters. The pr oposed u tility framework incorpo rates the cost inv olved while a c lient tries to max im ize its own ind ividual utility . Client Utility Model: W e u se a valuation fu nction v k ( θ k ) to denote the mod el’ s effectiveness that explains the valuation of the client k wh en relative θ k accuracy is attained f or the local subprob lem. Assumption 1. The v aluation f u nction v k ( θ k ) is a linear, decreasing functio n with θ k > 0 , i.e., v k ( θ k ) = (1 − θ k ) . Intu- iti vely , for a smaller relative accur acy at the local subp roblem , there will be an increase in the rew ard for the par ticipating clients. Giv en r > 0 , each par ticipating client k ’ s strategy is to maximize its own utility as follows: max 0 ≤ θ k ≤ 1 u k ( r , θ k ) = r (1 − θ k ) − C k ( θ k ) , (16) giv en co st C k ( θ k ) as (1 5). The feasible solution is always restricted to the value less than 1 (i.e., witho ut loss of generality , for θ k > 1 , it violates the particip ation assump tion 6 It signifies the agreement among the particip ating clie nts on the quality of s olution at the local subproblems for building a high-qualit y centra lized learni ng model. 7 Prominentl y , two kinds of pricing scheme exist at present follo wing dif ferent design goals: uniform pricing and discriminatory or dif ferent iated pricing [44]. The differe ntiate d pricing scheme is more efficie nt, but also require s more information and higher complexi ty than the uniform pricing [45], [46]. Therefore, based upon offere d moti v ation s and benefits, our proposed cro wdsourcing framew ork follo ws a platform-c entric model to train a high quality global m odel with lo w complexity , less information exchange by using the uniform pricing scheme. 0 1 2 3 4 5 6 7 x ( ε ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 U( x ( ε ) ) l o g ( 1 / ε ) a = 0 . 3 , b = 0 a = 0 . 3 5 , b = − 1 a = 0 . 4 5 , b = − 1 . 0 5 a = 0 . 5 5 , b = − 1 . 1 a = 0 . 6 5 , b = − 1 . 1 5 Fig. 3: MEC u tility U ( · ) as a fu n ction of ǫ with d ifferent parameter values of a, b . for the crowdsourcing fram ework). Theref o re, pr oblem ( 1 6) can b e represen ted as max θ k > 0 u k ( r , θ k ) = r (1 − θ k ) − C k ( θ k ) , ∀ k ∈ K . (17) Also, we have C ′′ k ( θ k ) > 0 , which means C k ( θ k ) is a strictly conv ex fu nction. Thus, there exists a un ique solu tion θ ∗ k ( r ) , ∀ k . MEC Serv er(Stage I): Knowing th e respon se ( strategy) of the participa tin g clients, the MEC can e valuate an optimal rew ard rate r ∗ to max im ize its utility . T h e utility U ( · ) of MEC server can be defined in relatio n to th e satisfaction measure achieved with local co n sensus accur a cy level. MEC Server Utility Model: W e defin e x ( ǫ ) as the number of iterations req uired f or an arbitrary alg o rithm to conver ge to some ǫ ac curacy . W e similarly define I g ( ǫ, θ ) as global iterations of the framework to reach a relative θ accu racy on the lo cal subpro blems. From this perspective, we re quire an appro priate utility function U ( · ) as the satisfaction measure of the fra m ew ork with respect to the num b er of iter ations fo r achieving ǫ accuracy . In this regard , use th e definition of the num ber o f iterations for ǫ a ccuracy as x ( ǫ ) = ζ · log 1 ǫ . Due to large values of iterations, we ap proxim ate x ( ǫ ) as a continuo us value, and with the af orementio ned re lation, we choose U ( · ) as a strictly con cave function o f x ( ǫ ) for ǫ ∈ [0 , 1] , i.e., with the increase in x ( ǫ ) , U ( · ) also incr eases. Thus, we propo se U ( x ( ǫ )) as the norm a lized utility f unction bo unded within [0 , 1] as U ( x ( ǫ )) = 1 − 10 − ( ax ( ǫ )+ b ) , a ≥ 0 , b ≤ 0 , (18) which is strictly incre a sing with x ( ǫ ) , and represents the satisfaction of MEC incr e ase with r e sp ect to a ccuracy ǫ . As for the global model, there exists an accep table value of thresho ld a c curacy m easure cor respond ingly reflected b y x min ( ǫ ) . Th is suggests th e p ossibility of ne a r-zero utility fo r MEC server for failing to attain such value. Fig. 3 depicts o ur pr oposed utility function, a concave function of x ( ǫ ) with parameters a an d b that reflect the required behavior of the u tility fu nction d efined in (18 ). In 8 Fig. 3 , we can obser ve that larger value of a m eans sm a ller iterations requirem ent and larger values of b introd u ces flat curves suggestin g more flexibility in accuracy . So we can analyze the imp a c t of parameter s a and b in ( 1 8), and set them to m odel the utility function f or the MEC server as per the design req uirements of th e learnin g f r amework. Fu rthermo r e, in ou r setting, I g ( ǫ, θ ) c a n be elaborated with a upper bound (maximu m g lobal iterations, δ ) as I g ( ǫ, θ ) = x ( ǫ ) 1 − θ ≤ δ. (19) (19) explain s the efficiency pa r adigm of th e prop osed frame- work in ter ms of time r equired for the co nvergence to some accuracy ǫ . If τ l ( θ ) is the time per iteratio n to reach a relativ e θ accuracy at a local sub problem and T ( θ ) is the commun ication time requir ed during a single iteration for any arbitrary algorithm, then we can analyze the result in (19 ) with the efficiency o f the glob al m o del as I g ( ǫ, θ ) · ( T ( θ ) + τ l ( θ )) . (20) Because the cost of comm unication is proportion al to the spe e d and energy consump tion in a distributed scenario [20], the bound define d in ( 19 ) explains the efficiency in terms of MEC server’ s resource restriction f or attainin g ǫ accu racy . In this regard, the corresp onding an alysis of (20 ) is pr esented in the upcomin g su b-section with se veral case stud ie s. The utility o f the MEC server can therefor e be defin e d fo r the set of measured best respon ses θ ∗ as U ( x ( ǫ ) , r | θ ∗ ) = β 1 − 10 − ( ax ( ǫ )+ b ) − r X k ∈K (1 − θ ∗ k ( r )) , where β > 0 is the system para meter 8 , and r P k ∈K (1 − θ ∗ k ( r )) is the cost spent fo r incentivizing participating clien ts in th e crowdsourcing fr amework for FL. So, for the measu red θ ∗ from the par ticipating clien ts a t MEC server, th e utility maximization prob lem ca n be formu lated as follows: max r ≥ 0 ,x ( ǫ ) U ( x ( ǫ ) , r | θ ∗ ) , (21) s.t. x ( ǫ ) 1 − max k θ ∗ k ( r ) ≤ δ. (22) In con straint (22 ), ma x k θ ∗ k ( r ) char acterizes the worst case response for the ser ver side utility max imization prob le m w ith the b o und on p ermissible glob al iterations. No te that M E C adapts admission contro l strategy (discussed in Section VII) to improve the numbe r of participatio n for m aximizing its u tility . In fact, MEC has to increase th e reward rate to m a intain a minimum nu mber o f particip a tion (at least two) to rea lize the distributed optim ization setting in FL. I n addition to this, the framework may suffer fro m slower co nvergence du e to fewer participation . Thu s, MEC will av oid delibe r ately dropp ing th e clients to achieve a faster consensu s with (2 2). Furthermo re, using the r elationship defined in (19 ) b etween x ( ǫ ) and r elativ e θ accur acy for the subproble m , we can 8 Note that β > 0 characteriz es a linear scaling m etric to the utility function which can be set arbitrari ly and will not alter our ev aluation. Equi v alent ly , it can be understood as the ME C server ’ s physical resource consignment s for the FL that reflects the satisfa ction measure of the frame work. analyze the impact of resp o nses θ o n MEC server’ s utility in a FL setting with the constrain t (11). T o be mo re specific abou t this relation, we can o bserve th at with the incr eased value of (1 − θ ) , i.e., lower relative accuracy (high local accuracy), the ME C server can attain better utility d ue to correspo n ding increment in value o f x ( ǫ ) . Note that in the client co st pro blem, x ( ǫ ) is treated as a co nstant pr ovided by the ME C pro blem, and can be ig nored for solving (16 ). Lemma 1. The optimal solutio n x ∗ ( ǫ ) for (2 1) can be de rived as δ (1 − max k θ ∗ k ( r )) . Pr oof: See App endix A. Therefo re, for the giv en θ ∗ ( r ) , we can formalize (21) as max r ≥ 0 β 1 − 10 − ( ax ∗ ( ǫ )+ b ) − r X k ∈K (1 − θ ∗ k ( r )) . (23) Stackelberg Equilibrium. With a solution to MEC server’ s utility maximiz a tio n pro blem, r ∗ we have th e following d efi- nition. Definition 1. For any values of r , and θ , ( r ∗ , θ ∗ ) is a Stackelberg e quilibrium if it satisfies th e following conditions: U ( r ∗ , θ ∗ ) ≥ U ( r , θ ∗ ) , (24) u k ( θ ∗ k , r ∗ ) ≥ u k ( θ k , r ∗ ) , ∀ k . (25) Next, we employ the b ackward-ind u ction me thod to analyze the Stackelbe rg equ ilibria: the Stage-II problem is solved at first to obtain θ ∗ , which is then used for solving the Stage-I problem to o btain r ∗ . B. Sta ck elber g Equilibrium: Algorithm and Solutio n Appr oach Intuitively , from (1 9), we see that the server can ev aluate the maximu m value of x ( ǫ ) req uired f o r attaining accuracy ǫ for the centralized mo del while maintain ing relative accu racy θ th amongst th e participatin g clients. Here, θ th is a consen sus on a maximum lo cal accuracy level amo ngst participating clients, i.e ., the local sub p roblem s will maintain at least θ th relativ e ac c uracy . So, with the m easured responses θ from the participating clients, the server can design a pro per incentive plan to impr ove the global mode l while maintaining the worst case relative accuracy ma x k θ ∗ k as θ th for the local mode l. Since the thresh o ld accuracy θ th can be adju sted b y the MEC server for each round of solution, each pa r ticipating client will maintain a re sp onse towards the m aximum local consen su s accuracy θ th . This f ormalizes the client’ s selection criter ia [see Remark 1. ] whic h is sufficient enou gh fo r the MEC server to maintain the accuracy ǫ . W e also h ave the lower bound related with the value o f x min ( ǫ ) for eq u iv alen t accuracy ǫ max while dealing with the clien t’ s responses θ , i.e., log 1 ǫ max ≤ x ( ǫ ) (1 − θ th ) ≤ δ max . (26) where δ max is the maximu m perm issible upper bound to the global itera tions. As explained b efore an d with (26 ) , the value of θ th can be varied (lowered) by ME C server to improve the overall perfor mance of the system. For a worst case scenario , where the offered r ew ard r for the client k is insufficient to motiv ate 9 it for participation with impr oved local relative accur acy , we might have ma x k θ ∗ k ( r ) = 1 , i.e., θ th = 1 , no particip ation. Lemma 2. F or a given r ewar d rate r , a nd T k which is determined ba sed upo n th e chann el cond itio ns (14) , we have the unique solution θ ∗ k ( r ) fo r the participating client satisfying following r ela tion: g k ( r ) = lo g ( e 1 /θ ∗ k ( r ) θ ∗ k ( r )) , ∀ k ∈ K , (27) for g k ( r ) ≥ 1 , wher e, g k ( r ) = r + ν k T k (1 − ν k ) γ k − 1 . Pr oof: Because C ′′ k ( θ k ) > 0 f or θ k > 0 , (1 7) is a strictly conv ex functio n re su lted as a linear p lus conve x structure. Therefo re, by the first-or der co ndition, (1 7) can be ded uced as ∂ u k ( r , θ k ) ∂ θ k = 0 ⇔ 1 θ k − lo g 1 θ k = r + ν k T k (1 − ν k ) γ k − 1 , ⇔ log ( e 1 /θ k θ k ) = g k ( r ) . (28) W e o bserve that Lem ma 2 is a dir ect consequen ce of the solution structu re d e riv ed in (28). Hence, we conclu de the proof . From Lemma 2, we have some observations with the defini- tion of g k ( r ) f o r the r esponse of the p articipating clients. Fir st, we can show that θ ∗ k is larger f or the poor c h annel co n dition on a given reward r ate. Second, in such scenario, with the increase in reward r ate, say for g k ( r ) > 2 the particip ating clients will iterate more durin g their compu tation