Usage Bibliometrics as a Tool to Measure Research Activity
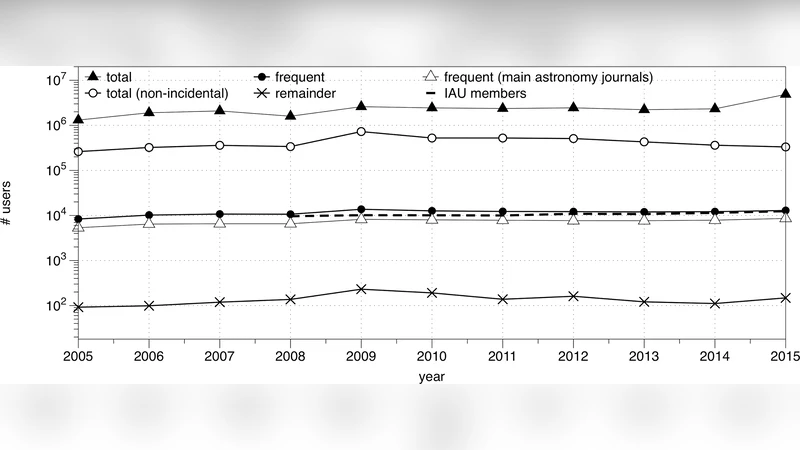
Measures for research activity and impact have become an integral ingredient in the assessment of a wide range of entities (individual researchers, organizations, instruments, regions, disciplines). Traditional bibliometric indicators, like publication and citation based indicators, provide an essential part of this picture, but cannot describe the complete picture. Since reading scholarly publications is an essential part of the research life cycle, it is only natural to introduce measures for this activity in attempts to quantify the efficiency, productivity and impact of an entity. Citations and reads are significantly different signals, so taken together, they provide a more complete picture of research activity. Most scholarly publications are now accessed online, making the study of reads and their patterns possible. Click-stream logs allow us to follow information access by the entire research community, real-time. Publication and citation datasets just reflect activity by authors. In addition, download statistics will help us identify publications with significant impact, but which do not attract many citations. Click-stream signals are arguably more complex than, say, citation signals. For one, they are a superposition of different classes of readers. Systematic downloads by crawlers also contaminate the signal, as does browsing behavior. We discuss the complexities associated with clickstream data and how, with proper filtering, statistically significant relations and conclusions can be inferred from download statistics. We describe how download statistics can be used to describe research activity at different levels of aggregation, ranging from organizations to countries. These statistics show a correlation with socio-economic indicators. A comparison will be made with traditional bibliometric indicators. We will argue that astronomy is representative of more general trends.
💡 Research Summary
The paper argues that traditional bibliometric indicators—primarily publication counts and citation metrics—capture only a limited facet of scholarly activity. While citations reflect the downstream acknowledgment of a work, they do not account for the essential intermediate step of reading, which constitutes a substantial portion of the research life cycle. With the universal migration of scholarly content to online platforms, every access event generates a click‑stream log that can be harvested in real time. The authors propose to treat these access events, after rigorous cleaning, as a quantitative “read” metric that complements existing citation‑based measures.
The authors first describe the inherent complexities of click‑stream data. Raw download logs are contaminated by non‑human traffic such as web crawlers, automated scripts, and bulk institutional downloads. To isolate genuine scholarly reads, they implement a multi‑layered filtering pipeline: (1) IP‑address clustering to identify and exclude known crawler ranges; (2) User‑Agent string parsing to separate bots from browsers; (3) temporal pattern analysis to detect abnormal spikes indicative of batch processing; and (4) statistical outlier detection based on download frequency distributions. After this cleaning, the remaining download counts are defined as “read counts.”
Statistical analysis then compares read counts with traditional citation counts across a five‑year window for a large corpus of astronomy papers. Pearson and Spearman correlation coefficients reveal a moderate positive relationship, but the strength varies by document age and research type. Recent, data‑driven, or applied studies often exhibit high read counts with modest citation numbers, suggesting that reads capture immediate relevance and usage that citations, which accrue over longer periods, may miss.
Beyond article‑level analysis, the study aggregates read metrics at institutional and national levels. Using multivariate regression, the authors examine the association between aggregated read counts and macro‑economic variables such as gross domestic product (GDP), research‑and‑development (R&D) expenditure as a percentage of GDP, the proportion of the population with tertiary education, and a composite science‑infrastructure index. The results demonstrate statistically significant positive coefficients for all these variables, indicating that richer, more research‑intensive economies generate higher scholarly reading activity. Notably, some smaller nations achieve disproportionately high read efficiency relative to their R&D spending, highlighting the potential of read metrics to uncover “punch‑above‑weight” research ecosystems.
Astronomy serves as a case study because the field is heavily reliant on large, openly shared datasets and rapid dissemination of results. The authors extract click‑stream logs from the leading astronomy journals and pre‑print servers, apply their cleaning protocol, and compute read scores for each contributing institution. When juxtaposed with citation‑based impact scores, certain institutions display markedly higher read scores, suggesting that they are hubs for data reuse, early‑stage collaboration, or effective open‑access policies. Temporal analysis further shows that read spikes often precede citation peaks, reinforcing the notion that reads are an early indicator of scholarly attention.
The paper concludes that click‑stream derived read metrics provide a valuable, complementary dimension to traditional bibliometrics. They enable real‑time monitoring of research uptake, expose usage patterns invisible to citation analysis, and correlate meaningfully with broader socio‑economic indicators. However, the authors acknowledge limitations: the necessity of sophisticated filtering to mitigate bot noise, the variability of reading behavior across disciplines, and the current lack of standardized reporting for read data. They propose future work involving machine‑learning‑based anomaly detection to automate cleaning, longitudinal modeling to link reads and citations over extended periods, and cross‑disciplinary validation to assess generalizability.
In sum, the study makes a compelling case that incorporating usage‑based bibliometrics into research assessment frameworks can yield a more nuanced, timely, and equitable picture of scientific activity, informing funding decisions, institutional strategies, and policy formulation.
Comments & Academic Discussion
Loading comments...
Leave a Comment