Adaptive Transformers in RL
Recent developments in Transformers have opened new interesting areas of research in partially observable reinforcement learning tasks. Results from late 2019 showed that Transformers are able to outperform LSTMs on both memory intense and reactive tasks. In this work we first partially replicate the results shown in Stabilizing Transformers in RL on both reactive and memory based environments. We then show performance improvement coupled with reduced computation when adding adaptive attention span to this Stable Transformer on a challenging DMLab30 environment. The code for all our experiments and models is available at https://github.com/jerrodparker20/adaptive-transformers-in-rl.
💡 Research Summary
This paper, titled “Adaptive Transformers in RL,” investigates the application of Transformer architectures, specifically those enhanced with adaptive attention mechanisms, to partially observable reinforcement learning tasks. The work builds upon the “Stable Transformer” model introduced in prior research, which successfully adapted the TransformerXL architecture for RL by modifying layer normalization placement to improve initial training stability.
The authors begin by partially replicating the results of the Stable Transformer study. They compare the performance of Stable Transformers against LSTMs in two types of environments: a reactive task (Atari Pong, an MDP) and a memory-intensive task (the rooms_select_nonmatching_object level from DMLab30, a POMDP). Their experiments confirm that deeper Stable Transformers can learn reactive tasks effectively, unlike deeper LSTMs which failed, and that Stable Transformers perform comparably to LSTMs on the initial phase of the memory-based DMLab task.
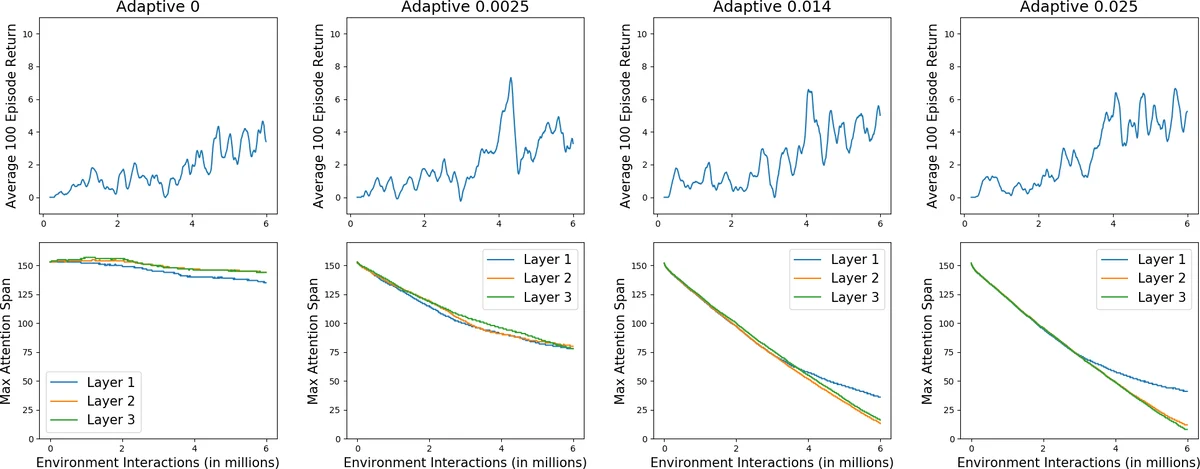
The core contribution of the paper is the integration of “Adaptive Attention Span” into the Stable Transformer architecture. This mechanism allows each attention head in the Transformer to learn a variable context length, selectively attending only to a relevant subset of past timesteps instead of the entire fixed memory block. This is achieved by introducing a learnable masking parameter per head, which smoothly gates attention weights based on the distance to past tokens. The primary hypothesized benefits are reduced computational cost and the ability to utilize a larger effective memory without a proportional increase in computation.
The authors test this hypothesis on the DMLab30 memory task. They configure the Adaptive Transformer with an initial memory length twice that of the standard Stable Transformer. Results demonstrate that the 3-layer Adaptive Transformer outperforms its non-adaptive counterpart, achieving a higher final average reward (8.84 vs. 7.17 over 100 episodes) and showing more stable learning with lower variance. Analysis of the learned attention spans reveals that the model self-regulates its structure: with appropriate L1 regularization on the span parameters, the top layers learned very short spans (2), effectively reducing their computational footprint, while the first layer maintained a longer span (33). This indicates the model learned both the necessary context size and the required network depth for the task.
The paper concludes by acknowledging limitations due to computational constraints, including a reduced model depth (3 layers vs. 12 in the original Stable Transformer paper) and a shorter training duration (6M frames). The authors suggest that the advantages of adaptive attention span would be more pronounced in environments requiring even longer-term dependencies and propose future work exploring persistent memory and GRU gating within this adaptive framework. Overall, the study provides evidence that adaptive attention span is a promising technique for improving the efficiency and performance of Transformers in reinforcement learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment