Learning Cross-Modal Embeddings with Adversarial Networks for Cooking Recipes and Food Images
Food computing is playing an increasingly important role in human daily life, and has found tremendous applications in guiding human behavior towards smart food consumption and healthy lifestyle. An important task under the food-computing umbrella is retrieval, which is particularly helpful for health related applications, where we are interested in retrieving important information about food (e.g., ingredients, nutrition, etc.). In this paper, we investigate an open research task of cross-modal retrieval between cooking recipes and food images, and propose a novel framework Adversarial Cross-Modal Embedding (ACME) to resolve the cross-modal retrieval task in food domains. Specifically, the goal is to learn a common embedding feature space between the two modalities, in which our approach consists of several novel ideas: (i) learning by using a new triplet loss scheme together with an effective sampling strategy, (ii) imposing modality alignment using an adversarial learning strategy, and (iii) imposing cross-modal translation consistency such that the embedding of one modality is able to recover some important information of corresponding instances in the other modality. ACME achieves the state-of-the-art performance on the benchmark Recipe1M dataset, validating the efficacy of the proposed technique.
💡 Research Summary
The paper tackles the problem of cross‑modal retrieval between cooking recipes and food images, a task that underpins many health‑related applications such as nutrition estimation and dietary recommendation. Existing approaches typically encode images with a CNN and recipes with an LSTM, then align the two modalities using a simple pairwise cosine loss or a vanilla triplet loss. The authors identify three major shortcomings of these methods: (1) naive sampling in triplet loss ignores the high intra‑class variance of images belonging to the same recipe, leading to slow convergence; (2) the feature distributions of the two modalities are fundamentally different and are never explicitly aligned; (3) the embedding process may discard important semantic information, making it unclear whether the learned vectors retain cross‑modal meaning.
To address these issues, the authors propose ACME (Adversarial Cross‑Modal Embedding), an end‑to‑end framework that integrates three novel components:
-
Hard‑sample‑mined Triplet Loss – For each anchor (either an image or a recipe embedding), the most distant positive sample and the closest negative sample are selected during training. This hard mining focuses the optimizer on the most informative examples, improving convergence speed and retrieval accuracy, especially when many images correspond to a single recipe.
-
Adversarial Modality Alignment – The penultimate features from the image encoder (Vₘ) and the recipe encoder (Rₘ) are fed to a discriminator Dₘ trained with the Wasserstein GAN with Gradient Penalty (WGAN‑GP). The encoders are optimized to make Dₘ unable to distinguish the source modality, thereby forcing the two feature distributions to become indistinguishable. This alignment reduces the “media gap” and yields a more robust shared latent space.
-
Cross‑Modal Translation Consistency – Two auxiliary tasks enforce that the learned embeddings preserve information across modalities. (a) Recipe‑to‑Image: the recipe embedding R is used as input to a generative network that synthesizes a food image; the generator is trained with an adversarial loss against a real‑image discriminator. (b) Image‑to‑Recipe: the image embedding V is passed through a multi‑label classifier that predicts the set of ingredients associated with the recipe. Both tasks are jointly optimized with the main retrieval loss, encouraging the embeddings to be semantically rich and invertible.
The overall loss is a weighted sum:
L = L_Ret + λ₁ L_MA + λ₂ L_Trans,
where L_Ret is the hard‑sample triplet loss, L_MA is the adversarial alignment loss, and L_Trans = L_r2i + L_i2r combines the two translation objectives.
Architecturally, images are processed by a CNN (e.g., ResNet) to obtain Vₘ, while recipes are tokenized, embedded, and fed to an LSTM to produce Rₘ. Both Vₘ and Rₘ pass through a shared fully‑connected layer (weight sharing) to produce the final d‑dimensional embeddings V and R used for retrieval. The shared layer encourages a common representation while keeping the parameter count modest.
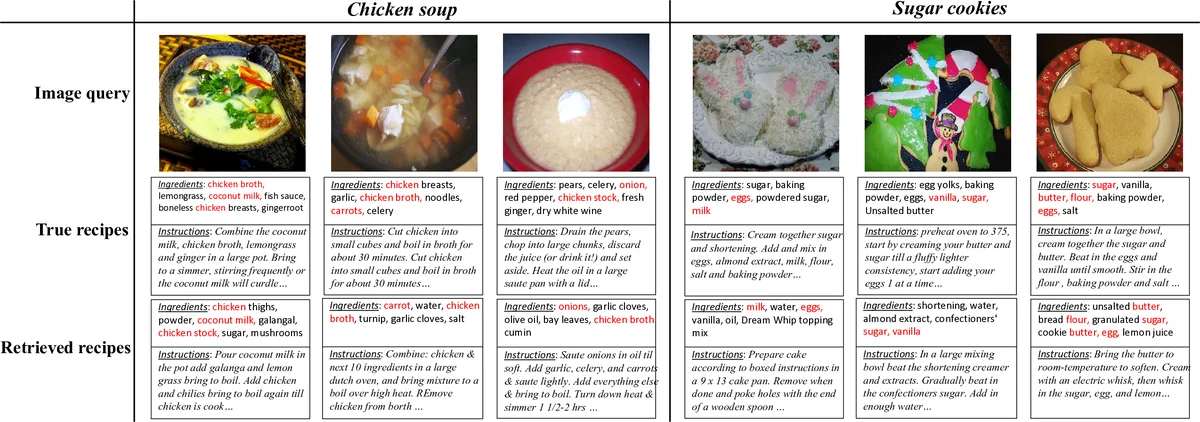
Experiments are conducted on the large‑scale Recipe1M dataset, evaluating both image‑to‑recipe and recipe‑to‑image retrieval with Recall@1, @5, and @10. ACME consistently outperforms prior state‑of‑the‑art methods such as JE, AdaMine, and hierarchical attention models, achieving improvements of 3–5 absolute percentage points across metrics. Ablation studies demonstrate that removing any of the three components degrades performance: hard‑sample mining contributes the largest gain, adversarial alignment adds 2–3 % points, and translation consistency provides an additional 1–2 % boost. Qualitative results show that generated images resemble the true dishes in color and layout, and ingredient predictions from image embeddings achieve high precision, confirming that the embeddings retain cross‑modal semantics.
Strengths of ACME include a principled handling of distribution mismatch via adversarial training, a robust hard‑mining triplet formulation that scales to large, noisy datasets, and the novel translation consistency losses that enforce invertibility of the latent space. Limitations involve the relatively low resolution of generated images (the generator is not the focus of the paper) and the reliance on an LSTM for recipe encoding, which may not capture long‑range dependencies as effectively as modern Transformers.
Future directions suggested by the authors involve replacing the LSTM with a Transformer‑based encoder, employing high‑resolution GANs (e.g., StyleGAN) for better image synthesis, and extending the framework to downstream tasks such as calorie estimation or personalized dietary recommendation.
In summary, ACME presents a comprehensive solution to cross‑modal food retrieval by jointly optimizing hard‑sample triplet learning, adversarial distribution alignment, and cross‑modal translation consistency, achieving state‑of‑the‑art performance on a benchmark dataset and opening avenues for richer multimodal food understanding.
Comments & Academic Discussion
Loading comments...
Leave a Comment