Enabling Efficient and Flexible FPGA Virtualization for Deep Learning in the Cloud
💡 Research Summary
The paper addresses the growing demand for deep neural network (DNN) inference in cloud data centers, where FPGA accelerators are attractive for their energy efficiency and performance. Existing FPGA‑based DNN solutions in the cloud typically rely on time‑division multiplexing (TDM) to share a single FPGA among multiple users. While TDM avoids frequent re‑programming, it cannot guarantee physical resource isolation, leading to security concerns and performance interference. Space‑division multiplexing (SDM) can provide isolation by allocating distinct hardware regions to each user, but traditional SDM approaches suffer from heavy re‑configuration overheads (often 100 s of seconds) because they require recompiling large portions of the accelerator for each new resource allocation.
To overcome these limitations, the authors propose a comprehensive virtualization framework that operates on a single FPGA and targets both public‑cloud (emphasizing isolation) and private‑cloud (emphasizing flexibility) scenarios. The framework consists of two main innovations:
-
Multi‑core Hardware Resource Pool (HRP) with Two‑Level Instruction Dispatch
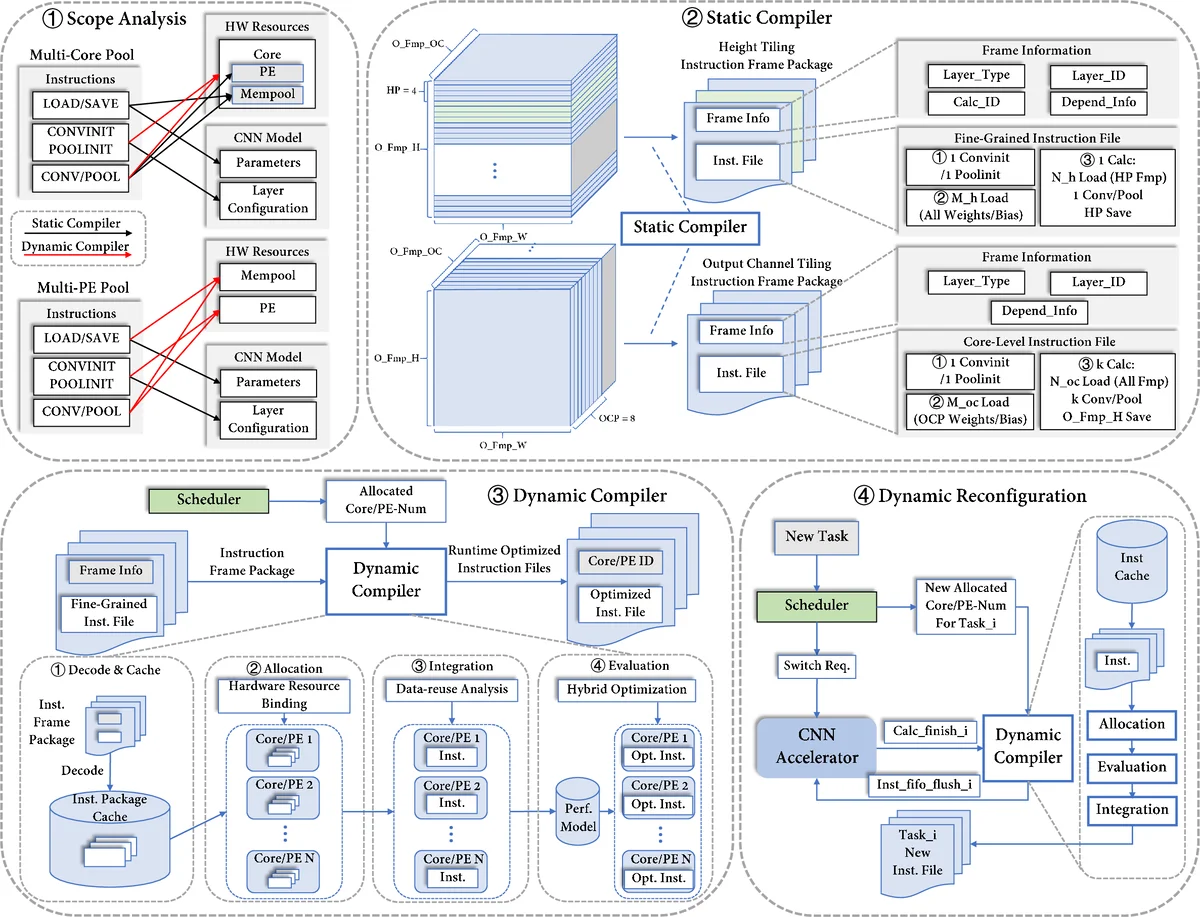
- The large monolithic compute core of a typical ISA‑based CNN accelerator is partitioned into many small cores.
- A two‑level dispatch module first assigns a set of small cores to each user (ensuring physical isolation) and then schedules individual tasks within those cores.
- This SDM‑based design eliminates cross‑user crashes and malicious interference, achieving performance isolation with less than 1 % deviation among concurrent users.
- To keep the performance of the multi‑core configuration comparable to a single large core, the authors introduce a tiling‑based instruction package. Output feature maps are partitioned into tiles that are balanced across the allocated cores, and a latency simulator predicts workload distribution to minimize inter‑core communication and synchronization overhead.
-
Two‑Stage Static‑Dynamic Compilation Flow
- In the offline (static) stage, the compiler generates fine‑grained instruction packages for all feasible hardware configurations (different numbers of DSPs, memory bandwidth, etc.).
- During online operation (dynamic stage), only the lightweight runtime information—essentially which pre‑generated packages to combine—is re‑compiled. This reduces the online re‑configuration latency to approximately 1 ms, a dramatic improvement over the 100‑1000 s required by prior ISA‑based designs.
- The dynamic compiler also handles resource re‑allocation in response to changing workloads in private‑cloud settings, enabling rapid scaling without disrupting ongoing inference tasks.
The authors evaluate their design using an Angel‑Eye‑based accelerator as a reference implementation. Experiments cover both public‑cloud (multiple users with static workloads) and private‑cloud (dynamic workload changes) scenarios. Key results include:
- Throughput Gains: Compared with a static single‑core TDM design, the proposed SDM multi‑core system achieves 1.07‑1.69× higher throughput. Against a static multi‑core baseline, it delivers 1.88‑3.12× improvement.
- Isolation: Physical resource isolation is guaranteed by the HRP, and performance isolation is demonstrated with less than 1 % throughput variance among users.
- Re‑configuration Overhead: The two‑stage compilation reduces online re‑configuration time to ~1 ms, enabling millisecond‑scale latency requirements for inference services.
- Resource Utilization: By balancing tiles and minimizing inter‑core traffic, the multi‑core design attains utilization rates comparable to a single large core, despite being composed of many smaller cores.
The paper concludes that effective FPGA virtualization for deep learning in the cloud can be achieved by combining SDM‑based hardware partitioning with a lightweight static‑dynamic compilation strategy. This approach delivers both the security and performance isolation needed for public‑cloud multi‑tenant environments and the rapid adaptability required for private‑cloud dynamic workloads. Future work is suggested to extend the framework to multi‑node FPGA clusters and to automate the generation of optimal tiling and instruction packages for a broader range of DNN models.
Comments & Academic Discussion
Loading comments...
Leave a Comment