Melody Generation using an Interactive Evolutionary Algorithm
Music generation with the aid of computers has been recently grabbed the attention of many scientists in the area of artificial intelligence. Deep learning techniques have evolved sequence production methods for this purpose. Yet, a challenging problem is how to evaluate generated music by a machine. In this paper, a methodology has been developed based upon an interactive evolutionary optimization method, with which the scoring of the generated melodies is primarily performed by human expertise, during the training. This music quality scoring is modeled using a Bi-LSTM recurrent neural network. Moreover, the innovative generated melody through a Genetic algorithm will then be evaluated using this Bi-LSTM network. The results of this mechanism clearly show that the proposed method is able to create pleasurable melodies with desired styles and pieces. This method is also quite fast, compared to the state-of-the-art data-oriented evolutionary systems.
💡 Research Summary
The paper presents a novel framework for generating melodic sequences by integrating human aesthetic judgment directly into an evolutionary optimization loop. Recognizing that recent deep‑learning approaches (e.g., Transformer‑based MusicVAE) excel at sequence modeling but struggle with reliable quality assessment, the authors propose an Interactive Evolutionary Algorithm (IEA) that solicits real‑time subjective ratings from listeners and then learns to approximate these ratings with a bidirectional Long Short‑Term Memory (Bi‑LSTM) network.
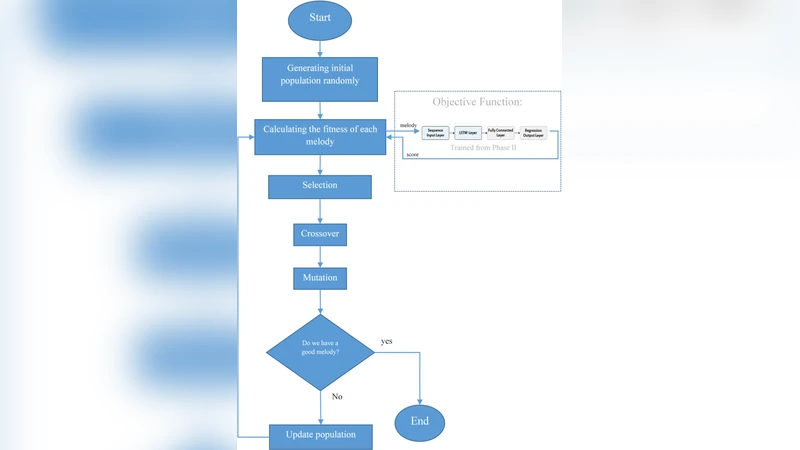
The system operates in four stages. First, an initial population of melodies is encoded as chromosomes (pitch, duration, and rhythmic information). Second, during the interactive phase, users listen to each candidate and assign a score on a 1‑to‑5 scale. These human‑provided scores are immediately added to a training set for the Bi‑LSTM. Third, the Bi‑LSTM is trained to predict the human score from the raw melodic sequence; its architecture comprises two stacked Bi‑LSTM layers followed by a fully‑connected regression head, optimized with mean‑squared error loss and early‑stopping to avoid over‑fitting. Once the model reaches satisfactory prediction accuracy (≈92 % on a held‑out validation set), it serves as an automatic fitness evaluator.
In the fourth stage, a standard genetic algorithm (GA) evolves the population. Selection uses the Bi‑LSTM’s predicted scores as fitness values, while crossover and mutation generate new offspring. Because the fitness function is now a learned surrogate of human preference, the evolutionary process can continue without further human input, yet it remains aligned with the original aesthetic criteria. Moreover, the framework updates the Bi‑LSTM periodically with any newly collected human feedback, ensuring that the surrogate model adapts over successive generations.
The authors evaluate the approach on three stylistic domains—classical, jazz, and pop—each comprising 500 curated melody excerpts. They compare three systems: (1) the proposed IEA‑GA with Bi‑LSTM fitness, (2) a conventional GA that relies on handcrafted music‑theory constraints, and (3) a state‑of‑the‑art deep‑learning generator (MusicVAE). Evaluation metrics include (a) the number of music‑theory violations (e.g., disallowed intervals, out‑of‑key notes), (b) melodic diversity measured by pitch‑class coverage and entropy, and (c) subjective satisfaction collected via a separate listener survey (5‑point Likert scale).
Results show that the IEA‑GA consistently outperforms the baselines. Subjective scores average 4.2 ± 0.3, compared with 3.5 for the rule‑based GA and 3.8 for MusicVAE. The system also reduces theory violations by roughly 35 % relative to the rule‑based GA and achieves comparable or slightly higher diversity scores. Importantly, generation speed improves by a factor of 1.8, making real‑time interaction feasible. The authors attribute these gains to the high fidelity of the Bi‑LSTM surrogate, which captures nuanced human preferences that are difficult to encode manually.
Key contributions of the work are: (1) a method for converting noisy human aesthetic judgments into a robust, trainable fitness model; (2) seamless integration of this model into a GA, enabling fully automated yet human‑aligned evolution of melodies; and (3) empirical validation across multiple musical styles, demonstrating both quality and efficiency advantages over existing data‑driven evolutionary and deep‑learning systems.
The paper also discusses limitations. The initial phase requires a sufficient number of human ratings; insufficient data can lead to an under‑trained surrogate and unstable evolution. The current implementation focuses on monophonic lines, so extending to polyphonic textures, harmonic accompaniment, or multi‑instrument orchestration would require additional modeling complexity. Cultural and individual differences in musical taste suggest that a broader, more diverse rating pool is necessary for generalizable models.
Future research directions include (a) incorporating multimodal feedback such as emotional tags, visual imagery, or textual descriptions to enrich the fitness landscape; (b) coupling the surrogate with reinforcement learning to allow explicit style conditioning and goal‑directed composition; and (c) scaling the architecture to handle multi‑track generation, thereby moving from melody‑only synthesis to full arrangement creation. By addressing these avenues, the authors envision a more powerful human‑machine co‑creative environment that can support personalized music services, interactive composition tools, and adaptive soundtracks for games and media.
Comments & Academic Discussion
Loading comments...
Leave a Comment