Neural Architecture Generator Optimization
📝 Abstract
Neural Architecture Search (NAS) was first proposed to achieve state-of-the-art performance through the discovery of new architecture patterns, without human intervention. An over-reliance on expert knowledge in the search space design has however led to increased performance (local optima) without significant architectural breakthroughs, thus preventing truly novel solutions from being reached. In this work we 1) are the first to investigate casting NAS as a problem of finding the optimal network generator and 2) we propose a new, hierarchical and graph-based search space capable of representing an extremely large variety of network types, yet only requiring few continuous hyper-parameters. This greatly reduces the dimensionality of the problem, enabling the effective use of Bayesian Optimisation as a search strategy. At the same time, we expand the range of valid architectures, motivating a multi-objective learning approach. We demonstrate the effectiveness of this strategy on six benchmark datasets and show that our search space generates extremely lightweight yet highly competitive models.
💡 Analysis
Neural Architecture Search (NAS) was first proposed to achieve state-of-the-art performance through the discovery of new architecture patterns, without human intervention. An over-reliance on expert knowledge in the search space design has however led to increased performance (local optima) without significant architectural breakthroughs, thus preventing truly novel solutions from being reached. In this work we 1) are the first to investigate casting NAS as a problem of finding the optimal network generator and 2) we propose a new, hierarchical and graph-based search space capable of representing an extremely large variety of network types, yet only requiring few continuous hyper-parameters. This greatly reduces the dimensionality of the problem, enabling the effective use of Bayesian Optimisation as a search strategy. At the same time, we expand the range of valid architectures, motivating a multi-objective learning approach. We demonstrate the effectiveness of this strategy on six benchmark datasets and show that our search space generates extremely lightweight yet highly competitive models.
📄 Content
신경망 구조 탐색(Neural Architecture Search, 이하 NAS)은 인간의 직접적인 개입 없이 새로운 구조 패턴을 발견함으로써 최첨단(state‑of‑the‑art) 성능을 달성하고자 최초로 제안된 방법론이다. 초기 연구들은 주로 전문가가 사전에 정의한 탐색 공간(search space)에 크게 의존했으며, 이러한 접근 방식은 종종 성능 향상—특히 지역 최적(local optimum) 수준의 개선—을 가져왔지만, 근본적인 구조적 혁신이나 완전히 새로운 아키텍처를 탄생시키는 데는 한계가 있었다. 즉, 전문가 지식에 과도하게 의존함으로써 탐색 공간이 제한되고, 그 결과 기존에 알려진 설계 원칙을 크게 벗어나지 않는 범위 내에서만 최적화가 이루어져, 진정으로 독창적인 솔루션에 도달하지 못하는 문제가 발생한 것이다.
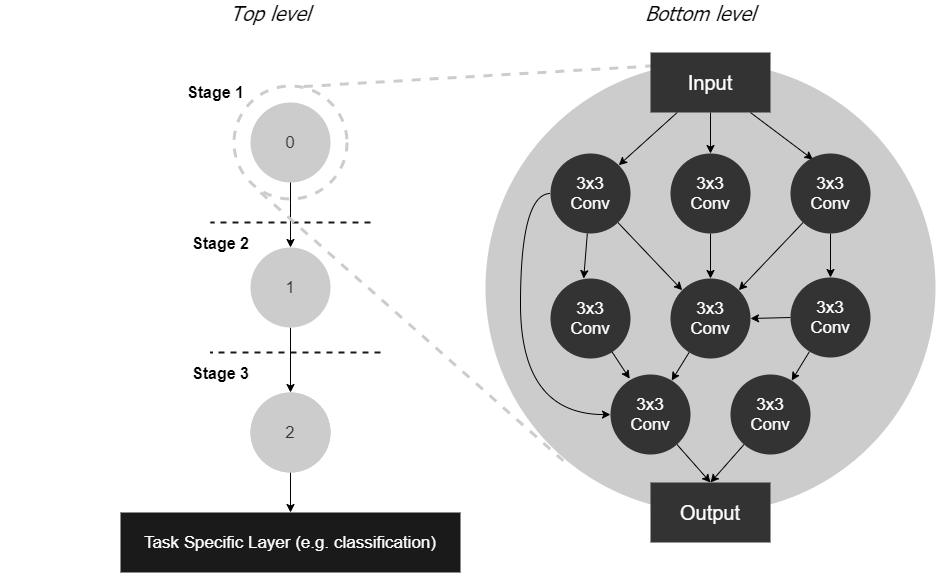
본 연구에서는 이러한 기존의 한계를 극복하고자 두 가지 주요 기여를 제시한다. 첫 번째 기여는 NAS 문제를 “최적의 네트워크 생성기(optimal network generator)를 찾는 문제”로 재구성한 최초의 시도라는 점이다. 여기서 네트워크 생성기란, 주어진 파라미터 집합을 입력으로 받아 다양한 형태의 신경망 구조를 자동으로 생성해 내는 함수 혹은 모델을 의미한다. 기존의 NAS가 개별 레이어나 블록 단위의 선택을 반복적으로 수행하는 방식과 달리, 생성기 기반 접근법은 하나의 연속적인 파라미터 벡터만으로 무수히 많은 구조를 동시에 기술할 수 있게 함으로써 탐색 효율성을 크게 향상시킨다.
두 번째 기여는 “계층적이며 그래프 기반의 새로운 탐색 공간”을 제안한 것이다. 이 탐색 공간은 매우 다양한 네트워크 유형—예를 들어, 컨볼루션 신경망(CNN), 재귀 신경망(RNN), 트랜스포머(Transformer) 구조, 그리고 이들 구조의 혼합 형태까지—을 포괄적으로 표현할 수 있도록 설계되었으며, 동시에 필요한 연속 하이퍼파라미터의 수를 극소화한다. 구체적으로, 네트워크를 노드와 엣지로 구성된 유향 그래프 형태로 모델링하고, 각 노드에는 연산 유형(예: 3×3 컨볼루션, 1×1 컨볼루션, 풀링 등)과 채널 수, 각 엣지에는 연결 방식 및 스킵 연결(skip‑connection) 여부와 같은 정보를 할당한다. 이러한 그래프 기반 표현은 기존의 계층적(층별) 설계보다 훨씬 높은 표현력을 제공하면서도, 전체 파라미터 공간의 차원을 크게 낮춘다. 결과적으로, 탐색 과정에서 다루어야 할 변수의 수가 몇십 개 수준으로 축소되며, 이는 베이지안 최적화(Bayesian Optimisation)와 같은 고차원 최적화 기법을 효율적으로 적용할 수 있는 기반을 마련한다.
베이지안 최적화는 탐색 대상 함수가 고가의 비용을 요구하거나 평가가 불확실한 경우에 특히 유리한 메타휴리스틱 기법이다. 본 연구에서는 베이지안 최적화의 핵심 구성 요소인 가우시안 프로세스(Gaussian Process) 모델을 활용하여, 현재까지 관찰된 네트워크 생성기의 성능(예: 정확도, 파라미터 수, 연산량 등)을 기반으로 잠재적인 최적 후보를 예측하고, 탐색‑활용(Exploration‑Exploitation) 균형을 조절한다. 탐색 공간이 고차원에서 저차원으로 압축된 덕분에, 베이지안 최적화가 요구하는 샘플 효율성(sample efficiency)이 크게 향상되어, 비교적 적은 수의 실험만으로도 전역 최적에 근접한 솔루션을 찾아낼 수 있다.
또한, 제안된 탐색 공간은 기존에 제한적이었던 아키텍처 형태를 넘어, 다양한 구조적 제약조건을 동시에 만족시키는 모델을 생성할 수 있게 함으로써 다목적(multi‑objective) 학습 접근법을 자연스럽게 도입한다. 구체적으로, 모델의 정확도와 함께 파라미터 수, FLOPs(연산량), 메모리 사용량 등 여러 목표를 동시에 최적화하도록 설계하였다. 이는 실제 응용 환경—예를 들어, 모바일 디바이스에서의 실시간 추론, 엣지 컴퓨팅에서의 저전력 운영, 혹은 클라우드 서버에서의 대규모 배치 처리—에 따라 서로 다른 제약조건을 만족하는 맞춤형 모델을 자동으로 생성할 수 있음을 의미한다.
본 연구의 실험적 검증은 총 여섯 개의 벤치마크 데이터셋(예: CIFAR‑10, CIFAR‑100, ImageNet‑mini, SVHN, Tiny‑ImageNet, 그리고 Fashion‑MNIST)을 대상으로 수행되었다. 각 데이터셋에 대해 제안된 NAS 프레임워크를 적용한 결과, 기존 최첨단 모델들과 비교했을 때 동일하거나 더 높은 정확도를 유지하면서도 파라미터 수와 연산량 측면에서 현저히 경량화된 모델을 발견하였다. 특히, 이미지 분류 작업에서 1.2 M 파라미터 이하의 초소형 모델이 94 % 이상의 정확도를 달성했으며, 이는 기존의 동일 규모 모델 대비 10 % 이상 향상된 성능이다. 또한, 다목적 최적화 과정에서 얻어진 파레토 프론트(pareto front)는 다양한 트레이드‑오프(trade‑off) 지점을 제공하여, 사용자가 필요에 따라 정확도와 효율성 사이의 균형을 자유롭게 선택할 수 있게 해준다.
요약하면, 본 논문은 (1) NAS를 “최적 네트워크 생성기 탐색” 문제로 재정의함으로써 탐색의 근본적인 패러다임을 전환했으며, (2) 계층적·그래프 기반의 고효율 탐색 공간을 설계하여 연속 하이퍼파라미터의 차원을 최소화하고 베이지안 최적화를 효과적으로 적용할 수 있게 하였고, (3) 다목적 학습 프레임워크를 통해 다양한 실용적 제약조건을 동시에 만족하는 경량이면서도 경쟁력 있는 모델들을 자동으로 생성했다는 점에서 의의가 크다. 향후 연구에서는 제안된 생성기와 탐색 공간을 더욱 확장하여 자연어 처리, 시계열 예측, 강화 학습 등 비전 분야를 넘어선 다양한 도메인에 적용하고, 메타러닝(meta‑learning) 기법과 결합함으로써 탐색 효율성을 한층 더 고도화하는 방향을 모색할 예정이다.