phase resultin g in lower θ ∗ k . Th is will reduce the n umber of global iteratio n s to attain an ac curacy level f or the glob a l problem . W e can therefor e character ize the particip ating client k ’ s best response under the prop osed framework as θ ∗ k ( r ) = min n ˆ θ k ( r ) | g k ( r )=log( e 1 / ˆ θ k ( r ) ˆ θ k ( r )) , θ th o , ∀ k . (29) (29) r epresents the be st respon se strategy for the par ticipating client k under ou r p roposed fr a m ew ork. Intuitively , exploring the lo garithmic structure in (27), we observe that the in crease in in c e ntiv e r will motivate p articipating clients to increase their efforts fo r local iteratio n in one g lobal iteration. This is reflected b y a b e tter respon se, i.e., a lower relative accu racy (high local accu racy) du ring eac h round of c ommun ication with the MEC server . Fig. 4 illustrates such strategic r esponses o f the participa ting clients over an offered rew ard f o r a given configuratio n . In th is scenario, to elab orate th e best respo nse strategy as characterized in (29), we h av e consider ed fou r particip ating clients with different pref erences (e.g., Client 3 being the most reluctant p a r ticipant). W e o bserve tha t Client 3 seek s more incentive r to maintain compar able accuracy level as Client 1. Further, we consider the trade off b etween commun ication cost an d the compu tation cost as discu ssed with the relation in ( 1 5). These costs are c o mplemen tary in relation by ν k , an d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 I n c e n ti v e ( r ) 0 .0 0 .2 0 .4 0 .6 0 .8 1 .0 R e l a t i v e a c c u r a c y ( θ ) θ th C l i e n t 1 C l i e n t 2 C l i e n t 3 C l i e n t 4 Fig. 4: An illustration showing participating clients resp o nse over th e offered r ew ard r ate. for each client k th eir preferen ces upo n these co sts are also different. For instance , the higher value of ν k for client k emphasizes on the incr eased numb er of c o mmun ication with the ME C ser ver to im p rove the local relative accura cy θ k . In Fig. 5, we briefly present the solutio n analy sis to (27) with the impact o f ch annel cond ition (we define it as com- munication adversity) on th e local relati ve accur a cy for a constant reward. For th is, in Fig. 5a we consider a p articipating client with the fixed o ffered reward setting r from uniform ly distributed values of 0.1 to 5. W e use normalized T k parameter for a client k to illustrate the respo nse analy sis scen ario. In Fig. 5 b and Fig. 5c, T k is unifor m ly distributed on [0. 1 , 1], and ν k is set at 0 .6. Intuitively , as in Fig. 5a, the increase in comm u nication time T k for a fixed reward r will influence participating clients to iter ate more locally fo r improving local accuracy than to rely upon the glo bal model, wh ich will minimize their total cost. Und er th is scen ario, we observe the increase in commun ication co st with the incr ease in co mmu- nication time T k . Thus, the clients will iter a te more locally . Howe ver, the trend is significan tly affected by normalized weights ν k , as observed in Fig. 5 b and Fig . 5c. For a larger value of T k (poor ch annel cond ition) as in the ca se of Fig. 5c, increasing the value of ν k , i.e . , clients with more pr eference on the commu nication cost in the total cost mo del resu lts to higher local iterations for solving local su b prob le m s, as reflected by the better lo cal accu racy , unlike in Fig. 5b. In both cases we ob serve the decr e a se in commu nication c o st upon particip ation. Howe ver , in Fig. 5 c the comm unication cost is higher because of an expensive d a ta rate. Therefo re, for a g i ven r , client k can adju st its weight m etrics accor d ingly to imp rove the r esponse θ k . In Fig. 6 , we explore such beh aviors of the participating clients throu gh the heatmap plot. T o expla in b etter , we define three categories of participating clients based upon the value of normalized weig hts ν k , ∀ k , which ar e their individual p refer- ences upo n the co mputation cost and th e commu nication cost for the co n vergence o f th e learnin g framework. (i) Relu ctant clients with a lower ν k consume more reward to improve local accuracy , ev en thou gh the value o f T k is larger (expensive), as observed in Fig. 6a. (ii) Sensitive clients are mo re su sceptible tow ards the chan nel q uality with larger ν k , and iterates more 10 (a) 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 No r m a l i z e d e i g h t ( ν k ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 0 . 0 2 5 0 . 0 5 0 0 . 0 7 5 0 . 1 0 0 0 . 1 2 5 0 . 1 5 0 0 . 1 7 5 0 . 2 0 0 R e l a ti v e a c c u r a c y C o m m u n i c a ti o n c o st (b) 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 No r m a l i z e d w e i g h t ( ν k ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 R e l a ti v e a c c u r a c y C o m m u n i c a t i o n c o st (c) Fig. 5: Solution An alysis (27) (Left Y -axis: Relati ve accu racy , Right Y -axis: Com munication cost): (a) impac t of commun ication adversity o n local relative accu racy for a constan t rew a r d ( b ) n ormalized weight versus relativ e accur acy for a fair data rate (quality c o mmun ic a tio n c hannel) (c) normalized weight versus r elativ e accuracy fo r an expen si ve d ata ra te . (a) (b) (c) Fig. 6: Case Study: impact o f co m municatio n co st an d offered reward rate r for different values of normalized weight (prefer ences), ν k defining client’ s categor ies (a) Relu c tant, ν k = 0 . 1 (b ) Rational, ν k = 0 . 5 (c) Sensitiv e, ν k = 0 . 7 . X- axis shows the incre ase in in centive (r) value f rom lef t- to-righ t, an d th e y-ax is defines the in crease in value of commu nication expenditure (to p -to-bo ttom). locally within a rou nd of communication to the MEC server for improving lo cal accuracy , as observed in Fig. 6 c. (iii) Rationa l clients, as referred in Fig. 6b ten d to b alance these extreme preferen ces (say ν k = 0 . 