Deep Reinforcement Learning for Multi-Agent Systems: A Review of Challenges, Solutions and Applications
Reinforcement learning (RL) algorithms have been around for decades and employed to solve various sequential decision-making problems. These algorithms however have faced great challenges when dealing with high-dimensional environments. The recent development of deep learning has enabled RL methods to drive optimal policies for sophisticated and capable agents, which can perform efficiently in these challenging environments. This paper addresses an important aspect of deep RL related to situations that require multiple agents to communicate and cooperate to solve complex tasks. A survey of different approaches to problems related to multi-agent deep RL (MADRL) is presented, including non-stationarity, partial observability, continuous state and action spaces, multi-agent training schemes, multi-agent transfer learning. The merits and demerits of the reviewed methods will be analyzed and discussed, with their corresponding applications explored. It is envisaged that this review provides insights about various MADRL methods and can lead to future development of more robust and highly useful multi-agent learning methods for solving real-world problems.
💡 Research Summary
**
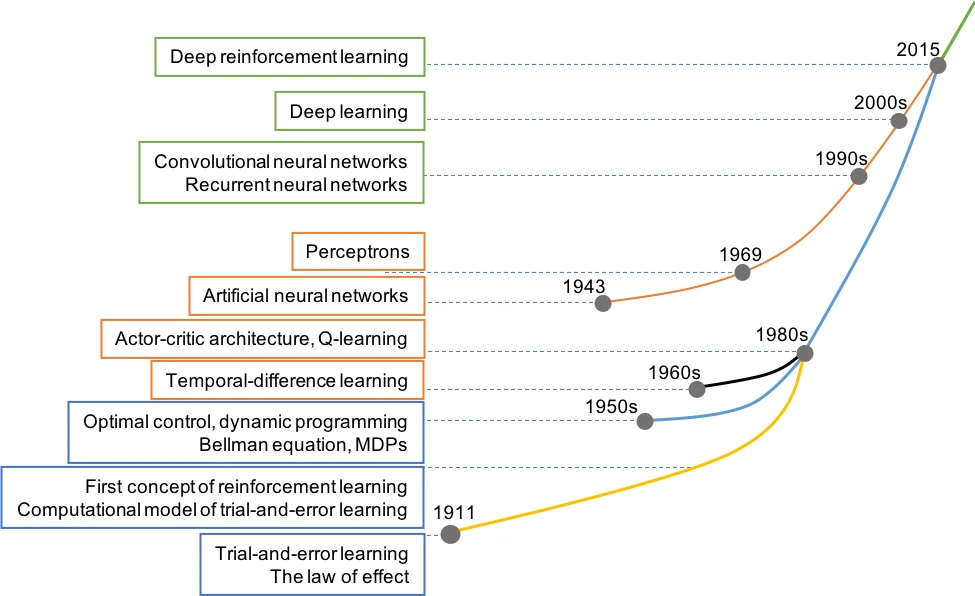
The paper provides a comprehensive survey of Multi‑Agent Deep Reinforcement Learning (MADRL), focusing on the technical challenges that arise when extending deep reinforcement learning (DRL) from single‑agent to multi‑agent settings, the families of solutions that have been proposed, and a wide range of real‑world applications. After a brief historical overview of reinforcement learning—from early trial‑and‑error experiments to the breakthrough of Deep Q‑Networks (DQN) and subsequent successes such as AlphaGo, OpenAI Five, and autonomous driving—the authors argue that many complex problems (e.g., cooperative robotics, traffic control, multi‑player games) cannot be solved by a single deep RL agent and therefore require coordinated multi‑agent systems.
The core of the survey is organized around five fundamental challenges:
-
Non‑Stationarity – In a multi‑agent environment each learner’s policy changes over time, breaking the stationary Markov assumption. The paper reviews independent Q‑learning, centralized training with decentralized execution (CTDE), and meta‑learning approaches that adapt to the evolving dynamics.
-
Partial Observability – Agents often lack full access to the global state. Solutions include recurrent neural networks (RNN/LSTM), graph neural networks (GNN) for relational reasoning, and Bayesian filtering techniques that estimate hidden state information.
-
Continuous State and Action Spaces – For robotics and control tasks, discrete methods are insufficient. The authors discuss policy‑gradient algorithms such as DDPG, TD3, and Soft Actor‑Critic (SAC) and how they are extended to multi‑agent contexts through shared action spaces, joint sampling, and coordinated exploration.
-
Training Schemes – Various cooperation/competition paradigms are examined: joint training, competitive learning, and exchange learning. The survey highlights Actor‑Critic architectures that combine a shared critic with individual actors, experience replay buffers with prioritized sampling, and curriculum learning to improve sample efficiency.
-
Transfer Learning – Re‑using knowledge across tasks or agents is crucial for scalability. The paper surveys domain adaptation, parameter sharing, multi‑task learning, and meta‑RL techniques that enable rapid policy transfer to new environments.
For each category, the authors present tables summarizing representative algorithms, their advantages (e.g., stability, sample efficiency, coordination) and drawbacks (e.g., computational overhead, communication cost, scalability limits). The discussion then moves to concrete applications:
- Cooperative Robotics – Multi‑robot manipulation, swarm UAV navigation, and collaborative assembly lines demonstrate how MADRL can achieve coordinated motion planning and fault tolerance.
- Smart Transportation – Vehicle‑to‑vehicle cooperation for lane‑changing, traffic‑signal optimization, and congestion mitigation illustrate the impact on traffic flow and safety.
- Multi‑Player Games – Complex strategy games such as Dota 2 and StarCraft II showcase competitive and cooperative dynamics, where agents learn both team strategies and opponent modeling.
These case studies also expose practical issues such as real‑time communication constraints, safety verification, and the need for robust policy generalization.
In the final section, the authors outline future research directions: (i) scalable distributed learning frameworks and lightweight communication protocols to handle large‑scale agent populations; (ii) formal verification and safety‑critical RL to guarantee reliable behavior; (iii) human‑agent interaction models that incorporate trust and interpretability; and (iv) meta‑learning and self‑supervised approaches for better generalization across multimodal, multi‑task environments.
Overall, the review serves as a detailed map of the current MADRL landscape, offering both a critical assessment of existing methods and a forward‑looking agenda for researchers and practitioners aiming to deploy multi‑agent deep reinforcement learning in real‑world systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment