COMPLEX-IT: A Case-Based Modeling and Scenario Simulation Platform for Social Inquiry
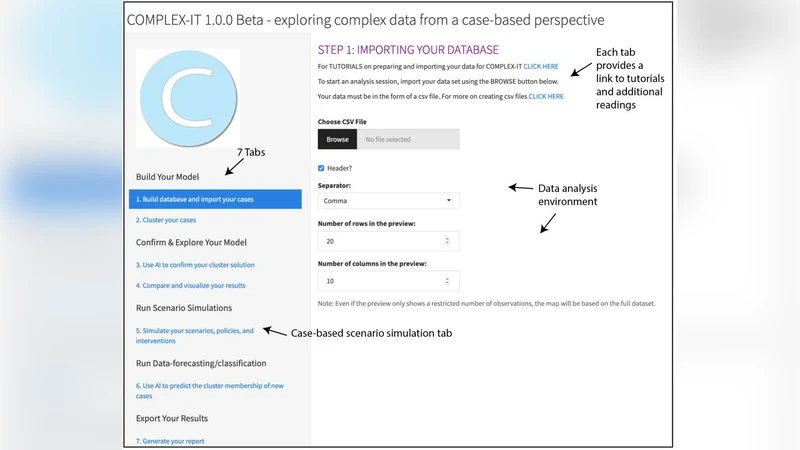
COMPLEX-IT is a case-based, mixed-methods platform for social inquiry into complex data/systems, designed to increase non-expert access to the tools of computational social science (i.e., cluster analysis, artificial intelligence, data visualization, data forecasting, and scenario simulation). In particular, COMPLEX-IT aids social inquiry though a heavy emphasis on learning about the complex data/system under study, which it does by (a) identifying and forecasting major and minor clusters/trends; (b) visualizing their complex causality; and (c) simulating scenarios for potential interventions. COMPLEX-IT is accessible through the web or can be run locally and is powered by R and the Shiny web framework.
💡 Research Summary
The paper presents COMPLEX IT, a case‑based mixed‑methods platform designed to make advanced computational social‑science tools accessible to non‑expert users. Built with R and the Shiny web framework, the system can be run as a hosted web service or installed locally. Its core philosophy follows “case‑based complexity” (CBC), which treats each observation as a holistic case whose temporal and spatial trajectory, inter‑dependent variables, hierarchical context, and emergent network‑like properties are the primary units of analysis.
The workflow begins with a data‑upload tab where users provide a CSV file containing only numeric variables; rows represent cases and columns represent profile components. Users can subset variables before analysis. The next tab runs k‑means clustering, allowing the analyst to choose the number of clusters and to evaluate cluster quality using pseudo‑F and silhouette plots. This step is deliberately user‑driven, encouraging domain expertise to guide the selection and interpretation of major and minor trends.
A subsequent Self‑Organizing Map (SOM) tab implements an unsupervised neural‑network clustering algorithm that projects high‑dimensional case profiles onto a two‑dimensional grid of neurons. After training, the platform automatically runs ANOVA to highlight variables that differ significantly across neurons, and it reports quantization and topographic errors as additional quality metrics. The SOM output is visualized as a topographic map, enabling users— even those with limited machine‑learning background—to compare SOM clusters with the earlier k‑means results.
The most innovative component is the Case‑Based Scenario Simulation (CBSS) tab. Unlike traditional agent‑based models that simulate individual agents, CBSS focuses on the mesoscale of identified clusters or trends. Users specify hypothetical interventions or external shocks (e.g., policy changes, economic events) and adjust the causal profile of a target cluster. The system then re‑runs the model, showing how the cluster’s position in the state space shifts, how resilient it is to perturbations, and what magnitude of intervention is required to move it toward a desired trajectory. Because the simulation is entirely data‑driven, its validity hinges on the richness and representativeness of the input dataset; long‑term forecasts are therefore limited.
The platform’s architecture is modular, with each analytical step encapsulated in a separate Shiny tab: Data Upload, Cluster Your Cases, SOM Training, SOM Analysis, Scenario Simulation, and Predict New Cases. A UML activity diagram illustrates three core user pathways, all of which can be customized. Advanced users can download the underlying R code, modify algorithms, or integrate additional methods.
The authors acknowledge several constraints. First, the empirical dependence of CBSS means that scenarios cannot diverge far from the observed data, limiting exploratory breadth compared with purely theoretical agent‑based models. Second, the current version does not model interactions among cases or clusters; a forthcoming “case‑based ABM” tab aims to address this gap. Third, forecasting far into the future is challenging due to the high uncertainty inherent in complex social systems.
In summary, COMPLEX IT delivers an integrated, user‑friendly environment for case‑centric exploration of complex social data. By coupling traditional clustering (k‑means) with neural‑network mapping (SOM) and a novel scenario‑simulation engine, it enables analysts, policymakers, and evaluation researchers to uncover hidden patterns, test intervention strategies, and gain a deeper mechanistic understanding of emergent social phenomena—all without requiring deep statistical or programming expertise. Future work will expand data types, improve long‑term predictive capabilities, and incorporate explicit inter‑case interaction modeling, positioning COMPLEX IT as a versatile tool for the next generation of computational social science.
Comments & Academic Discussion
Loading comments...
Leave a Comment