5 for client k ), which in fact would be u nrealistic to expect all th e time du e to heterog eneity in participating client’ s resou r ces. T o solve (23) efficiently , with (29) θ ∗ k ( r ) = min n ˆ θ k ( r ) | g k ( r )=log( e 1 / ˆ θ k ( r ) ˆ θ k ( r )) , θ th o , ∀ k , we in troduce a new variable z k in r elation with con sensus on local relative accuracy θ th , z k = ( 1 , if r > ˆ r k ; 0 , otherwise , (30) where ˆ r k = h g − 1 k (log( e 1 /θ th θ th )) i is the minim u m incen tiv e value require d obtain ed fr o m (2 9 ) to attain th e local con sensus accuracy θ th at client k for the defined param eters ν k and T k . This m e ans, θ k ( r ) < θ th when z k = 1 , and θ th ≤ θ k ( r ) < 1 when z k = 0 . ME C ser ver can use this setting to d r op the participants with po o r acc uracy . As discussed be f ore, fo r the worst case scen ario we co nsider θ th = 1 . Therefo re, the u tility maximiz a tion pro blem can b e eq u iv a- lently written a s max r, { z k } k ∈K β 1 − 10 − ( ax ∗ ( ǫ )+ b ) − r X k ∈ K z k · (1 − θ ∗ k ( r )) , (31) s.t. r ≥ 0 , (32) z k ∈ { 0 , 1 } , ∀ k . (33) The problem ( 31) is a mixed-b oolean pr ogramm ing, which may requir e exponen tial-complexity effort ( i.e., 2 K configur a- tion of { z k } k ∈K ) to solve by the exhaustive search. T o solve this problem with linear complexity , we ref e r to the solu tio n approa c h as in Algorithm 2 . The utility maximiza tio n pro blem at MEC server can be reform u lated as a constrain t optimization prob lem (34-35) assuming a fixed config uration of { z k = 1 } k ∈K as max r ≥ 0 β 1 − 10 − ( ax ∗ ( ǫ )+ b ) , (34) s.t. r X k ∈ K (1 − θ ∗ k ( r )) ≤ B , (35) where (35) is budget constraint for the prob lem. The second-o rder d eriv ative o f function r (1 − θ ∗ k ( r )) in (35) is 11 Algorithm 2 MEC Ser ver’ s Utility Max imization 1: Sort c lien ts as with ˆ r 1 < ˆ r 2 < . . . < ˆ r K 2: R = {} , A = K , j = K 3: while j > 0 do 4: Obtain the solution s r j to th e following problem : max r ≥ ˆ r 1 β 1 − 10 − ( ax ∗ ( ǫ )+ b ) − r X k ∈A (1 − θ ∗ k ( r )) 5: if r j > ˆ r j , then R = R ∪ { r j } ; 6: end if 7: A = A\ j ; 8: j = j − 1; 9: end while 10: Return r j ∈ R with highest o ptimal values in pro blem (4). 2 γ k (1 − ν k ) ν k T k ( r + ν k T k ) 3 > 0 , i.e., the problem (34 ) is a conve x problem and can be solved similarly with Algo rithm 2 ( line 4 -5). Proposition 1. Algorithm 2 can solve the Stage-I equiv a lent pr oble m (23 ) with lin ear co mplexity . Pr oof: As th e clien ts are sorted in the ord e r of incr easing ˆ r k (line 1), for the suf ficient condition r > ˆ r k resulting z k = 1 , the MEC’ s utility ma x imization pr o blem redu ces to a single-variable p roblem that can be solved using pop ular numerical methods. Remark 1 . Algorithm 2 ca n maintain consensu s a ccuracy b y formalizing the clients selectio n criteria. This is becau se fr om (30), z k = 1 for θ k ( r ) < θ th , and z k = 0 fo r θ th ≤ θ k ( r ) < 1 . Thus, MEC server u ses this setting to dr o p the p articipants with θ k ( r ) > θ ∗ k ( r ) = θ th . Theorem 1. The Stack elber g equ ilibria of the cr owdsou r cin g framework a re the set o f pairs { r ∗ , θ ∗ } . Pr oof: For any given θ , it is obvious that U ( r ∗ , θ ) ≥ U ( r, θ ) , ∀ r since r ∗ is the solutio n to the Stage-I problem . Thus, we ha ve U ( r ∗ , θ ∗ ) ≥ U ( r , θ ∗ ) . In th e similar way , for any giv en value o f r and ∀ k , we have u k ( r , θ ∗ k ) ≥ u k ( r , θ k ) , ∀ θ k . Hence , u k ( r ∗ , θ ∗ k ) ≥ u k ( r ∗ , θ k ) . Co m bining these facts, we co nclude the p roof being based u pon the definitions of (24) and (25). V . S I M U L AT I O N R E S U LT S A N D A N A L Y S I S In this sectio n , we present numerica l simulation s to illustrate our resu lts. W e con sider th e learn ing setting f or a strongly conv ex mod el such a s logistic regression, a s discussed in Section I II, to ch aracterize and demo nstrate the efficacy of the pro posed framew ork. First, we will show the optimal solution of Algorithm 2 (ALG. 2) and co nduct a comp a r ison of its per forman ce with two baselines. The first one, name d OPT , is the op timal so lutions of pr oblem (23) with exhau sti ve search for the o ptimal respo nse θ ∗ . Th e secon d o ne is called Baseline that considers the worst respon se am ongst the pa r- ticipating clien ts to attain lo c a l con sensus θ th accuracy with an offered price. This is an inefficient scheme but still enab les us to a ttain fea sib le solutions. Finally , we analy ze th e system 0 .2 0 0 .2 5 0 . 3 0 0 . 3 5 0 . 4 0 0 . 4 5 0 .5 0 0 .5 5 0 . 6 0 θ th 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 4 . 5 R e w a r d a te ( ) Ba se l in e O PT ALG. 2 0 .2 0 0 .2 5 0 .3 0 0 .3 5 0 .4 0 0 .4 5 0 .5 0 0 .5 5 0 .6 0 θ th 8 . 2 5 8 . 5 0 8 . 7 5 9 . 0 0 9 . 2 5 M E C u ti l i ty Fig. 7 : Comp arison of (a) Re ward rate and (b) MEC utility under three schem es for different values of threshold θ th accuracy . perfor mance b y varying d ifferent par ameters, an d co nduct a compariso n o f th e inc e ntiv e mechan ism with the baseline and their co rrespon ding utilities. In o ur analysis, the smaller v alues of local consensus are of specific interest as they reflect th e effecti vene ss o f FL. 1) Settings: For an illustrative scenario, we fix the num - ber of participating c lients to 4. W e con sider the system parameter β = 10 , and the upp er b ound to th e numb e r o f global iterations δ = 10 , which character izes the per missible round s of co mmun ica tion to en su re g lo bal ǫ accu r acy . Th e MEC’ s utility U ( x ( ǫ )) = 1 − 10 − ( ax ( ǫ )+ b ) model is d efined with param eters a = 0 . 3 , and b = 0 . For each client k , we con sider norm alized w e ight ν k is u n iformly distributed on [0.1,0 .5], wh ich can pr ovide an insight o n th e system’ s efficac y as pr e sented in Fig. 6. W e char acterize the inter action between th e MEC ser ver and the participatin g clients unde r homog eneous chann el condition, and use the no rmalized value of T k for all participatin g clients. 2) Rewar d rate: In Fig. 7 we increase the value of local consensus accuracy θ th from 0.2 to 0.6 . When the accuracy lev el is improved ( from 0.4 to 0.2), we ob serve a significant increase in reward rate. These results are consistent with the analysis in Section IV -B. The reason is that c o st for attain ing higher loca l accura cy level requires mo re loca l iterations, and thus the participatin g clients exert more incentive to compen sate for their costs. W e also show that the r eward variation is pro minent f o r lower values of θ th , and observe that sch eme ALG. 2 and OPT achieve the same pe rforma n ce, while Baseline is not as efficient as o thers. Here, we can observe u p to 22% gain in the offered reward against the Baseline by other two schemes. In Fig. 7b, we see the corr espondin g MEC utilities for the offered r ew ard th at co m plements th e co mpetence of propo sed ALG. 2. W e see, th e trend of utility again st the o ffered r eward goes along with our analysis. 3) P arametric choice: In Fig. 8 we show the imp act of parametric choice adopted by the participating client k to solve the loc a l sub problem [19], which is char a c terized by γ k . In Fig. 8a, we see a lower o ffered reward for the impr oved local accu r acy level for the participating clients ad apting same parameters (algorith ms) for solv ing the local subpro blem, in contrast to Fig . 8b with th e unifo rmly distributed γ k on [1,5] 12 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 θ th 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 R e w a r d r a t e ( r ) 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 θ t h 7 . 0 7 . 5 8 . 0 8 . 5 9 . 0 9 . 5 1 0 . 0 M E C u t i l i t y (a) 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 θ th 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 4 . 5 5 . 0 5 . 5 R e w a r d r a t e ( r ) 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 θ t h 7 . 0 0 7 . 2 5 7 . 5 0 7 . 7 5 8 . 0 0 8 . 2 5 8 . 5 0 8 . 7 5 9 . 0 0 M E C u t i l i t y (b) Fig. 8 : (a) For |K| = 4 , a = 0 . 3 , b = 0 , γ k = 1 , ∀ k . (b ) For |K| = 4 , a = 0 . 3 , b = 0 , and γ k ∼ U [1 , 5] . to achieve the comp etitiv e utility . 4) Compa risons: I n T ab le a, and T able b, we see the effect of randomized parameter γ k for different con figuration of MEC utility mode l U ( · ) define d by ( a, b ) . For the smaller values of θ th , whic h captur e s th e comp etence of the propo sed mechanism, we observe th at the choice of ( a, b ) provides a consistent offered reward for imp roved utility fro m (0 . 35 , − 1 ) to (0 . 65 , − 1) , which follows our analysis in Section I V -A. For larger values of θ th , we also see th e similar tr end in ME C utility . For a rando mized setting , we observe up to 7 1 % gain in offered rew ard against th e Baseline, wh ic h validates our propo sal’ s efficac y aid ing FL. V I . T H R E S H O L D A C C U R AC Y E S T I M AT I O N : A N A D M I S S I O N C O N T R O L S T R AT E G Y Our earlier discussion in Sectio n IV and simu lation resu lts explain the significance of cho osing a local θ th accuracy to build a global model that maxim izes the utility of the MEC server . In this regard, at first, the M E C server ev okes admission control to deter mine θ th and th e final mo del is learned later . This means, with th e numbe r o f expec ted clien ts, it is crucial to approp riately select a pro per prior value of θ th that cor respond s to the particip ating clien t’ s selection criteria for tr a ining a specific learning model. Note that, in each comm u nication round o f syn chron ous aggregation at the MEC server , th e quality of local solution benefits to ev alu ate the performa nce at the local subproblem . In this section, we will discuss abou t th e probab ilistic m o del employed b y the MEC server to determine the value of the consen su s θ th accuracy . W e consider the local θ accur acy for the p articipating clients is an i.i.d an d u niformly distributed r andom variable over the range [ θ min , θ max ] , th e n the PDF of th e respon ses can be defined as f θ ( θ ) = 1 θ max − θ min . Let us c o nsider a seq u ence of discrete time slots t ∈ { 1 , 2 , . . . } , where the M EC server updates its configur ation for imp roving the accu racy of the system. Following our ear lier d e finitions, at time slot t , th e number of particip a ting clients in the crowdsourcin g f rame- work f o r FL is |K ( t ) | , or simply K . W e restrict the clients with the accu racy measure θ ( t ) ≥ θ max . For K numb er of participation re q uests, th e total number of acc e pted responses N ( t ) is d efined as N ( t ) = K · F θ ( t ) ( θ ) = K · P [ θ ( t ) ≤ θ ] . W e have N ( t ) = K · h θ ( t ) − θ min θ max − θ min i . At each time t , the MEC server chooses θ ( t ) as the thr e shold accuracy θ th that maximizes the sum o f its u tility as defined in (1 8) for the defined para m eters a ≥ 0 , b ≤ 0 and the to tal par ticipation, β 1 − 10 − ( ax ( ǫ )+ b ) + (1 − θ ) · N ( t ) , subject to the co nstraint that th e respo nse lies b etween the m inimum an d max im um accuracy m easure ( θ min ≤ θ ( t ) ≤ θ max ). Using the definitions in (19), for β > 0 , the ME C server maximizes its utility for the n umber of participation with θ accuracy as max θ ( t ) β 1 − 10 − ( a · δ (1 − θ ( t ))+ b ) + (1 − θ ( t )) · N ( t ) , s.t. θ min ≤ θ ( t ) ≤ θ max . (36) The Lagrang ian o f th e prob lem (36 ) is as follows: L ( θ ( t ) , λ, µ ) = β 1 − 10 − ( a · δ (1 − θ ( t ))+ b ) + (1 − θ ( t )) · θ ( t ) − θ min θ max − θ min + λ ( θ ( t ) − θ min ) + µ ( θ max − θ ( t )) , (37) where λ ≥ 0 a n d µ ≥ 0 are du a l variables. Problem (3 6) is a convex problem wh o se op timal p rimal and du al variables can b e cha racterized using the Karush-Kh un-Tucker (KKT) condition s [40] as ∂ L ∂ θ ( t ) = ln(10) · ( β δ a ) · 10 − ( a · δ (1 − θ ∗ ( t ))+ b ) − K · 2 θ ( t ) − θ min θ max − θ min + λ − µ = 0 , (38) λ ( θ ( t ) − θ min ) = 0 , (39 ) ν ( θ max − θ ( t )) = 0 . (40 ) Follo wing the comp lementary slackn ess cr iterion, we hav e λ ∗ ( θ ∗ ( t ) − θ min ) = 0 , µ ∗ ( θ max − θ ∗ ( t )) = 0 , λ ∗ ≥ 0 , µ ∗ ≥ 0 . (41) Therefo re, from ( 41), we solve (36) with the KKT conditio n s assuming that θ ∗ ( t ) < θ max as an admission control strategy , and find the op tim al θ ∗ ( t ) that satisfies the following relation 13 Thre shold accuracy Baseline ALG. 2 ALG. 2 ALG. 2 θ th r (0 . 3 , − 1) (0 . 35 , − 1) (0 . 65 , − 1) 0.2 18 5.22 5.22 5.22 0.3 12 3.48 3.48 3.48 0.4 8.99 2.602 2.6 2.61 0.5 7.19 2.79 4.3 2.2 0.6 5.99 2.38 2.87 2.1 0.7 5.13 2.84 3.17 1.9 (a) Offered re ward rate comparison with randomized γ effect for differe nt ( a, b ) setting. Thre shold accuracy ALG. 2 ALG. 2 ALG. 2 θ th (0 . 3 , − 1) (0 . 35 , − 1) (0 . 65 , − 1) 0.2 8.55 8.79 8.96 0.3 8.41 8.60 8.95 0.4 8.33 8.58 8.94 0.5 8.2 8.73 8.91 0.6 8.18 8.4 8.91 0.7 7.8 8.51 8.86 (b) Util ity comparison with randomized γ effec t for different ( a , b ) setting. 0 1 0 2 0 3 0 4 0 No . o f p a r t i c i p a t i n g c l i e n t s ( K ) 0 .1 5 0 .2 0 0 .2 5 0 .3 0 0 .3 5 0 .4 0 0 .4 5 0 .5 0 θ t h δ = 1 0 δ = 1 2 δ = 1 5 (a) 0 1 0 2 0 3 0 4 0 No . o f p a r t i c i p a t i n g c l i e n t s ( K ) 0 . 1 5 0 . 2 0 0 . 2 5 0 . 3 0 0 . 3 5 0 . 4 0 0 . 4 5 0 . 5 0 θ t h δ = 1 0 δ = 1 2 δ = 1 5 (b) Fig. 9: V ariation o f loca l θ th accuracy for different values of δ given the den sity function , f θ ( θ ) ∼ U [0 . 1 , 0 . 9 ] , |K| = [0 , 5 0] , (a) For a = 0. 3 5, b = -1. ( b) For a = 0.45 , b = -1 .05. K = ln(10) · ( β δ a ) · 10 − ( a · δ (1 − θ ∗ ( t ))+ b ) · ( θ min − θ max ) 1 − 2 θ ∗ ( t ) + θ min . (42) (42) c a n be r earrang ed a s f ( θ ∗ ( t )) = ln(10) · ( β δ a ) · 10 − ( a · δ (1 − θ ∗ ( t ))+ b ) + K · 1 − 2 θ ∗ ( t ) + θ min θ max − θ min = 0 . (43) T o obtain th e value of θ ∗ ( t ) we will use Netwon-R a phson method [4 7] employing an app ropria te initial g uess that man- ifests the q uadratic convergence of the solution . W e choose θ ∗ 0 ( t ) = E ( θ ( t )) = θ max + θ min 2 as an initial guess for finding θ ∗ ( t ) wh ich f ollows the PDF f θ ( θ ) ∼ U [ θ min , θ max ] . Then the solution method is an iterative ap proach as follows: θ ∗ i +1 ( t ) = θ ∗ i ( t ) − f ( θ ∗ i ( t )) β δ 2 a 2 · ln 2 (10) · 1 0 − ( a · δ (1 − θ ∗ i ( t ))+ b ) . (44) Numerical Analysis: In Fig. 9, we vary the numb er of participating clients u p to 5 0 with different values o f δ . The response o f the clien ts is set to fo llow a u niform distribution on [0.1, 0.9 ] for the ease of repre sentation. In Fig . 9a , for the model param eters (a,b) as (0.3 5,-1), we see θ th increases with the incr ease in th e number of p articipating clients for all v alues of δ . It is intuitive, and g o es along with our earlier analysis that for the small n umber of p articipating clients, the smaller θ th captures the efficacy of o ur prop osed framework. Because it is an iter ativ e p rocess, the evolution of θ th over th e rounds of co mmun ic a tion will b e reflected in the framework design. Subsequen tly , th e larger upp er bou nd δ exhibits the similar impact on setting θ th , where smaller δ imposes strict local accuracy level to attain high- quality centralized model. Also due to the same reason, in Fig. 9b, we see θ th is increasing fo r the increa se in the num ber o f p articipating clients, however , with th e lower value. It is beca use of the choice o f parameter s (a,b) as explain ed in Section IV -A. So the value of θ th is lower in Fig. 9b . V I I . C O N C L U S I O N In th is paper, we hav e designed a n d analyz e d a novel crowd- sourcing framework to enab le FL. An incen tiv e mechan ism has b een established to enable the participation of several devices in FL. In p articular, we have ad opted a tw o-stage Stackelberg game model to jointly stud y th e utility maxi- mization of the p articipating clients and MEC server in ter- acting via an application platfo rm for building a h igh-qu ality learning mo d el. W e have in corpo rated the challen ge of main- taining commu nication e fficiency f or exchang ing the mod el parameters amo ng participating clients during aggregation . Further, we have derived the best response solution and proved the existence o f Stackelbe rg equilibr ium. W e have examin ed characteristics of par ticip ating clients f o r d ifferent parametr ic configur ations. Additionally , we have c onduc ted nu m erical simulations and presented sev eral case studies to ev alu a te the framework efficacy . Thro ugh a p robabilistic mod el, we have designed and presented numerical results on an admission control strategy for the number of clien t’ s par ticipation to attain the correspon ding local consensus accu racy . For fu ture work, we will focus o n mob ile crowdsourcing framework to enable the self-organizing FL that consider s task offloading 14 strategies for the resou rce constraint devices. W e will conside r the scenario wh ere the cen tr al coordin ating MEC server is replaced by on e of the particip a tin g clients an d d evices can offload their training task to the edge computing infr astructure. Another d irection is to study the impact of d iscriminatory pr ic- ing scheme fo r participatio n. Such works can na r rate tow ards numero us incentive mechanism d esign, such as o ffered tokens in block chain n etwork [17]. W e also plan to furth er in vesti- gate on participating c lien t’ s behavior , in term s of ince n tiv e and commu nication efficiency , to incorp orate co operative data trading scen ario for the prop o sed fram ew o rk [48], [49]. A P P E N D I X A K K T S O L U T I O N The utility m a x imization prob le m in ( 21) is a conve x optimization p r oblem whose optimal solu tion can be ob tained by using Lagran g ian duality . T he lag rangian of (21) is L ( r , x ( ǫ ) , λ ) = β 1 − 10 − ( ax ( ǫ )+ b ) − r X k ∈ K (1 − θ ∗ k ( r )) + λ [ δ (1 − max k θ ∗ k ( r ) − x ( ǫ )] (A.1) where λ ≥ 0 is the Lagrangia n m ultiplier fo r co nstraint (22). By takin g the first-orde r d eriv ative of ( A.1) with respect to x ( ǫ ) and λ , KKT con ditions are expressed a s f ollows: ∂ L ∂ x ( ǫ ) = aβ e − ( a ( x ( ǫ ))+ b ) − λ ≤ 0 , if x ( ǫ ) ≥ 0 . (A.2 ) ∂ L ∂ λ = [ δ (1 − max k θ ∗ k ( r )) − x ( ǫ )] ≥ 0 , if λ ≥ 0 . ( A.3) By solving (A. 2), the solution to the u tility maximization problem (21) is x ∗ ( ǫ ) = − ln( λ/aβ ) − b a . (A.4) From (A.3), the Lagran gian multiplier λ is as λ ∗ = aβ e [ aδ ( 1 − max k θ ∗ k ( r ))+ b ] . (A.5) Thus, fr om (A.4 ) an d (A.5 ) the optimal solu tion to th e utility maximization prob lem ( 21) is x ∗ ( ǫ ) = δ (1 − max k θ ∗ k ( r )) . (A.6) R E F E R E N C E S [1] S. R. Pandey , N. H. Tran, M. Bennis, Y . K. Tun, Z. Han, and C. S. Hong, “Incenti vize to build: A crowdsourci ng framew ork for federated learni ng, ” in Proc. of the IEEE Global Communications Confere nce (GLOBECOM) , W aikoloa , HI, USA, Dec. 2019. [2] [Online]. A v ailab le: https://www . idc.com/ge tdoc.jsp?containerId= prUS43773018 [3] R. K. Ganti, F . Y e, and H. Lei, “Mobile crowdsen sing: curren t state and future challenges, ” IEEE Communications Maga zine , vol. 49, no. 11, pp. 32–39, Nov 2011. [4] X. Zhang, Z. Y ang, C. Wu, W . Sun, and Y . Liu, “Robust traject ory estimati on for cro wdsourcing-b ased mobile application s, ” IE EE T rans- actions on P arallel & Distrib uted Systems , vol. 25, no. 7, pp. 1876–188 5, July 2014. [5] C. W u, Z. Y ang, and Y . L iu, “Smartphones based crowdsou rcing for indoor locali zatio n, ” IEEE T ransactions on Mobile Computing , vol. 14, no. 2, pp. 444–457, Feb 2015. [6] E. Kouko umidis, L .-S. Peh, and M. R. Martonosi, “Signalguru: lev er- aging mobile phones for collabora ti ve traffic signal schedule advisory , ” in P roc. of the 9th international confer ence on Mobile systems, appli- cations, and services . A CM, Beth esda, Marylan d, USA, J une 28–July 01, 2011, pp. 127–140. [7] “W e are making on-de vice AI ubiquitous, ” T ech. Rep. [Online]. A vai lable : https://www .qualc omm.com/ne ws/onq/20 17/08/16/ we- are- m aking- de vice- ai- ubiquitous [8] “80 percen t of s martphone s will hav e on-de vice ai capabili ties by 2022: Gartner . ” [Online]. A vai lable : http://www .bgr .in/ne ws / 80- percent- of- sm artphone s- will- have- on- device- ai- capabilities- by- 2022- gartner/ [9] W . House, “Consumer data pri vac y in a networke d world: A frame work for protecting priv acy and promoting innov ation in the global digital economy , ” White House, W ashington, DC , pp. 1–62, Feb 2012. [10] “Federated learning: Collaborati ve machine learning w ithout centr alize d traini ng data, ” T ech. Rep. [Onlin e]. A vail able: http:// ai.google blog.com/ 2017/04/ federat edlearning- collaborative .html. [11] J. Kon e ˇ cn ` y, H. B. McMahan, F . X. Y u, P . Richt ´ arik, A. T . S uresh, and D. Bacon, “Federa ted learn ing: Strategie s for improvi ng communication ef ficienc y , ” arXiv preprint , Oct 2016. [12] J. Kon ecn ` y, H. B. McMahan, D. Ramage, and P . Richt ´ arik, “Federat ed optimiza tion: Distribute d m achine learning for on-devi ce intel ligenc e, ” arXiv preprin t arXiv:1610.02527 , O ct 2016. [13] B. McMahan and D. Ramage, “Federated learning : Collaborati ve ma- chine learning without centra lize d training data, ” Google Resear ch Blog , April 2017. [14] R. Kel ly , “Interne t of things data to top 1.6 zettab ytes by 2022, ” Campus T echnolo gy , Accessed on Dec 2019 , vol. 9, pp. 1536–1233, 2016. [15] H. B. McMahan, E. Moore, D. Ramage, S. Hampson et al. , “Communica tion-ef ficient learning of deep network s from decentra lized data, ” arXiv pre print arXiv:1602.05629 , Feb 2016. [16] S. W ang, T . T uor , T . Salonidi s, K. K. L eung, C. Makaya, T . He, and K. Cha n, “When edge mee ts learnin g: Adaptiv e control for resource-c onstrai ned distrib uted machine learning , ” arXiv preprin t arXiv:1804.05271 , Aug 2018. [17] H. Kim, J. Par k, M. Bennis, and S.-L. Kim, “On-dev ice feder - ated learning via blockchain and its latency analy sis, ” arXiv pre print arXiv:1808.03949 , Aug 2018. [18] C. Ma, J. Kone ˇ cn ` y, M. Jaggi, V . Sm ith, M. I. Jordan, P . Richt ´ arik, and M. T ak ´ a ˇ c, “Distribut ed optimiz ation with arbitrary local solvers, ” Optimizati on Methods and Software , vol. 32, no. 4, pp. 813–848, Aug 2017. [19] O. Shamir and N. Srebro, “Distribu ted s tochastic optimizati on and learni ng, ” in 52nd Annual A llerton Confer ence on Communication, Contr ol, and Computing . IEEE, Sep 29–Oct 3, 2014, pp. 850–857. [20] Y . Bao, Y . Peng, C. Wu, and Z . Li, “Online job scheduling in distrib uted machine learning clusters, ” arXiv prepri nt arXiv:1801.00936 , Jun 2018. [21] F . N. Iandola, M. W . Moske wicz, K. Ashraf, and K. Keu tzer , “Firecaf fe: near -linea r accelera tion of deep neural netwo rk training on compute clusters, ” in Proc . of the IEEE Confere nce on Computer V ision and P attern Recogni tion , Las V egas, Nev ada, June 2016, pp. 2592–2600. [22] N. H. Tran , W . Bao, A. Zomaya, N. M. NH, and C. S. Hong, “Federat ed learni ng over wireless networks: Optimizatio n model design and anal- ysis, ” in IEE E Confer ence on Comput er Communicat ions (INFOCOM) , Paris, France, April 29–May 2, 2019, pp. 1387–1395. [23] A. K. Sahu, T . L i, M. Sanjabi, M. Zaheer , A. T alwal kar , and V . Smith, “Federa ted optimiza tion for heterogeneous network s, ” arXiv preprin t arXiv:1812.06127 v2 , Dec 14, 2018. [24] Y . Lin, S. Han, H. Mao, Y . W ang, and W . J. Dally , “Deep gradient compression: Reducing the communication bandwidth for distribu ted traini ng, ” arXiv preprint , 2017. [25] S. U. Stich, “Local sgd con verges fast and communicates little , ” arXiv pre print arXiv:1805.09767 , 2018. [26] O. Shamir , N. Srebro, and T . Zhang, “Communication -ef ficient dis- trib uted optimizati on using an approximate ne wton-typ e m ethod, ” in Internati onal confere nce on machine learning , Beijing, China, June 2014, pp. 1000–1008. [27] J. W ang and G. Joshi, “ Adapti ve communicat ion strate gies to achie ve the best error-ru ntime trade-o ff in local-upd ate sgd, ” arXiv pre print arXiv:1810.08313 , 2018. [28] Z. W ang, M. Song, Z. Zhang, Y . Song, Q. W ang, and H. Q i, “Bey ond inferrin g class represent ati ves: User -le vel pri v ac y leaka ge from federate d learni ng, ” in IEE E Confer ence on Computer Communicat ions (INFO- COM) , Paris, France, April 29–May 2, 2019, pp. 2512–2520. [29] S. Samarakoon , M. Bennis, W . Saady , and M. Debbah, “Distribu ted fed- erated learni ng for ultra-rel iable low-l atenc y vehi cular communications, ” arXiv preprin t arXiv:1807.08127 , J ul 2018. 15 [30] G. Zhu, D. Liu, Y . Du, C. Y ou, J. Zhang, and K. Huang, “T ow ards an intelligen t edge: W irele ss communication meets machine learning, ” arXiv preprin t arXiv:1809.00343 , Sep 2018. [31] X. Z hang, Z. Y ang, Y . Liu, J. Li, and Z. Ming, “T oward ef ficient mechanisms for mobile crowdsensi ng, ” IEEE T ransac tions on V ehicul ar T echnolo gy , vol. 66, no. 2, pp. 1760–1771, 2016. [32] Y . W ei, Y . Zhu, H. Zhu, Q. Zhang, and G. Xue, “Trut hful online double aucti ons for dynamic mobile cro wdsourcing, ” in IEEE Confer ence on Computer Communica tions (INFOCOM) , Hong Kong, April 26–May 12, 2015, pp. 2074–2082. [33] H. Jin, L . Su, H. Xiao, and K. Nahrstedt, “Incent i ve mechanism for priv acy-aw are data aggregati on in mobile cro wd sensing systems, ” IEEE/ACM T ransactions on Networking (TON) , vol. 26, no. 5, pp. 2019– 2032, 2018. [34] Y . Zhang, C. Jiang, L. Song, M. Pan, Z. Dawy , and Z. Han, “Incenti ve mechanism for mobile cro wdsourcing using an optimize d tournament model, ” IEE E Journa l on Selected Areas in Communications , vol. 35, no. 4, pp. 880–892, 2017. [35] Y . W en, J. Shi, Q. Zhang, X. Tia n, Z. Huang, H. Y u, Y . Cheng, and X. Shen, “Quali ty-dri ven auction-ba sed incent i ve m echani sm for mobile cro w d sensing, ” IEEE T ransact ions on V ehicul ar T echn olog y , vol. 64, no. 9, pp. 4203–4214, Sept 2015. [36] L. Duan, T . Kubo, K. Sugiyama, J . Huang, T . Hasegaw a, and J. W alrand, “Moti vati ng smartphone collabor ation in data acquisition and distribut ed computing , ” IEEE T ransactions on Mobile Computing , vol. 13, no. 10, pp. 2320–2333, 2014. [37] D. Y ang, G. Xue, X. Fang , and J. T ang, “Cro wdsourcing to smartphones: incent i ve mechanism design for m obile phone sensing, ” in Pr oc. of the 18th annual internat ional confer ence on Mobile computin g and networki ng . AC M, Istanbul, Turk ey , August 2012, pp. 173–184. [38] S. Boyd, N. Parik h, E. Chu, B. Peleato, J. Eckstein et al. , “Distribute d optimiza tion and statisti cal learni ng via the alternat ing directio n method of multipli ers, ” F oundations and T rends R in Mach ine learning , vol. 3, no. 1, pp. 1–122, Jan 2011. [39] S. Shale v-Shwart z and T . Zhang, “ Accel erate d proximal stochastic dual coordina te ascent for regulariz ed loss minimiza tion, ” in Internati onal Confer ence on Machine Learning , Beijing, China, June 2014, pp. 64– 72. [40] S. Boyd and L. V andenbe rghe , Con vex optimization . C ambridge uni versity press, 2004. [41] D. Niyato, M. A. Alsheikh, P . W ang, D. I. Kim, and Z . Han, “Market model and optimal pricing scheme of big data and internet of things (iot), ” in IE EE International Confer ence on Communications (ICC) , Kual a Lumpur , Malaysia, May 2016, pp. 1–6. [42] J. Kone ˇ cn ` y, Z. Qu, and P . Richt ´ arik, “Semi-stochasti c coordinate de- scent, ” Optimizatio n Methods and Software , vol. 32, no. 5, pp. 993– 1005, Feb 2017. [43] C. Dinh, N. H. Tran, M. N. Nguyen, C. S. Hong, W . Bao, A. Zomaya, and V . Gramoli, “Federated learning over wireless net- works: Con ver gence analysis and resource alloc ation, ” arX iv preprint arXiv:1910.13067 , 2019. [44] Y . Liu, R. W ang, and Z . Han, “Interference -constrained pricing for d2d netw orks, ” IEEE T ransactions on W ir eless Communication s , vol. 16, no. 1, pp. 475–486, 2017. [45] J. L i, H. Chen, Y . Chen, Z. Lin, B. V ucetic, and L . Hanzo, “Pricing and resource allocati on via game theory for a small-cell video caching system, ” IEEE Journal on Selec ted Areas in Communicati ons , vol. 34, no. 8, pp. 2115–2129, 2016. [46] B. Falti ngs, J. J. L i, and R. Jurca, “Incent i ve mechanisms for community sensing, ” IEEE T ransactions on Computers , vol. 63, no. 1, pp. 115–128, 2014. [47] S. D. Conte and C. De Boor , Elementary numerical analysis: an algorithmi c appr oach . SIAM, Dec 2017, vol. 78. [48] J. Y u, M. H. Cheung, J. Huang, and H. V . Poor , “Mobile data trading: Beha vioral econo mics analysis and algorithm design , ” IEEE J ournal on Selec ted Areas in Communications , vol. 35, no. 4, pp. 994–1005, 2017. [49] Y . Jiao, P . W ang, S. Feng, and D. Niyato, “Profit maximizat ion mecha- nism and data management for data analyti cs services, ” IEEE Internet of Things Journal , vol. 5, no. 3, pp. 2001–2014, 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment