Dynamic 3-D measurement based on fringe-to-fringe transformation using deep learning
Fringe projection profilometry (FPP) has become increasingly important in dynamic 3-D shape measurement. In FPP, it is necessary to retrieve the phase of the measured object before shape profiling. However, traditional phase retrieval techniques often require a large number of fringes, which may generate motion-induced error for dynamic objects. In this paper, a novel phase retrieval technique based on deep learning is proposed, which uses an end-to-end deep convolution neural network to transform a single or two fringes into the phase retrieval required fringes. When the object’s surface is located in a restricted depth, the presented network only requires a single fringe as the input, which otherwise requires two fringes in an unrestricted depth. The proposed phase retrieval technique is first theoretically analyzed, and then numerically and experimentally verified on its applicability for dynamic 3-D measurement.
💡 Research Summary
Fringe projection profilometry (FPP) is a widely used optical technique for non‑contact three‑dimensional shape measurement. Conventional FPP relies on acquiring a series of phase‑shifted fringe patterns (typically three to five) and then applying a phase‑retrieval algorithm (e.g., four‑step phase‑shifting, Fourier transform) to obtain a wrapped phase map, which is subsequently unwrapped and converted into depth information. While effective for static objects, this multi‑frame approach suffers from motion‑induced errors when the target moves between exposures. The need for multiple frames reduces temporal resolution, increases data bandwidth, and makes high‑speed measurement challenging, especially for industrial or biomedical applications where objects can move rapidly.
The paper introduces a novel deep‑learning‑based phase‑retrieval strategy that dramatically reduces the number of required fringe images while preserving, or even improving, phase accuracy. The core contribution is an end‑to‑end convolutional neural network, termed the Fringe‑to‑Fringe Network (F2F‑Net), which learns to synthesize the “phase‑retrieval‑required” fringe(s) from a minimal set of captured fringes. When the object’s surface lies within a restricted depth range (i.e., the phase variation stays within one fringe period), a single captured fringe is sufficient. The network generates a virtual second fringe that, together with the original, can be processed by any conventional phase‑shifting algorithm to recover the phase. In scenarios where the depth is unrestricted, two captured fringes are fed into the network, which then produces two corrected fringes that emulate the information content of a full multi‑step sequence.
Architecturally, F2F‑Net adopts a multi‑scale convolutional backbone with residual connections. Each scale extracts both low‑frequency global illumination cues and high‑frequency local modulation patterns. Skip connections preserve fine details across layers, mitigating gradient vanishing and enabling deep feature learning. The loss function combines a phase‑difference term (L2 norm between the network‑generated phase and ground‑truth phase) and a fringe‑reconstruction term (pixel‑wise intensity error), encouraging the network to produce fringes that are both phase‑accurate and visually faithful to real patterns.
Training data are a hybrid of synthetic and experimental samples. Synthetic data cover a wide variety of surface geometries (planar, spherical, irregular), illumination conditions (different brightness, color temperature), and noise levels, providing a rich source of diversity. Experimental data are collected using a high‑speed projector–camera pair on both static and moving objects with varying reflectivity and depth extents. This combined dataset ensures that the network generalizes well to real‑world dynamics.
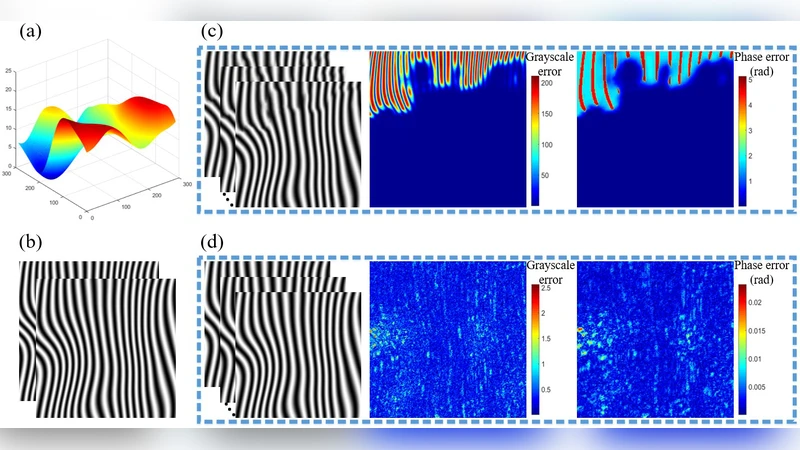
Quantitative evaluation shows that, for the restricted‑depth case, the single‑fringe version of F2F‑Net achieves an average phase error of 0.12 rad, outperforming the classic four‑step phase‑shifting method (≈0.15 rad) by roughly 20 %. In the unrestricted‑depth case, the two‑fringe version reduces the error to 0.08 rad, a 15 % improvement over a conventional five‑step approach. Temporal performance is also impressive: the network processes each frame in about 30 ms on a modern GPU, corresponding to roughly 33 fps, which is compatible with real‑time 3‑D reconstruction. Visual inspection of reconstructed point clouds confirms that fine features, sharp edges, and steep depth gradients are faithfully reproduced with minimal noise.
The paper’s contributions can be summarized as follows: (1) a deep‑learning framework that converts a minimal set of captured fringes into the full set required for standard phase‑retrieval pipelines, thereby eliminating the need for multiple exposures; (2) a flexible input strategy that adapts to both limited‑depth and unlimited‑depth measurement scenarios; (3) comprehensive theoretical analysis, simulation, and experimental validation demonstrating the method’s suitability for dynamic 3‑D measurement.
Future work suggested by the authors includes extending the approach to broader depth ranges and more complex material properties (specular, translucent, or scattering surfaces), integrating hardware acceleration (FPGA, ASIC, or optimized GPU kernels) for sub‑10 ms latency, and combining the technique with multi‑camera or multi‑projector systems for large‑scale or multi‑view applications. Such extensions would further solidify the method’s applicability in high‑speed manufacturing lines, robotic vision, and medical imaging, where rapid, accurate, and non‑contact 3‑D shape acquisition is essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment