Automated Construction of Bounded-Loss Imperfect-Recall Abstractions in Extensive-Form Games
Extensive-form games (EFGs) model finite sequential interactions between players. The amount of memory required to represent these games is the main bottleneck of algorithms for computing optimal strategies and the size of these strategies is often impractical for real-world applications. A common approach to tackle the memory bottleneck is to use information abstraction that removes parts of information available to players thus reducing the number of decision points in the game. However, existing information-abstraction techniques are either specific for a particular domain, they do not provide any quality guarantees, or they are applicable to very small subclasses of EFGs. We present domain-independent abstraction methods for creating imperfect recall abstractions in extensive-form games that allow computing strategies that are (near) optimal in the original game. To this end, we introduce two novel algorithms, FPIRA and CFR+IRA, based on fictitious play and counterfactual regret minimization. These algorithms can start with an arbitrary domain specific, or the coarsest possible, abstraction of the original game. The algorithms iteratively detect the missing information they require for computing a strategy for the abstract game that is (near) optimal in the original game. This information is then included back into the abstract game. Moreover, our algorithms are able to exploit imperfect-recall abstractions that allow players to forget even history of their own actions. However, the algorithms require traversing the complete unabstracted game tree. We experimentally show that our algorithms can closely approximate Nash equilibrium of large games using abstraction with as little as 0.9% of information sets of the original game. Moreover, the results suggest that memory savings increase with the increasing size of the original games.
💡 Research Summary
The paper tackles the fundamental memory bottleneck that hampers the solution of large extensive‑form games (EFGs). Traditional information‑abstraction techniques either rely on domain‑specific knowledge (most notably in poker) or sacrifice any formal guarantee on the quality of the resulting strategy. Moreover, they typically enforce perfect recall, which forces the abstracted game to retain all historical information and consequently limits the achievable memory savings.
To overcome these limitations, the authors introduce two domain‑independent algorithms—FPIRA (Fictitious Play for Imperfect‑Recall Abstractions) and CFR+IRA (Counterfactual Regret Minimization Plus for Imperfect‑Recall Abstractions). Both algorithms start from an arbitrary abstraction, which may be as coarse as a single information set for each player, and iteratively refine it. The refinement loop works as follows: the algorithm solves the current abstract game, compares the observed convergence (or regret) with the theoretical convergence guarantees that hold for the original perfect‑recall game, and identifies those information sets where the discrepancy exceeds a user‑specified tolerance. Those sets are then split, restoring the missing information needed for accurate learning. This process repeats until the abstract game’s solution is provably within the desired distance from a Nash equilibrium of the original game.
FPIRA adapts the classic fictitious‑play dynamics to the imperfect‑recall setting. The authors show that the difference between the expected utilities of strategies obtained in the original game and those obtained in the abstraction can be used as a reliable signal for where the abstraction is too coarse. By repeatedly refining those problematic sets, FPIRA inherits the convergence guarantees of fictitious play for two‑player zero‑sum games.
CFR+IRA builds on the much faster CFR+ algorithm. It monitors the average external regret in the abstract game and compares it with the theoretical regret bound that CFR+ guarantees for the full perfect‑recall game. When the observed regret grows faster than the bound, the corresponding information sets are refined. The authors prove that the average regret of CFR+IRA remains bounded, ensuring convergence to a Nash equilibrium of the original game. They also propose a practical heuristic for selecting which sets to split, dramatically accelerating convergence in practice.
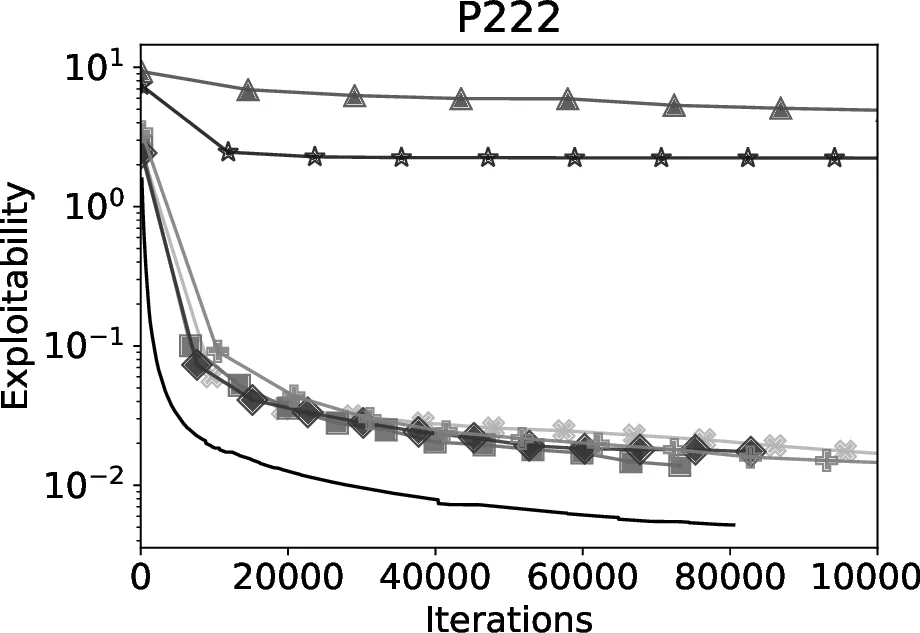
The experimental evaluation spans several domains, including large poker variants, security‑planning problems, and auction models. The results demonstrate that CFR+IRA can achieve an order‑of‑magnitude reduction in memory consumption compared with both the Double‑Oracle‑style DOEFG algorithm and FPIRA, while still converging at a speed comparable to running CFR+ on the full game. Remarkably, even when initialized with a trivial abstraction, CFR+IRA constructs an abstract game containing as little as 0.9 % of the original information sets yet still attains a Nash‑equilibrium approximation within the prescribed error margin. Moreover, the relative size of the constructed abstraction tends to shrink further as the underlying game grows, indicating that the approach scales favorably with problem size.
In summary, the paper delivers a principled, theoretically sound framework for automatically generating imperfect‑recall abstractions that dramatically cut memory requirements without sacrificing solution quality. By integrating refinement mechanisms into well‑established learning dynamics (fictitious play and CFR+), the authors provide practical algorithms that are applicable to any two‑player zero‑sum extensive‑form game, opening the door to solving much larger instances than previously feasible.
Comments & Academic Discussion
Loading comments...
Leave a Comment