A Generic Graph-based Neural Architecture Encoding Scheme for Predictor-based NAS
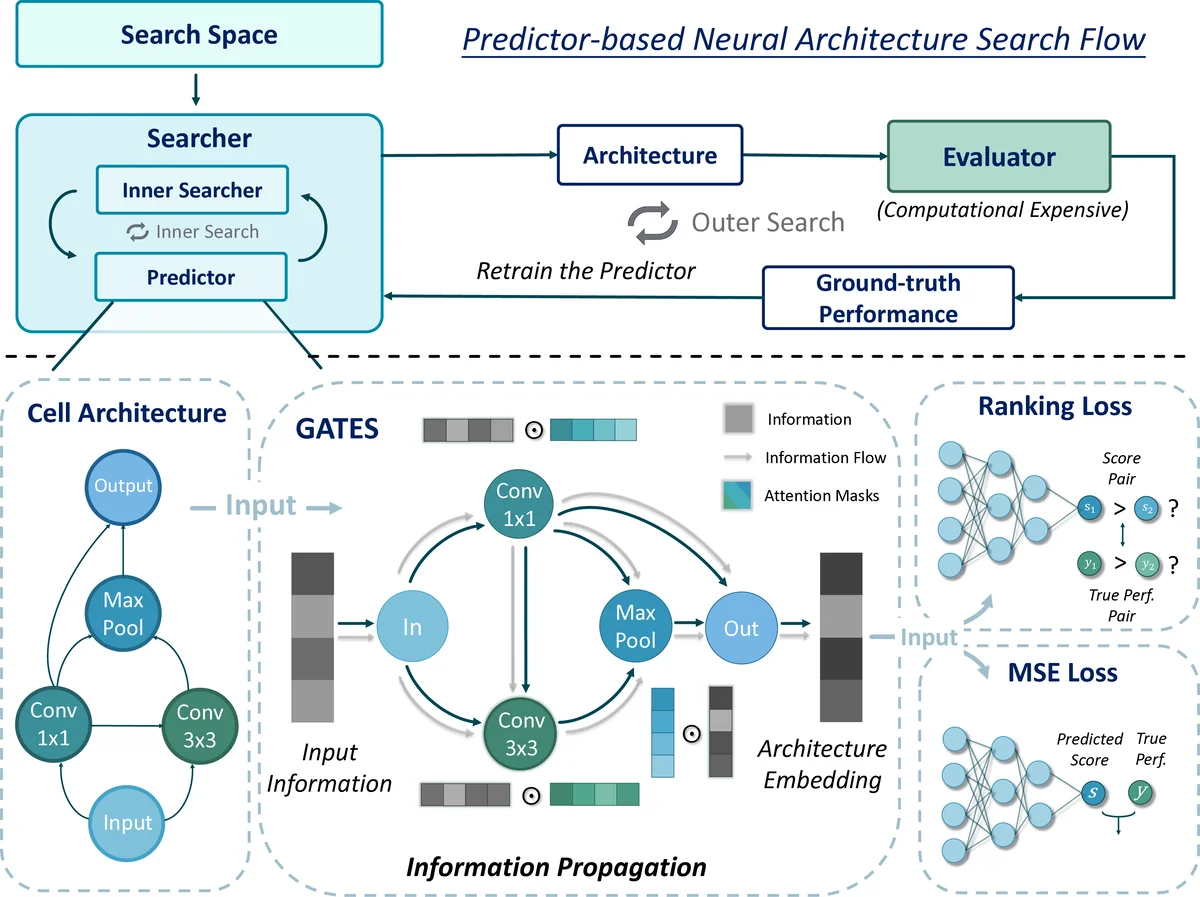
This work proposes a novel Graph-based neural ArchiTecture Encoding Scheme, a.k.a. GATES, to improve the predictor-based neural architecture search. Specifically, different from existing graph-based schemes, GATES models the operations as the transformation of the propagating information, which mimics the actual data processing of neural architecture. GATES is a more reasonable modeling of the neural architectures, and can encode architectures from both the “operation on node” and “operation on edge” cell search spaces consistently. Experimental results on various search spaces confirm GATES’s effectiveness in improving the performance predictor. Furthermore, equipped with the improved performance predictor, the sample efficiency of the predictor-based neural architecture search (NAS) flow is boosted. Codes are available at https://github.com/walkerning/aw_nas.
💡 Research Summary
This paper addresses a central bottleneck in predictor‑based Neural Architecture Search (NAS): the ability of the performance predictor to generalize from a limited set of evaluated architectures. Existing predictors rely on either sequence‑based encodings, which flatten a network architecture into a string and implicitly capture topology, or graph‑based encodings that apply Graph Convolutional Networks (GCNs) to the directed acyclic graph (DAG) of a cell. Both approaches have notable drawbacks. Sequence encoders lose explicit topological information, leading to weaker representations and difficulty handling isomorphic architectures. GCN‑based encoders treat operations (e.g., 3×3 convolution, max‑pool) as node attributes, which does not reflect the true data‑processing nature of a neural network where operations act as functions that transform feature maps. Moreover, for “operation‑on‑edge” (OOE) search spaces—where the primitive is attached to edges rather than nodes—GCNs cannot be directly applied, and prior ad‑hoc solutions (e.g., concatenating edge embeddings at a node) suffer from non‑commutativity and poor isomorphism handling.
The authors propose a new Graph‑based neural Architecture Encoding Scheme, abbreviated GATES, that models each operation as a transformation (or “soft gate”) applied to the information flowing through the graph. The encoding proceeds as follows: (1) Input nodes receive an initial information embedding E. (2) For each unary operation o (e.g., Conv3×3, MaxPool), a gate vector m = σ(EMB(o) W_o) is computed, where EMB(o) is a learned embedding of the operation, W_o maps operation embeddings to the information dimension, and σ denotes the sigmoid function. (3) The incoming information x_in at the node is multiplied element‑wise by m and then linearly transformed by W_x, yielding x_out = (m ⊙ x_in) W_x. (4) When multiple predecessor nodes feed into a node, their outgoing vectors are summed, mirroring the additive nature of feature‑map aggregation in real networks. (5) After propagating information in topological order through the entire DAG, the vector at the output node serves as the embedding of the cell. For multi‑cell architectures (e.g., normal and reduction cells in ENAS), each cell is encoded independently and concatenated.
Key innovations of GATES include:
- Operation‑as‑information‑transform – Unlike GCNs that treat operations as static node attributes, GATES explicitly models the functional effect of each operation on the flowing information, aligning the encoding with the actual computation graph of a CNN.
- Intrinsic isomorphism handling – Because the encoding follows the DAG’s topological order and uses only additive aggregation, any two isomorphic cells (i.e., differing only by node renaming or edge permutation) produce identical embeddings without requiring additional canonicalization or data augmentation.
- Unified treatment of OON and OOE spaces – The same propagation rules apply whether primitives reside on nodes (operation‑on‑node, OON) or edges (operation‑on‑edge, OOE), eliminating the need for separate encoders for each search space.
The authors integrate GATES into a standard predictor‑based NAS loop (Algorithm 1). A performance predictor P maps an architecture a to a predicted score ŝ via an MLP applied to the GATES embedding. The predictor is iteratively refined using a growing set of ground‑truth evaluations, while new candidate architectures are sampled according to the predictor’s current estimates.
Empirical evaluation spans three benchmark search spaces: NAS‑Bench‑101 (OON), NAS‑Bench‑201 (OOE), and ENAS (mixed). Across all settings, GATES‑based predictors achieve substantially higher ranking correlations (Kendall‑τ and Pearson‑R) than baselines using GCN, LSTM, or MLP encoders. For example, on NAS‑Bench‑101 with only 500 evaluated architectures, GATES attains a Kendall‑τ of ~0.78 versus ~0.62 for the best GCN baseline. The improved predictor translates into more sample‑efficient NAS: with the same evaluation budget, GATES‑driven searches discover top‑10 % architectures at a higher frequency, and the overall search cost is reduced by roughly 30‑40 % compared to a vanilla predictor‑based pipeline.
Ablation studies confirm that both components of the transformation (the operation‑gate m and the information‑transform W_x) contribute to performance; removing the gate reduces correlation by ~10 %. The authors also analyze isomorphism handling, showing that GATES maps permuted versions of the same cell to identical embeddings, whereas GCN‑based encoders produce divergent vectors.
Limitations are acknowledged. GATES currently encodes at the cell level; extending to full‑network representations (including depth, width scaling, and multi‑stage connections) may require hierarchical or recursive extensions. The linear‑plus‑sigmoid transformation may be insufficient for highly non‑linear primitives such as attention modules or dynamic routing, suggesting future work on richer, possibly multi‑layer, transformation functions. Additionally, while GATES eliminates the need for explicit parameter sharing, it still relies on sufficient training data to learn the operation embeddings and transformation matrices; extremely low‑budget regimes could benefit from meta‑learning initializations.
In conclusion, GATES offers a principled, graph‑centric encoding that aligns closely with the computational semantics of neural architectures. By treating operations as information‑transforming gates, it captures both topological and functional aspects, handles isomorphism naturally, and works uniformly across OON and OOE search spaces. The resulting performance predictor is markedly more accurate, leading to faster, more sample‑efficient NAS. The authors release their implementation (https://github.com/walkerning/aw_nas), facilitating adoption in future NAS research.
Comments & Academic Discussion
Loading comments...
Leave a Comment