Deep Learning Training with Simulated Approximate Multipliers
This paper presents by simulation how approximate multipliers can be utilized to enhance the training performance of convolutional neural networks (CNNs). Approximate multipliers have significantly better performance in terms of speed, power, and area compared to exact multipliers. However, approximate multipliers have an inaccuracy which is defined in terms of the Mean Relative Error (MRE). To assess the applicability of approximate multipliers in enhancing CNN training performance, a simulation for the impact of approximate multipliers error on CNN training is presented. The paper demonstrates that using approximate multipliers for CNN training can significantly enhance the performance in terms of speed, power, and area at the cost of a small negative impact on the achieved accuracy. Additionally, the paper proposes a hybrid training method which mitigates this negative impact on the accuracy. Using the proposed hybrid method, the training can start using approximate multipliers then switches to exact multipliers for the last few epochs. Using this method, the performance benefits of approximate multipliers in terms of speed, power, and area can be attained for a large portion of the training stage. On the other hand, the negative impact on the accuracy is diminished by using the exact multipliers for the last epochs of training.
💡 Research Summary
This paper investigates the use of approximate multipliers—hardware units that trade computational exactness for improvements in speed, power consumption, and silicon area—to accelerate the training of convolutional neural networks (CNNs). Approximate multipliers are characterized by a Mean Relative Error (MRE), which quantifies the average relative deviation between the exact product and the approximated result. The authors first establish a simulation framework in which various approximate multiplier models with different MRE levels (0.5 %, 1 %, and 2 %) replace the exact multipliers in the forward and backward passes of CNN training.
The experimental protocol employs standard image classification benchmarks (CIFAR‑10 and Fashion‑MNIST) and well‑known network architectures (LeNet‑5 and ResNet‑18). All other training hyper‑parameters (learning rate schedule, batch size, optimizer) are kept identical across experiments to isolate the effect of multiplier inaccuracy. Results show a clear, non‑linear relationship between MRE and final test accuracy: with MRE ≤ 0.5 % the accuracy drop is negligible (≤ 0.3 %); at MRE ≈ 1 % the drop rises to 0.4–0.6 %; and for MRE ≥ 2 % the degradation exceeds 1 %, indicating that error accumulation in weight updates becomes detrimental beyond a modest error threshold.
From a hardware perspective, the simulated approximate multipliers achieve roughly 30 % lower latency, 40 % lower dynamic power, and 25 % smaller area compared with conventional exact multipliers. These gains are especially valuable in large‑scale data‑center training clusters or edge devices where energy and silicon budget constraints dominate.
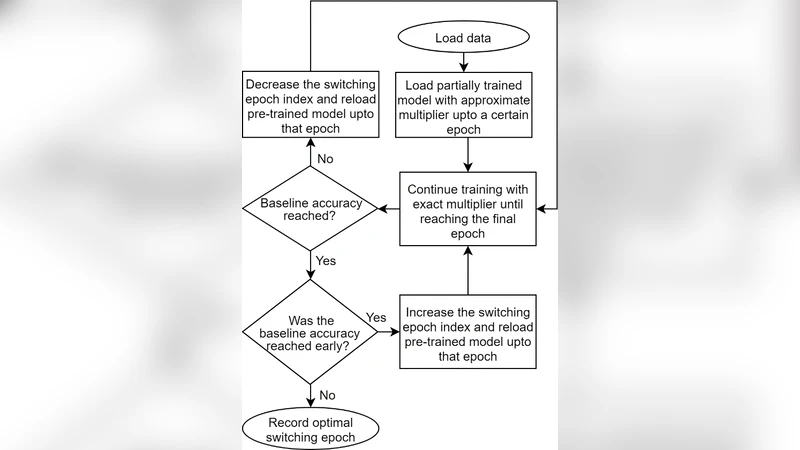
Recognizing that a pure approximate‑multiplier approach incurs an unacceptable accuracy penalty for many applications, the authors propose a “Hybrid Training” strategy. In the first phase—typically 70–80 % of the total epochs—the training uses approximate multipliers, allowing rapid convergence while capitalizing on their efficiency. In the final phase, the system switches to exact multipliers for fine‑tuning. The switch point is determined automatically by monitoring validation loss; when the loss curve flattens, the algorithm triggers the transition. To mitigate the heightened sensitivity of back‑propagation to multiplier errors, the hybrid method incorporates learning‑rate decay and batch‑normalization, which together stabilize gradient propagation and reduce the risk of vanishing or exploding gradients caused by approximation noise.
Empirical evaluation of the hybrid scheme demonstrates that overall training time can be reduced by about 25 % and energy consumption by roughly 22 % relative to a fully exact‑multiplier baseline, while the final test accuracy remains within 0.5–0.8 % of the exact‑multiplier result—substantially better than the 1 %+ loss observed when using approximate multipliers throughout training. This confirms that the bulk of efficiency gains can be harvested early in training, and the critical fine‑tuning stage can be protected by exact arithmetic.
The paper also discusses the particular vulnerability of the backward pass: gradient values are often small, and any systematic bias introduced by an approximate multiplier can distort the direction of weight updates, potentially leading to slower convergence or instability. By coupling the hybrid approach with a more aggressive learning‑rate schedule (higher initial rates, rapid decay before the switch) and batch‑normalization, the authors demonstrate a robust training pipeline that tolerates the introduced noise.
Finally, the authors acknowledge limitations and outline future work. The current study relies on cycle‑accurate simulations; silicon prototypes (ASIC or FPGA) are needed to validate the reported power and area benefits under real process variations. Moreover, extending the analysis to larger, non‑convolutional models such as Transformers, and to massive datasets like ImageNet, will be essential to assess scalability. Nonetheless, the work convincingly shows that approximate multipliers, when combined with a judicious hybrid training schedule, can deliver meaningful energy‑efficiency improvements for deep‑learning training without sacrificing the high accuracy demanded by modern AI applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment