Predicting the outputs of finite deep neural networks trained with noisy gradients
💡 Research Summary
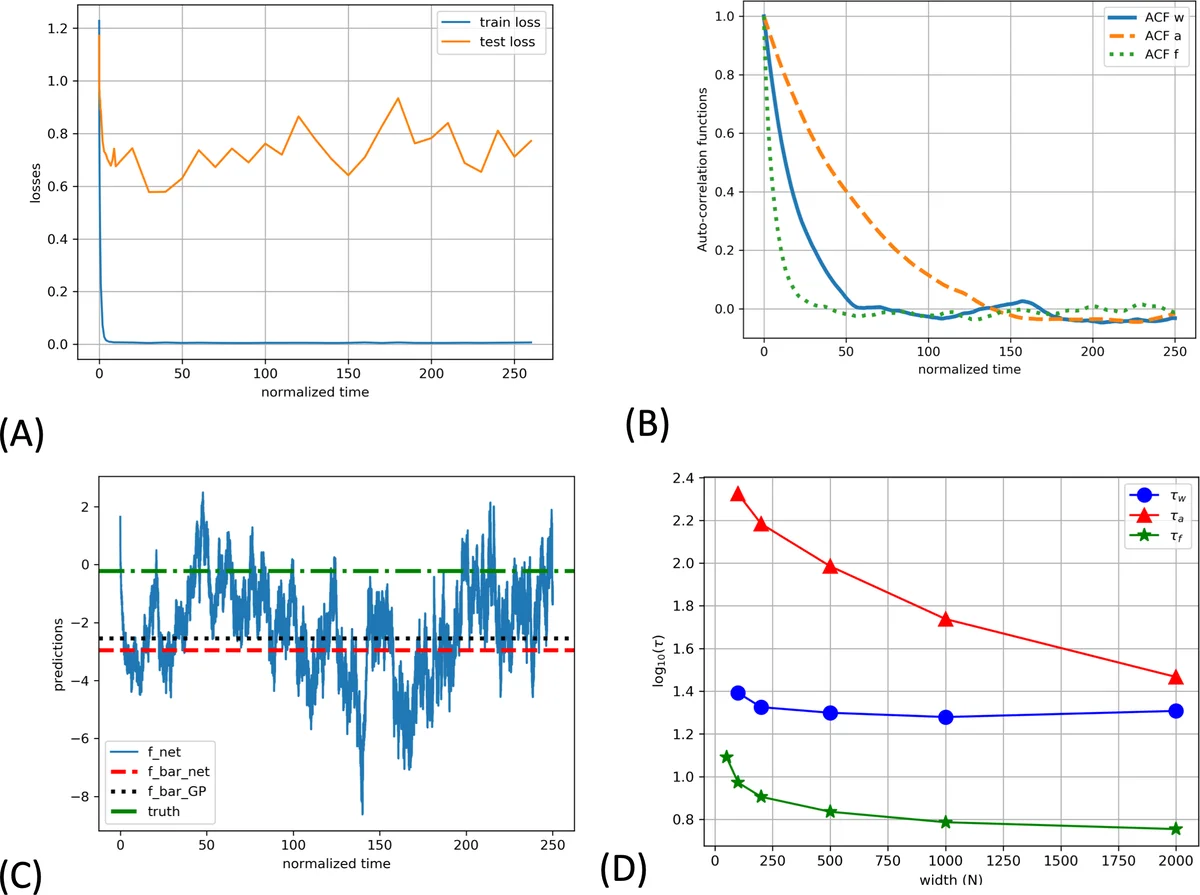
This paper addresses a gap in the theoretical understanding of deep neural networks (DNNs) trained with stochastic gradients. While recent works have shown that infinitely wide DNNs trained by gradient flow converge to Gaussian processes (GPs) – either the Neural Tangent Kernel (NTK) or the Neural Network Gaussian Process (NNGP) – these results either assume “lazy learning” (weights stay near initialization) or deterministic training, which do not reflect practical training regimes that involve weight decay, injected noise, and finite learning rates.
The authors propose a specific training protocol: full‑batch gradient descent with weight decay and additive white Gaussian noise (Langevin dynamics). In the limit of infinitesimal step size the dynamics become a continuous‑time Langevin equation whose stationary distribution is a Gibbs measure
(P(w)\propto\exp
Comments & Academic Discussion
Loading comments...
Leave a Comment