Testing Machine Translation via Referential Transparency
Machine translation software has seen rapid progress in recent years due to the advancement of deep neural networks. People routinely use machine translation software in their daily lives, such as ordering food in a foreign restaurant, receiving medical diagnosis and treatment from foreign doctors, and reading international political news online. However, due to the complexity and intractability of the underlying neural networks, modern machine translation software is still far from robust and can produce poor or incorrect translations; this can lead to misunderstanding, financial loss, threats to personal safety and health, and political conflicts. To address this problem, we introduce referentially transparent inputs (RTIs), a simple, widely applicable methodology for validating machine translation software. A referentially transparent input is a piece of text that should have similar translations when used in different contexts. Our practical implementation, Purity, detects when this property is broken by a translation. To evaluate RTI, we use Purity to test Google Translate and Bing Microsoft Translator with 200 unlabeled sentences, which detected 123 and 142 erroneous translations with high precision (79.3% and 78.3%). The translation errors are diverse, including examples of under-translation, over-translation, word/phrase mistranslation, incorrect modification, and unclear logic.
💡 Research Summary
Machine translation (MT) has become ubiquitous thanks to recent advances in neural machine translation (NMT), yet commercial systems such as Google Translate and Bing Microsoft Translator still produce erroneous outputs that can cause serious misunderstandings, financial loss, or even threats to personal safety. Traditional testing approaches struggle because (1) most parallel corpora have already been used for training, leaving few high‑quality oracles; (2) the translation logic is embedded in massive neural networks, making code‑level testing infeasible; and (3) the output space is huge and often ambiguous, so a simple reference translation is insufficient.
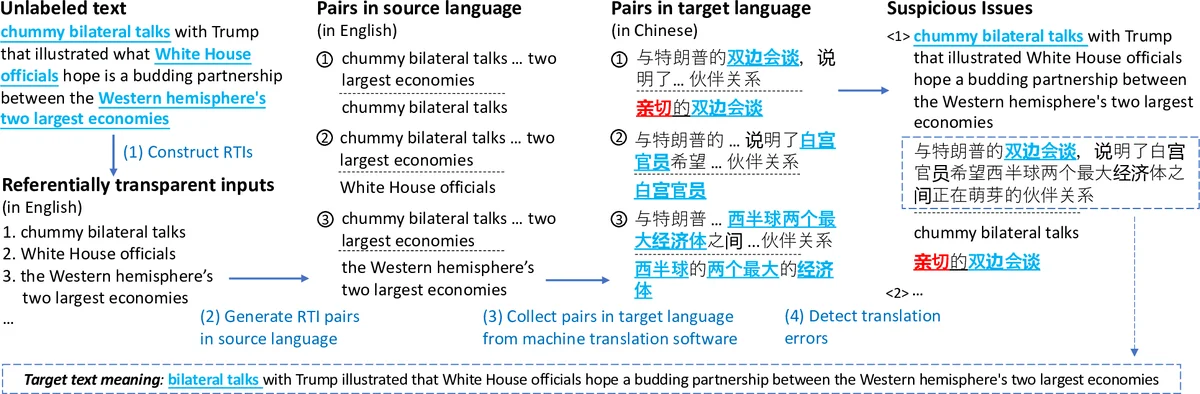
To address these challenges, the authors introduce Referentially Transparent Inputs (RTIs), a novel metamorphic testing concept inspired by referential transparency in functional programming. An RTI is a text fragment—specifically a noun phrase (NP) in this work—that should yield similar translations regardless of the surrounding context. The key metamorphic relation is: for any two contexts C₁ and C₂ that embed the same RTI r, the distance between the translations of r in T(C₁(r)) and T(C₂(r)) must be below a developer‑chosen threshold d. Violations indicate a potential translation bug.
The implementation, named Purity, follows four steps:
- Identify RTIs – Using a constituency parser, all NPs are extracted from each source sentence. Filters remove very short phrases, overly long phrases, and those dominated by stop‑words, leaving only semantically stable units.
- Generate RTI pairs – Each RTI is paired with (a) the full sentence that originally contains it, and (b) any larger NP that also contains it. This yields two different contexts C₁ and C₂ for the same fragment.
- Collect translations – Both contexts are sent to the MT system under test; the full translations and the sub‑translations corresponding to the RTI are recorded.
- Detect errors – The sub‑translations are represented as bag‑of‑words (BoW). The distance metric is the size of the symmetric difference between the two BoWs. If this distance exceeds d, the pair is flagged as a “suspicious issue”.
The approach is deliberately lightweight: it does not require sophisticated semantic similarity models, only a simple BoW comparison and a manually tuned threshold.
Evaluation: The authors crawled 200 English sentences from CNN (the same dataset used in prior work) and applied Purity to Google Translate and Bing Translator. For Google, Purity generated 154 suspicious pairs, of which 123 were confirmed as genuine errors, yielding a precision of 79.3 %. For Bing, 177 pairs were generated, 142 confirmed, giving 78.3 % precision. The detected errors span a wide spectrum: under‑translation (missing essential content), over‑translation (adding spurious material), word/phrase mistranslation, incorrect morphological modification, and logical incoherence. Compared with previous metamorphic testing methods that replace a single word while keeping the rest of the sentence fixed, Purity discovers many additional bugs because it varies the entire surrounding context. Runtime measurements show an average of 12.74 seconds per request for Google and 73.14 seconds for Bing, comparable to or better than earlier techniques.
Limitations and Future Work: The current prototype focuses exclusively on noun phrases; extending RTIs to verb phrases, clauses, or multi‑word expressions could broaden coverage. The BoW distance may miss subtle semantic shifts (e.g., synonym substitution); integrating contextual embeddings (BERT, XLM‑R) could improve sensitivity while preserving efficiency. The threshold d is set empirically; automated tuning via Bayesian optimization or reinforcement learning is an open direction. Finally, the authors plan to evaluate multilingual settings (e.g., Korean, Arabic) to verify the generality of the RTI concept.
Conclusion: By importing the notion of referential transparency into MT testing, the paper provides a simple yet powerful metamorphic oracle that can automatically flag inconsistent translations across varied contexts. The Purity tool demonstrates that even with minimal linguistic resources, high‑precision error detection is achievable on large‑scale commercial systems. This work therefore represents a significant step toward systematic, scalable quality assurance for modern neural machine translation services.
Comments & Academic Discussion
Loading comments...
Leave a Comment