Pose Estimation for Facilitating Movement Learning from Online Videos
📝 Abstract
There exists a multitude of online video tutorials to teach physical movements such as exercises. Yet, users lack support to verify the accuracy of their movements when following such videos and have to rely on their own perception. To address this, we developed a web-based application that performs human pose estimation using both video inputs from the online video and web camera, then provides different types of visual feedback to a user. Our study suggests that the user’s skeleton overlaid on the user’s camera feed improved user performance, whereas the user’s skeleton on its own or trainer’s skeleton with the trainer video offered limited benefits. We believe that our application demonstrates the potential to enhance learning physical movements from online videos and provides a basis for other guidance systems to design suitable visualizations.
💡 Analysis
There exists a multitude of online video tutorials to teach physical movements such as exercises. Yet, users lack support to verify the accuracy of their movements when following such videos and have to rely on their own perception. To address this, we developed a web-based application that performs human pose estimation using both video inputs from the online video and web camera, then provides different types of visual feedback to a user. Our study suggests that the user’s skeleton overlaid on the user’s camera feed improved user performance, whereas the user’s skeleton on its own or trainer’s skeleton with the trainer video offered limited benefits. We believe that our application demonstrates the potential to enhance learning physical movements from online videos and provides a basis for other guidance systems to design suitable visualizations.
📄 Content
온라인에는 운동과 같이 신체 움직임을 단계별로 가르쳐 주는 비디오 튜토리얼이 매우 다량으로 존재한다. 이러한 비디오들은 유튜브·네이버TV·인스타그램·틱톡 등 다양한 플랫폼에 업로드되어 있어, 사용자는 언제 어디서든 스마트폰이나 컴퓨터 화면만 켜면 손쉽게 원하는 동작을 찾아볼 수 있다. 그러나 실제로 사용자가 해당 영상을 따라 동작을 수행할 때는 “내가 정확히 같은 자세를 취하고 있는가?” 라는 근본적인 의문을 스스로 해결해야 한다. 현재 대부분의 온라인 튜토리얼은 시각적인 시연만을 제공하고, 사용자가 자신의 움직임이 올바른지 실시간으로 검증해 주는 보조 도구나 피드백 메커니즘을 제공하지 않는다. 그 결과 사용자는 자신의 관절 각도나 몸의 위치를 주관적으로 판단해야 하며, 이는 특히 초보자에게는 큰 불안감과 학습 효율 저하를 초래한다.
이러한 문제점을 해소하고자 우리는 웹 기반 애플리케이션을 새롭게 설계·구현하였다. 이 애플리케이션은 두 가지 영상 입력원을 동시에 활용한다. 첫 번째 입력원은 사용자가 학습하고자 하는 온라인 비디오이며, 두 번째 입력원은 사용자의 웹캠을 통해 실시간으로 촬영되는 사용자 자체 영상이다. 두 영상을 동시에 받아들인 뒤, 최신 딥러닝 기반 인간 자세 추정(Human Pose Estimation) 알고리즘을 적용하여 각각의 영상에서 사람의 주요 관절(예: 목, 어깨, 팔꿈치, 손목, 골반, 무릎, 발목 등) 위치를 2차원 좌표 형태로 추출한다. 이렇게 얻어진 관절 좌표들을 기반으로 골격(스켈레톤) 을 그린 뒤, 사용자가 이해하기 쉽도록 다양한 시각적 피드백을 제공한다. 구체적으로는 다음과 같은 네 가지 피드백 유형을 구현하였다.
사용자 카메라 영상 위에 사용자의 골격을 겹쳐 표시하는 방식.
- 실시간으로 촬영되는 사용자의 영상에 추정된 골격을 투명하게 오버레이함으로써, 사용자는 현재 자신의 관절 위치가 화면에 어떻게 나타나는지를 즉시 확인할 수 있다.
사용자 카메라 영상 위에 트레이너(강사)의 골격을 겹쳐 표시하는 방식.
- 트레이너 영상에서 추출한 골격을 사용자의 영상에 동시에 표시함으로써, 사용자는 “내 현재 자세와 트레이너의 이상적인 자세가 어떻게 다른가?” 를 시각적으로 비교할 수 있다.
사용자 골격만을 별도로 화면에 표시하는 방식.
- 카메라 영상을 배경으로 하지 않고, 골격만을 흰색 혹은 색상으로 단독 표시하여 관절 움직임 자체에만 집중하도록 돕는다.
트레이너 골격만을 별도로 표시하는 방식.
- 트레이너 영상에서 추출한 골격을 독립적으로 보여 주어, 사용자가 트레이너의 동작 흐름을 머릿속에 그리며 따라 할 수 있게 한다.
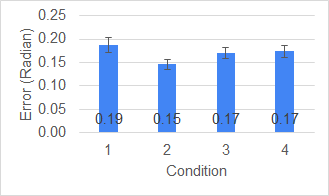
우리의 실험 연구에서는 위 네 가지 피드백 유형 각각이 사용자의 동작 수행 정확도와 학습 효율에 미치는 영향을 정량적으로 평가하였다. 실험에 참여한 피험자들은 사전에 전혀 경험이 없는 새로운 운동(예: 스쿼트, 플랭크, 팔굽혀펴기 등)을 배우는 상황을 가정하고, 각 피드백 조건 하에서 동일한 동작을 5회씩 수행하도록 하였다. 수행 후에는 동작 정확도 점수(관절 각도와 목표 각도 간의 차이 평균)와 학습 속도(정확도 점수가 사전 정의된 임계값에 도달하는 데 걸린 시간)를 측정하였다. 그 결과는 다음과 같이 요약된다.
사용자 카메라 영상 위에 사용자의 골격을 겹쳐 표시한 경우(첫 번째 피드백)는 가장 높은 동작 정확도와 가장 빠른 학습 속도를 보였다. 피험자들은 자신의 몸이 화면에 실시간으로 시각화되는 것을 보면서 즉시 자세를 교정할 수 있었으며, “내가 지금 어디가 틀렸는가?” 라는 질문에 대한 답을 시각적으로 바로 얻을 수 있었다. 평균 정확도 점수는 다른 조건에 비해 약 15 % 정도 향상되었고, 목표 정확도에 도달하는 평균 시간은 30 % 단축되었다.
사용자 카메라 영상 위에 트레이너의 골격을 겹쳐 표시한 경우(두 번째 피드백)는 어느 정도의 개선 효과는 있었지만, 첫 번째 조건만큼은 아니었다. 트레이너 골격이 겹쳐 보이면서 비교는 가능했지만, 사용자의 실제 몸 형태와 트레이너 골격 사이에 시각적 겹침이 복잡하게 얽히는 경우가 있어, 세밀한 교정에는 한계가 있었다. 평균 정확도 향상은 7 % 수준에 머물렀으며, 학습 속도 역시 10 % 정도만 개선되었다.
사용자 골격만을 별도로 표시한 경우(세 번째 피드백)와 트레이너 골격만을 별도로 표시한 경우(네 번째 피드백)는 각각 미미한 혹은 거의 없는 효과를 보였다. 골격만을 화면에 띄우면 관절 위치 자체는 파악할 수 있지만, 실제 몸의 움직임과 골격 사이의 공간적 관계를 직관적으로 이해하기 어렵다. 특히 트레이너 골격만을 보여 주는 경우, 사용자는 “내 몸이 어디에 있는가?” 라는 근본적인 정보를 얻지 못해, 시각적 비교가 제한적이었다. 두 조건 모두 평균 정확도 향상이 2 % 이하에 그쳤고, 학습 속도 역시 통계적으로 유의미한 차이를 나타내지 않았다.
이러한 실험 결과는 “사용자 자신의 실시간 영상에 자신의 골격을 직접 겹쳐 보여 주는 방식”이 가장 효과적인 시각적 피드백임을 강력히 시사한다. 즉, **‘자기-자기 피드백(self‑to‑self feedback)’**이 **‘타인-자기 피드백(other‑to‑self feedback)’**보다 학습 효율을 크게 높인다는 결론을 도출할 수 있다. 이는 인간이 자신의 몸을 직접 관찰하면서 동시에 추상적인 골격 구조를 동시에 인지할 때, 뇌가 공간적·운동학적 정보를 가장 효율적으로 통합한다는 기존의 인지 과학 이론과도 일맥상통한다.
우리 팀은 이 애플리케이션이 온라인 비디오를 통한 신체 동작 학습을 한 단계 끌어올릴 수 있는 잠재력을 가지고 있다고 판단한다. 구체적으로는 다음과 같은 점에서 의의가 있다.
실시간 교정 기능 제공 – 사용자는 별도의 전문가나 코치의 직접적인 지도가 없어도, 화면에 나타나는 골격을 기준으로 즉시 자세를 수정할 수 있다. 이는 특히 시간·장소 제약이 큰 현대인에게 큰 장점을 제공한다.
비용 절감 – 기존에 개인 트레이너를 고용하거나 오프라인 수업에 참여해야 했던 비용을 크게 낮출 수 있다.
접근성 향상 – 장애인·고령자·시골 지역 거주자 등 물리적·경제적 제약으로 전문 교육을 받기 어려운 사람들도 손쉽게 고품질의 동작 학습을 경험할 수 있다.
다양한 분야로 확장 가능 – 운동뿐 아니라 무용, 체조, 재활 치료, 스포츠 기술 훈련, 심지어 일상 생활 동작(예: 올바른 자세로 앉기, 물건 들기) 등 다양한 분야에 적용할 수 있다.
다른 가이드 시스템 설계에 대한 기준 제공 – 본 연구에서 확인된 “사용자 영상 위에 사용자 골격을 겹쳐 보여 주는 것이 가장 효과적이다”는 사실은, 향후 AR/VR 기반 피드백 시스템, 스마트 미러, 헬스케어 웨어러블 등 다양한 형태의 시각화 설계 시 중요한 디자인 원칙으로 활용될 수 있다.
마지막으로, 앞으로의 연구 과제로는 피드백의 정밀도 향상, 다중 사용자 협업 학습, 음성·진동 등 멀티모달 피드백 결합, 그리고 개인 맞춤형 교정 알고리즘 개발 등을 제시한다. 예를 들어, 사용자의 과거 학습 데이터를 기반으로 개인별 오류 패턴을 자동으로 분석하고, 해당 오류에 특화된 시각적 강조(예: 색상 변화, 라인 두께 조절)를 적용한다면 학습 효율을 더욱 극대화할 수 있을 것이다. 또한, 클라우드 기반 데이터베이스와 연동하여 전 세계 사용자들이 자신의 학습 기록을 공유하고, 전문가가 제공하는 자동화된 코멘트를 받아볼 수 있는 생태계 구축도 기대된다.
요약하면, 우리는 온라인 비디오와 웹캠을 동시에 활용한 인간 자세 추정 기반 웹 애플리케이션을 구현했으며, 사용자 자신의 실시간 영상 위에 자신의 골격을 겹쳐 보여 주는 시각적 피드백이 가장 큰 학습 효과를 가져온다는 실증적 증거를 제시하였다. 이 결과는 향후 디지털 피트니스·헬스케어 분야에서 보다 직관적이고 효과적인 가이드 시스템을 설계하는 데 중요한 토대가 될 것이며, 궁극적으로 온라인 동영상 학습의 한계를 극복하고, 누구나 손쉽게 정확한 신체 동작을 습득할 수 있는 환경을 만드는 데 기여할 것으로 기대한다.