Zero-shot Learning for Audio-based Music Classification and Tagging
Audio-based music classification and tagging is typically based on categorical supervised learning with a fixed set of labels. This intrinsically cannot handle unseen labels such as newly added music genres or semantic words that users arbitrarily choose for music retrieval. Zero-shot learning can address this problem by leveraging an additional semantic space of labels where side information about the labels is used to unveil the relationship between each other. In this work, we investigate the zero-shot learning in the music domain and organize two different setups of side information. One is using human-labeled attribute information based on Free Music Archive and OpenMIC-2018 datasets. The other is using general word semantic information based on Million Song Dataset and Last.fm tag annotations. Considering a music track is usually multi-labeled in music classification and tagging datasets, we also propose a data split scheme and associated evaluation settings for the multi-label zero-shot learning. Finally, we report experimental results and discuss the effectiveness and new possibilities of zero-shot learning in the music domain.
💡 Research Summary
The paper addresses a fundamental limitation of current audio‑based music classification and tagging systems: they are trained on a fixed set of categorical labels and therefore cannot handle newly introduced genres, user‑defined semantic tags, or any label that was not present during training. To overcome this, the authors explore zero‑shot learning (ZSL) for music, a paradigm that leverages an auxiliary semantic space of labels so that relationships among seen and unseen labels can be inferred at test time.
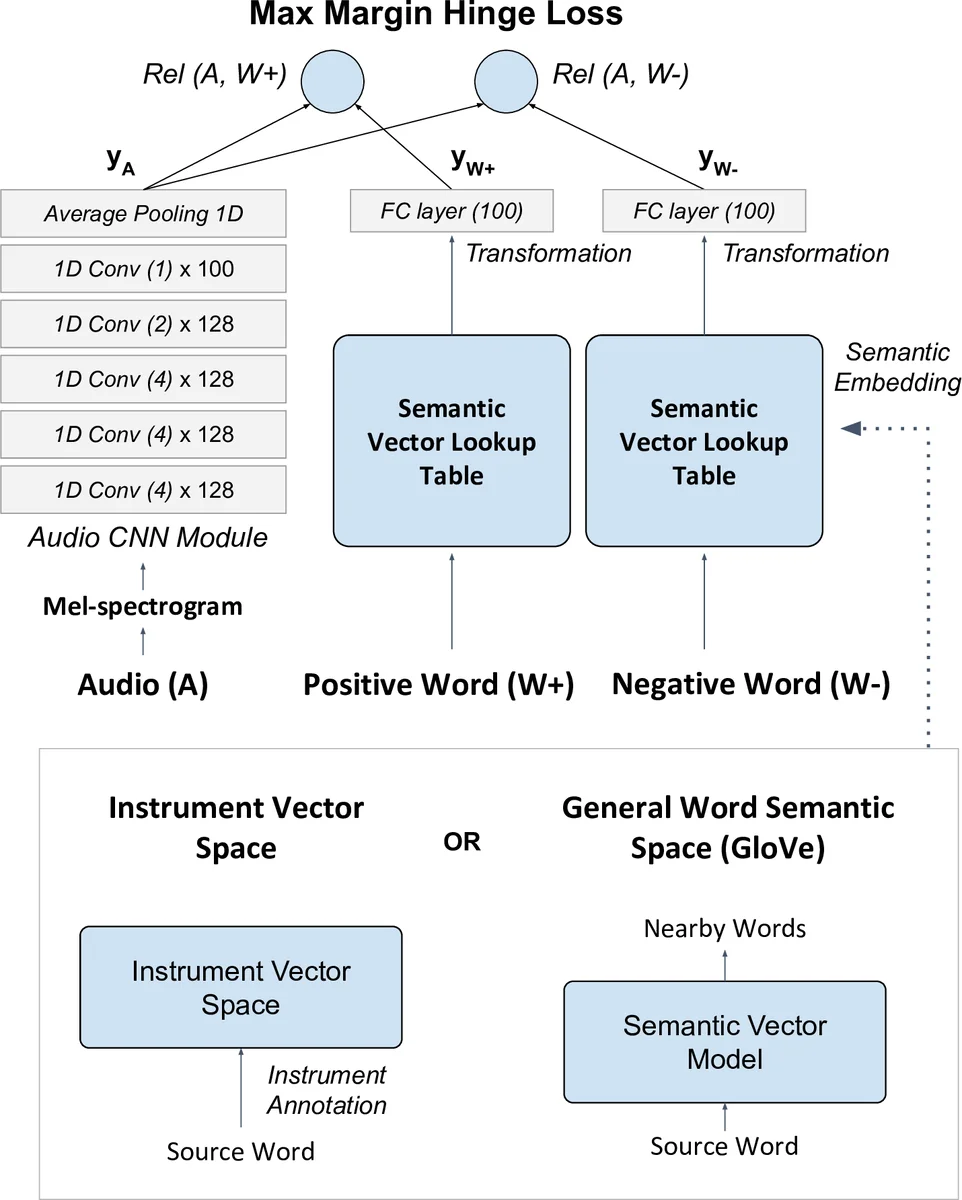
Two distinct sources of side information are investigated. The first uses human‑annotated attribute data: instrument presence/absence vectors derived from the OpenMIC‑2018 dataset are aggregated per genre in the Free Music Archive (FMA) to create a 40‑dimensional attribute vector (positive and negative instrument likelihoods). This attribute space is highly interpretable and directly ties musical content (instruments) to genre semantics. The second source employs general word embeddings (e.g., GloVe) learned from large text corpora, applied to tag vocabularies extracted from the Million Song Dataset (MSD) and Last.fm annotations. Word embeddings provide a broad vocabulary and can represent arbitrary user‑generated tags, but they may miss music‑specific nuances.
A major contribution is a systematic data‑split scheme tailored for multi‑label ZSL, which the authors argue has been under‑explored. After dividing the full label set into seen (X) and unseen (Y) groups, they further partition the track instances into three subsets: A (only seen labels), B (both seen and unseen), and C (only unseen). This enables the construction of multiple training and testing configurations: (i) traditional ZSL (train on A‑X, test on (B+C)‑Y), (ii) label‑first split (train on A‑X, test on (B+C)‑Y), and (iii) generalized ZSL where both seen and unseen labels are evaluated together (e.g., test on (B+C)‑(X+Y)). Such a scheme captures realistic scenarios where new tags are added to an existing corpus and where some tracks already contain a mixture of old and new annotations.
The core model is a deep embedding network that learns a non‑linear compatibility function between audio and semantic embeddings. Audio is represented by 3‑second mel‑spectrogram excerpts processed through four 1‑D convolutional layers (with ReLU and max‑pooling), followed by an additional convolution and average pooling to produce a fixed‑size audio embedding. The semantic branch consists of a lookup table (either instrument attribute vectors or word embeddings) projected through a fully‑connected layer to the same dimensionality. Compatibility is measured by cosine similarity, and training uses a max‑margin hinge loss that pushes the similarity of a positive label higher than that of a randomly sampled negative label by a margin Δ. This formulation mirrors successful image‑text ZSL approaches but is adapted to raw audio input, avoiding reliance on pre‑trained audio embeddings.
For comparison, a conventional multi‑label classification model is built by attaching a sigmoid‑activated output layer (size = number of seen labels) on top of the same audio CNN and training with binary cross‑entropy. This baseline helps assess whether the joint embedding approach sacrifices any performance on the seen‑label task.
Experiments are conducted on two public datasets. In the “genre‑with‑instrument attributes” setting, 157 genre labels from FMA are split into 125 seen and 32 unseen; 20 instrument annotations from OpenMIC‑2018 are transformed into 40‑dimensional vectors and aggregated per genre. In the “MSD‑Last.fm” setting, 1,126 tags are divided into 900 seen and 226 unseen, and GloVe vectors (100‑dimensional) serve as semantic embeddings. Training uses standard stochastic gradient descent with Nesterov momentum, a learning rate of 0.001, and early stopping on a 10 % validation split. Evaluation metrics include mean average precision (mAP) and precision at k (P@1, P@5, P@10) for the annotation task, and retrieval‑oriented similarity scores for the search task.
Results show that the zero‑shot models achieve non‑trivial performance on unseen labels, with the attribute‑based variant generally outperforming the word‑embedding variant on precision‑at‑k metrics. This suggests that domain‑specific attributes provide stronger semantic grounding for music than generic textual embeddings. Moreover, the proposed multi‑label split scheme reveals nuanced behavior: models trained on B‑X (instances containing both seen and unseen annotations) tend to perform better on unseen label prediction than those trained solely on A‑X, highlighting the benefit of exposing the network to mixed‑label examples during training. In generalized ZSL evaluations (testing on both seen and unseen labels), performance degrades modestly but remains competitive, indicating that the learned embedding space can accommodate a broader label universe.
The authors acknowledge several limitations. The instrument attribute space is limited to 20 instruments, which may not capture the full diversity of musical timbres across genres. General word embeddings, while extensive, sometimes fail to encode music‑specific concepts (e.g., niche sub‑genres). The 3‑second audio excerpt may omit long‑range structural cues important for genre discrimination. Future work is suggested to incorporate richer music‑theoretic attributes (rhythm, harmony, timbre descriptors), multi‑scale audio representations, and transformer‑based cross‑modal attention mechanisms to better align audio and semantic spaces.
In summary, the paper makes three key contributions to the MIR community: (1) it demonstrates that zero‑shot learning can be effectively applied to audio‑based music classification and tagging, enabling prediction of previously unseen labels; (2) it proposes a comprehensive multi‑label data‑split and evaluation framework that captures realistic scenarios of label evolution; and (3) it introduces a deep non‑linear compatibility model that jointly learns audio and semantic embeddings from raw mel‑spectrograms. These advances open the door to more flexible, user‑driven music retrieval systems that can adapt to evolving vocabularies without retraining from scratch.
Comments & Academic Discussion
Loading comments...
Leave a Comment