Using context to adapt to sensor drift
💡 Research Summary
The paper addresses the pervasive problem of sensor drift in metal‑oxide gas‑sensor arrays, a phenomenon where the response characteristics of inexpensive industrial odor‑sensing devices change over time due to aging, contamination, temperature, humidity, and background chemicals. Traditional mitigation relies on periodic manual recalibration, which is costly, labor‑intensive, and disruptive to production. Inspired by the adaptive capabilities of biological olfactory systems—where higher‑order brain regions provide feedback to the olfactory bulb to compensate for environmental and physiological changes—the authors propose a machine‑learning architecture that treats drift as a contextual variable that can be learned and predicted.
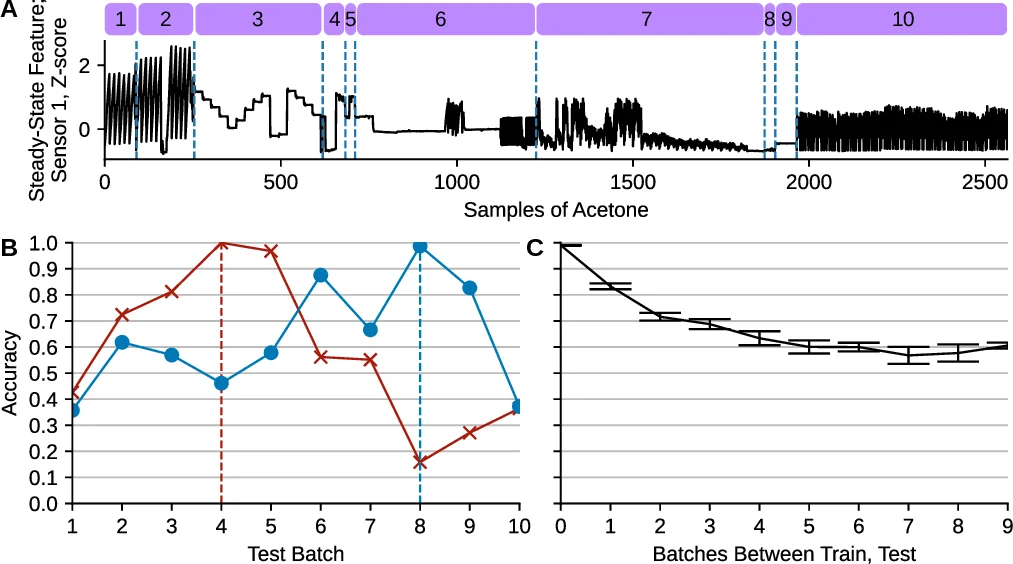
The authors build on a publicly available benchmark dataset (Vergara et al., 2017) that spans 36 months, comprising ten sequential “batches” of data. Each batch contains 161–3,600 samples, each represented by a 128‑dimensional feature vector derived from 16 metal‑oxide sensors (raw, normalized, and exponential moving‑average features). Six gases (ammonia, acetaldehyde, acetone, ethylene, ethanol, toluene) are present, with variable concentrations and inter‑batch chemical interferents, providing a realistic testbed for drift mitigation. The toluene class is removed due to missing samples in several batches, and all features are standardized to zero mean and unit variance.
Four modeling approaches are evaluated:
-
SVM Ensemble (baseline) – Replicates the method of Vergara et al. Each batch trains a one‑vs‑one RBF‑kernel SVM. For a target batch T, an ensemble of models trained on batches 1…T‑1 is weighted by their accuracy on batch T‑1 (βi) and combined via weighted voting. Hyperparameters C and γ are tuned by 10‑fold cross‑validation over exponential grids.
-
Skill Neural Network (NN) – A feed‑forward network that ignores temporal structure. Input (128‑D) → 50‑unit “skill” hidden layer → 20‑unit “decision” hidden layer → 5‑unit output (class scores). Trained with cross‑entropy loss, SGD with momentum (lr = 1e‑3, momentum = 0.9), weight decay = 1e‑2, for 200 epochs. Weights are initialized with a Gaussian distribution scaled by layer size. Implemented in PyTorch.
-
NN Ensemble – Mirrors the SVM ensemble: ten skill networks each trained on a single batch, weighted by their accuracy on the preceding batch, and combined by weighted sum of logits.
-
Context + Skill NN – The novel contribution. In addition to the skill pathway, a recurrent context pathway processes a short sequence of labeled samples from previous batches. For each training sample from batch p, a context sequence is sampled uniformly from any start batch s ∈ {1,…,p‑1} and ends at batch p‑1. The context RNN (simple RNN; LSTM tested but not beneficial due to short sequences) produces a context vector that is concatenated with the skill hidden representation before the final decision layer. The recurrent weights are learned via back‑propagation through time, allowing the network to encode drift patterns as temporal context. At test time on batch T, the context is built from all prior batches (1…T‑1).
Experimental protocol: For each target batch T, models are trained on batches 1…T‑1 and evaluated on batch T. Performance is measured by classification accuracy across the five remaining gas classes (toluene excluded). Results show:
- The skill NN outperforms the SVM ensemble by 3–5 % absolute accuracy on average, confirming the superiority of modern deep models for this high‑dimensional sensor data.
- The context + skill NN yields additional gains, especially when the temporal gap between training and test batches is large. Accuracy degradation that plummets in the SVM baseline as the distance grows is markedly attenuated; the context model effectively predicts the drift trajectory.
- The NN ensemble improves over a single skill NN but still lags behind the context‑enhanced model, indicating that explicit temporal modeling is more effective than simple model averaging.
- LSTM variants did not provide statistically significant improvements (p ≥ 0.05) over the simple RNN, likely because context sequences contain at most nine steps, limiting the need for sophisticated gating.
The paper’s contributions are twofold. First, it demonstrates that treating sensor drift as a learnable context, rather than a static nuisance, enables continual adaptation without manual recalibration. Second, it draws a concrete parallel between biological olfaction—where higher cortical feedback modulates early sensory processing—and engineered systems, showing that a modest recurrent module can capture drift dynamics and improve long‑term robustness. The authors suggest future extensions such as incorporating attention mechanisms into the context pathway, adding multimodal environmental variables (temperature, humidity), or exploring meta‑learning approaches for even faster adaptation.
In summary, “context + skill” learning provides a practical, scalable solution for industrial odor‑sensing applications, reducing downtime and maintenance costs while maintaining high classification performance over extended periods of sensor degradation.
Comments & Academic Discussion
Loading comments...
Leave a Comment