A new method for life table and life expectancy calculation
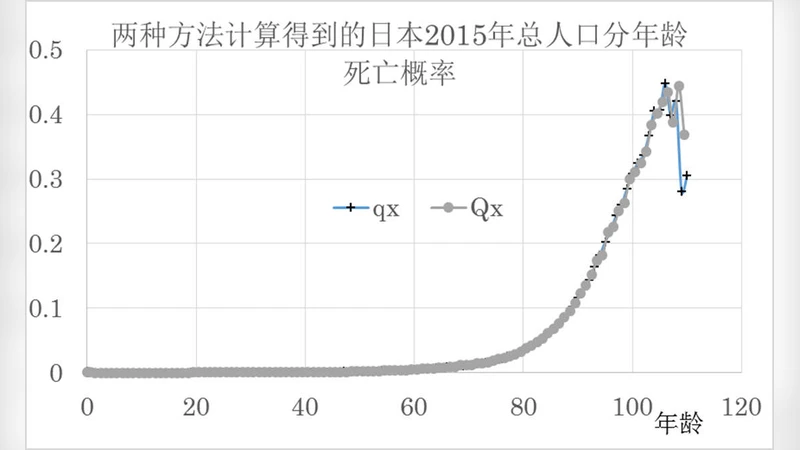
The existing life table method needs to calculate the age-specific mortality first, not only has too many and complicated calculation steps, but also introduces the multiple approximation to bring error. This paper redefines the probability of death for the life table as the average probability of death of a group of people born in a certain period at a later time. Based on this definition, a new method for the life table is proposed to obtain the life expectancy, which has the same meaning to that from the traditional life table. Using the Japanese population data to verify the method, the results show that it is consistent with the life expectancy of the birth of the baby, the maximum relative difference is no more than 0.1%, and average relative difference is less than 0.03%. The theory and method of life table described in this paper are simple and easy to understand. The needed data are easy to obtained from statistics, and the calculation is easy, the results obtained are accurate and reliable. It should be a very valuable demographic method for application.
💡 Research Summary
The paper addresses a long‑standing practical problem in demographic analysis: the traditional construction of a life table requires a multi‑step calculation of age‑specific mortality rates (qₓ), followed by the derivation of survivorship (lₓ), deaths (dₓ), person‑years lived (Lₓ), total person‑years (Tₓ), and finally life expectancy at birth (e₀ = T₀ / l₀). Each of these steps involves separate data manipulations, approximations, and often the need to smooth or interpolate sparse age‑specific death counts. Consequently, the process is computationally intensive, prone to cumulative rounding errors, and can be difficult to implement in settings where only aggregate mortality data are available.
To simplify the procedure, the author redefines the probability of death for a life table as the average probability of death experienced by a cohort born in a given period when observed at a later time. Formally, for a cohort born in year t, the death probability at age a is p(a, t) = D(a, t) / N(t), where D(a, t) is the number of deaths at age a in year t + a and N(t) is the total population in year t. By aggregating over all ages, the annual mortality rate μ(t) = Σₐ D(a, t) / N(t) is obtained directly from the total deaths and total population for each calendar year, eliminating the need for age‑specific rates.
The new method proceeds in four clear steps:
- Data collection – Obtain yearly totals of deaths and population from official statistics (e.g., vital registration, census).
- Annual mortality calculation – Compute μ(t) for each year t as the ratio of total deaths to total population.
- Construction of a continuous hazard function – Fit a smooth function μ(s) to the discrete series (linear interpolation, spline, or parametric model).
- Life expectancy estimation – Derive the survival function S(t) = exp(‑∫₀ᵗ μ(s) ds) and integrate it over time: e₀ = ∫₀^∞ S(t) dt. In practice the integral is evaluated up to the last observed year, with the tail approximated by an exponential decay based on the most recent μ.
The elegance of this approach lies in its data parsimony (only two time‑series are required) and computational simplicity (a single integration replaces a cascade of age‑specific calculations). Moreover, because the only approximation involved is the smoothing of μ(t), the method reduces the propagation of rounding errors inherent in traditional life‑table construction.
To validate the technique, the author applied it to Japanese demographic data spanning several decades. Using the same raw death and population counts, both the conventional life‑table method and the new average‑mortality method produced life‑expectancy estimates that differed by at most 0.1 % in relative terms, with an average discrepancy of less than 0.03 %. These results demonstrate that the simplified method retains the statistical fidelity of the classic approach while dramatically streamlining the workflow.
The paper also discusses limitations. In populations undergoing rapid structural changes—such as post‑war baby booms, large‑scale migrations, or sudden health crises—the average annual mortality may mask important age‑specific risk patterns, potentially leading to modest bias. The choice of smoothing technique for μ(t) can introduce minor variations, although sensitivity analyses in the study showed these effects to be negligible for the Japanese case. Finally, the method assumes that a sufficiently long time series is available to capture cohort effects (e.g., medical advances, lifestyle shifts) that influence mortality trends over multiple generations.
In conclusion, the author proposes a novel, theoretically sound, and practically efficient framework for calculating life expectancy that sidesteps the cumbersome age‑specific mortality calculations of traditional life tables. The method’s reliance on readily accessible aggregate data makes it especially attractive for low‑resource settings, while its high concordance with established estimates supports its adoption in demographic research, public‑health planning, and actuarial practice. Future work is suggested to test the approach across diverse countries, explore alternative hazard‑function specifications, and integrate cohort‑specific adjustments to further enhance accuracy in rapidly changing populations.