Optimizing Deep Neural Network Architecture: A Tabu Search Based Approach
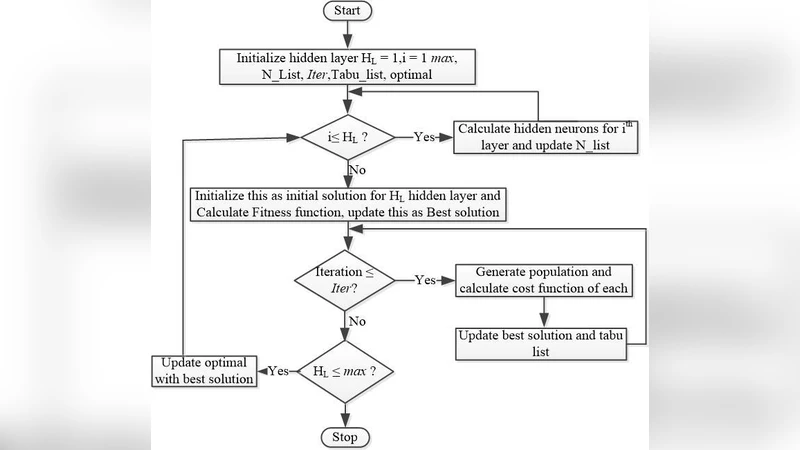
The performance of Feedforward neural network (FNN) fully de-pends upon the selection of architecture and training algorithm. FNN architecture can be tweaked using several parameters, such as the number of hidden layers, number of hidden neurons at each hidden layer and number of connections between layers. There may be exponential combinations for these architectural attributes which may be unmanageable manually, so it requires an algorithm which can automatically design an optimal architecture with high generalization ability. Numerous optimization algorithms have been utilized for FNN architecture determination. This paper proposes a new methodology which can work on the estimation of hidden layers and their respective neurons for FNN. This work combines the advantages of Tabu search (TS) and Gradient descent with momentum backpropagation (GDM) training algorithm to demonstrate how Tabu search can automatically select the best architecture from the populated architectures based on minimum testing error criteria. The proposed approach has been tested on four classification benchmark dataset of different size.
💡 Research Summary
The paper addresses the problem of automatically determining the architecture of feed‑forward neural networks (FNNs), specifically the number of hidden layers and the number of neurons in each hidden layer. Manual trial‑and‑error design is infeasible for realistic problems because the combinatorial space of possible architectures grows exponentially. To tackle this, the authors propose a hybrid meta‑heuristic that couples Tabu Search (TS) with Gradient Descent with Momentum (GDM) back‑propagation.
Methodology
The approach starts with a simple FNN that has a single hidden layer; the number of hidden neurons is randomly drawn from a range proportional to the sum of input and output units. An architecture is encoded as a three‑tuple ⟨HL, HN, E⟩ where HL is the number of hidden layers, HN is a vector of neuron counts per layer, and E is the testing error obtained after training the network with GDM.
In each iteration, a population of candidate architectures is generated. The population size P is split equally: half of the candidates increase the neuron count in a randomly chosen layer, the other half decrease it. The increase/decrease magnitude is controlled by a uniformly distributed random number in
Comments & Academic Discussion
Loading comments...
Leave a Comment