Bernoulli Trials With Skewed Propensities for Certification and Validation
The impetus for writing this paper are the well publicized media reports that software failure was the cause of the two recent mishaps of the Boeing 737 Max aircraft. The problem considered here though, is a specific one, in the sense that it endeavors to address the general matter of conditions under which an item such as a drug, a material specimen, or a complex, system can be certified for use based on a large number of Bernoulli trials, all successful. More broadly, the paper is an attempt to answer the old and honorable philosophical question, namely," when can empirical testing on its own validate a law of nature?" Our message is that the answer depends on what one starts with, namely, what is one’s prior distribution, what unknown does this prior distribution endow, and what has been observed as data. The paper is expository in that it begins with a historical overview, and ends with some new ideas and proposals for addressing the question posed. In the sequel, it also articulates on Popper’s notion of “propensity” and its role in providing a proper framework for Bayesian inference under Bernoulli trials, as well as the need to engage with posterior distributions that are subjectively specified; that is, without a recourse to the usual Bayesian prior to posterior iteration.
💡 Research Summary
The paper, motivated by recent high‑profile software failures such as the Boeing 737 Max accidents, asks a fundamental question: under what conditions can a product, a material specimen, or even a natural law be certified solely on the basis of a large number of successful Bernoulli trials? Framed in a Bayesian perspective, the author treats the problem as one of estimating the probability that all N trials would be successes (R = N) given that a random subsample of size n has been observed to be all successes (T = n).
Using Bayes’ theorem, the posterior probability P(R = N | T = n) depends entirely on the prior distribution assigned to the unknown total number of successes R. The paper surveys four families of priors.
-
Bayes‑Laplace (uniform) prior assigns equal weight to every possible value of R (0,…,N), reflecting a principle of insufficient reason. Under this prior, P(R = N | T = n) = (n+1)/(N+1), which tends to zero as N→∞ regardless of how large n is. Thus, even an arbitrarily large streak of successes provides no assurance that future trials will also succeed—an outcome at odds with experimental scientists’ intuition.
-
Jeffreys’ prior places substantial mass at the extremes R = 0 and R = N, with the remaining probability spread uniformly over the interior. A tuning parameter k (0 < k ≤ 1) controls the rate of convergence; for k = ¼ the posterior becomes (n+1)/(n+3), which approaches one as n grows. This prior aligns better with practitioners’ expectations but is somewhat ad‑hoc, lacking a deeper justification.
-
Bernardo’s prior concentrates all prior mass at R = N (or, more generally, at the upper extreme) and yields P(R = N | T = n) ≈ (n+1)/(n+2) for k = ½, converging to one faster than Jeffreys’. Its construction is grounded in information‑theoretic arguments, giving it a stronger theoretical foundation.
-
Portmanteau prior (developed by Singpurwalla and Wilson) assigns point masses at both R = 0 and R = N, controlled by a parameter λ, while the interior probabilities decay exponentially according to parameters q and k. This prior can produce a high probability of non‑failure after only a few successful tests and is especially suitable when the item under test has already undergone extensive vetting (e.g., pre‑debugged software).
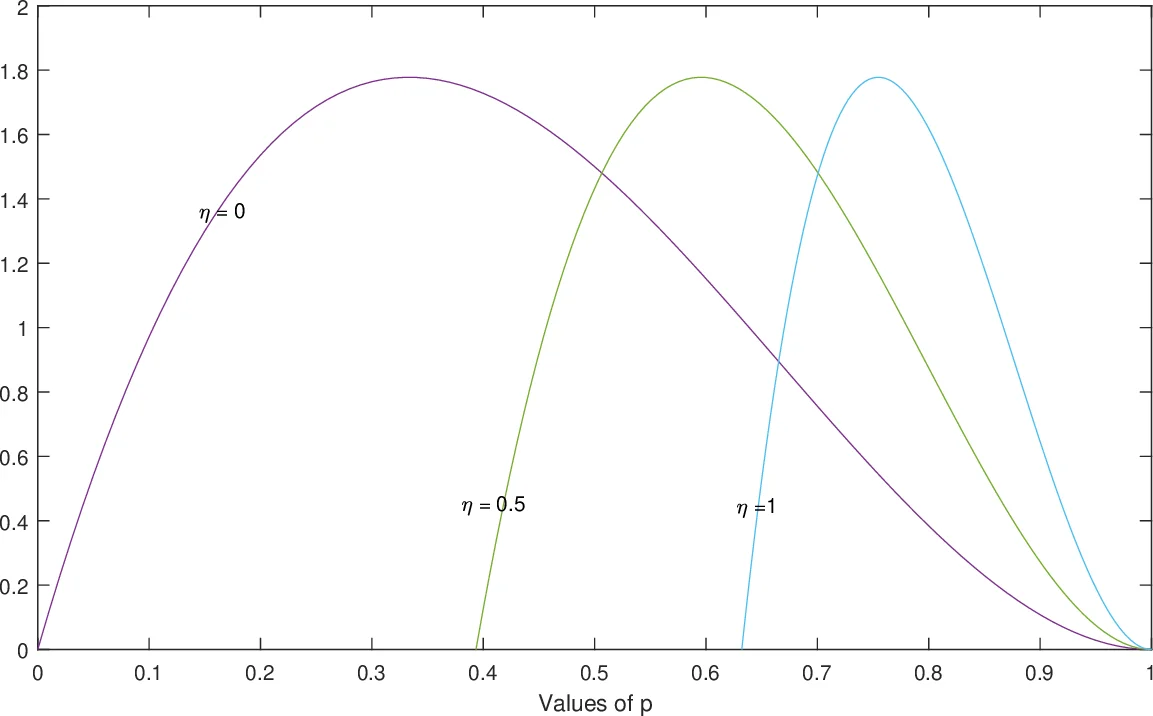
Beyond these discrete‑R priors, the author invokes de Finetti’s exchangeability theorem to give a more principled meaning to “almost identical trials.” In an infinite exchangeable Bernoulli sequence, the observed data are conditionally independent given an unobservable “propensity” p. The prior distribution Π(p) over p is then a continuous analogue of the discrete priors on R. The paper discusses the standard Beta(α, β) family for Π(p), showing how different choices of α and β produce symmetric, left‑skewed, right‑skewed, L‑shaped, J‑shaped, or U‑shaped densities, and how special cases (α < 1, β = 1 or α = 1, β < 1) place point mass at p = 1 or p = 0 respectively. These shapes correspond to different prior beliefs about the underlying propensity to succeed.
The central thesis is that the answer to “when can empirical testing alone validate a law of nature?” is entirely dependent on the prior assumptions one adopts. A conservative prior (uniform) yields a negative answer; priors that embed strong belief in near‑certainty (Bernardo, Portmanteau, or heavily skewed Beta) produce a positive answer. Consequently, any certification or validation exercise must make its prior assumptions explicit, justify them, and recognize that the Bayesian framework provides the only coherent mechanism to combine those assumptions with observed data.
Finally, the paper proposes a novel transformation of the Beta prior to better suit certification contexts, suggesting that practitioners in medicine, engineering, and AI safety can adopt these tailored priors to obtain more realistic posterior assessments of reliability after a finite number of successful tests. The work thus bridges philosophical debates on induction with concrete statistical tools for modern high‑stakes technology certification.
Comments & Academic Discussion
Loading comments...
Leave a Comment