QCD-Aware Recursive Neural Networks for Jet Physics
Recent progress in applying machine learning for jet physics has been built upon an analogy between calorimeters and images. In this work, we present a novel class of recursive neural networks built instead upon an analogy between QCD and natural lan…
Authors: Gilles Louppe, Kyunghyun Cho, Cyril Becot
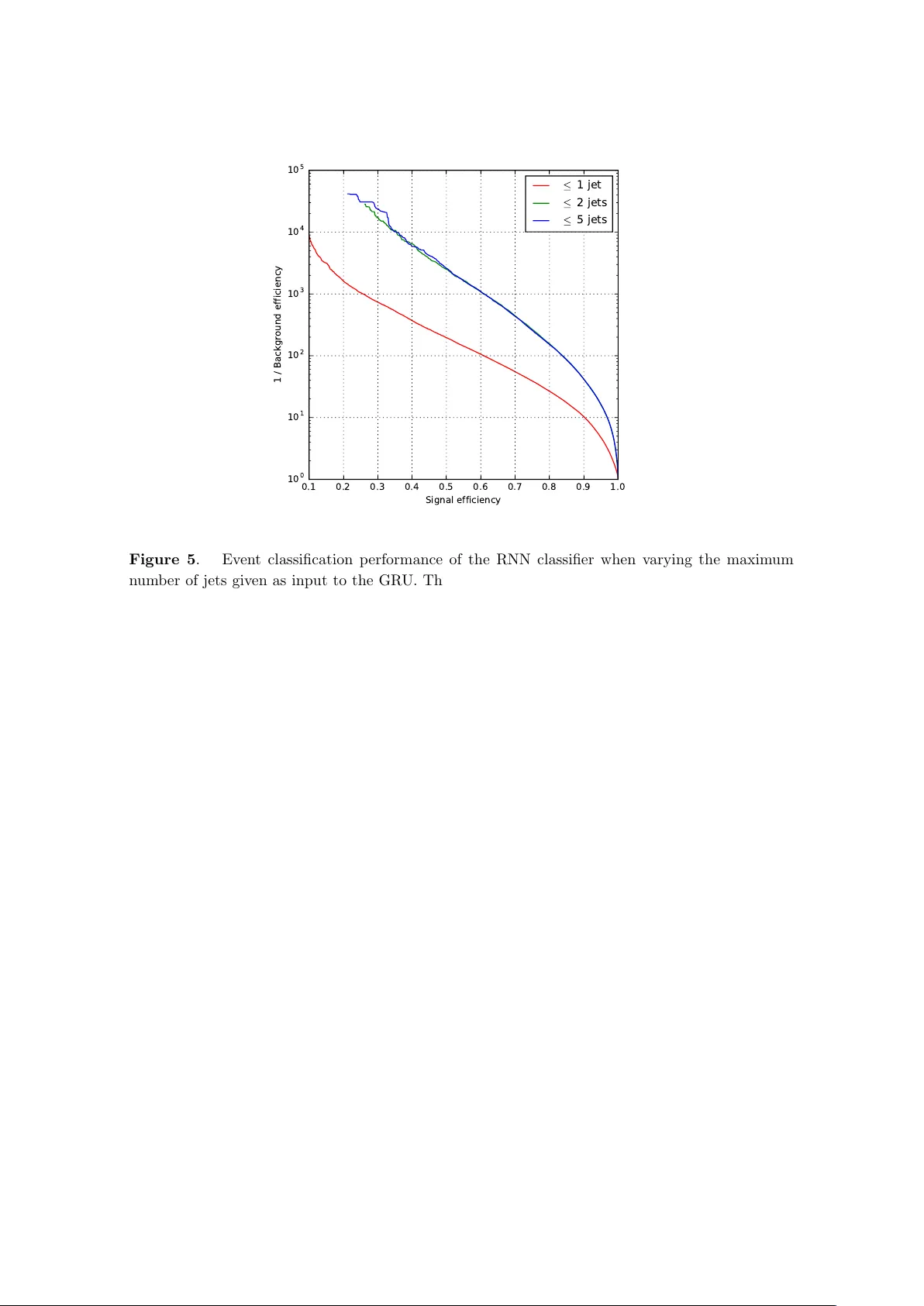
Prep ared for submission to JHEP QCD-Aw are Recursive Neural Net wo rks for Jet Physics Gilles Loupp e a,b, 1 Kyunghyun Cho b Cyril Becot a, 2 Kyle Cranmer a,b a New Y ork University, Center for Cosmolo gy & Particle Physics, 726 Br o adway, New Y ork, NY b New Y ork University, Center for Data Scienc e, 60 5th Ave., New Y ork, NY E-mail: g.louppe@uliege.be , kyunghyun.cho@nyu.edu , cyril.becot@cern.ch , kyle.cranmer@nyu.edu Abstract: Recen t progress in applying mac hine learning for jet ph ysics has b een built up on an analogy b etw een calorimeters and images. In this work, w e present a no vel class of recursive neural net w orks built instead up on an analogy betw een QCD and natural languages. In the analogy , four-momen ta are like words and the clustering history of sequen tial recom bination jet algorithms is lik e the parsing of a sen tence. Our approac h w orks directly with the four-momen ta of a v ariable-length set of particles, and the jet-based tree structure v aries on an ev ent-b y-even t basis. Our exp eriments highlight the flexibilit y of our metho d for building task-specific jet embeddings and show that recursive arc hitectures are significan tly more accurate and data efficient than previous image-based netw orks. W e extend the analogy from individual jets (sen tences) to full ev ents (paragraphs), and show for the first time an ev en t-lev el classifier op erating on all the stable particles produced in an LHC even t. ArXiv ePrint: 1702.00748 1 Curren tly at Univ ersity of Li ` ege 2 Curren tly at DESY Con ten ts 1 In tro duction 1 2 Problem statemen t 3 3 Recursiv e em bedding 3 3.1 Individual jets 3 3.2 F ull ev en ts 5 4 Data, Prepro cessing and Experimental Setup 6 5 Exp eriments with Jet-Lev el Classification 7 5.1 P erformance studies 7 5.2 Infrared and Collinear Safet y Studies 11 6 Exp eriments with ev en t-lev el classification 12 7 Related w ork 14 8 Conclusions 16 A Gated recursiv e jet em b edding 20 B Gated recurrent ev ent embedding 21 C Implemen tation details 21 1 In tro duction By far the most c ommon structures seen in collisions at the Large Hadron Collider (LHC) are collimated sprays of energetic hadrons referred to as ‘jets’. These jets are pro duced from the fragmen tation and hadronization of quarks and gluons as describ ed by quantum c hromo dynamics (QCD). Sev eral goals for the LHC are cen tered around the treatmen t of jets, and there has b een an enormous amoun t of effort from both the theoretical and ex- p erimen tal communities to develop techniques that are able to cop e with the exp erimental realities while maintaining precise theoretical prop erties. In particular, the comm unities ha v e conv erged on sequential recom bination jet algorithms, metho ds to study jet substruc- ture, and gro oming tec hniques to provide robustness to pileup. One compelling physics challenge is to searc h for highly b o osted standard model par- ticles decaying hadronically . F or instance, if a hadronically decaying W b oson is highly – 1 – b o osted, then its deca y pro ducts will merge in to a single fat jet with a c haracteristic sub- structure. Unfortunately , there is a large bac kground from jets pro duced b y more mundane QCD processes. F or this reason, several jet ‘taggers’ and v ariables sensitive to jet substruc- ture ha v e b een prop osed. Initially , this work was dominated by techniques inspired by our in tuition and kno wledge of QCD; how ever, more recen tly there has b een a wa ve of ap- proac hes that eschew this exp ert kno wledge in fav or of machine learning tec hniques. In this pap er, w e presen t a hybrid approac h that leverages the structure of sequen tial recom- bination jet algorithms and deep neural net w orks. Recen t progress in applying mac hine learning techniques for jet physics has b een built up on an analogy betw een calorimeters and images [ 1 – 8 ]. These metho ds take a v ariable- length set of 4-momen ta and pro ject them into a fixed grid of η − φ to w ers or ‘pixels’ to pro duce a ‘jet image’. The original jet classification problem, hence, reduces to an image classification problem, lending itself to deep con volutional net works and other mac hine learning algorithms. Despite their promising results, these mo dels suffer from the fact that they ha v e many free parameters and that they require large amoun ts of data for training. More imp ortantly , the pro jection of jets into images also loses information, whic h impacts classification p erformance. The most obvious w ay to address this issue is to use a recurren t neural net work to pro cess a sequence of 4-momen ta as they are. Ho w ev er, it is not clear ho w to order this sequence. While p T ordering is common in man y contexts [ 5 ], it do es not capture important angular information critical for understanding the subtle structure of jets. In this w ork, w e propose instead a solution for jet classification based on an analogy b et w een QCD and natural languages, as inspired by sev eral works from natural language pro cessing [ 9 – 14 ]. Much lik e a sentence is comp osed of w ords following a syntactic struc- ture organized as a parse tree, a jet is also comp osed of 4-momen ta following a structure dictated by QCD and organized via the clustering history of a sequential recom bination jet algorithm. More specifically , our approac h uses ‘recursive’ netw orks where the top ology of the netw ork is giv en by the clustering history of a sequen tial recom bination jet algorithm, whic h v aries on an even t-by-ev en t basis. This even t-by-ev ent adaptiv e structure can b e con trasted with the ‘recurren t’ netw orks that op erate purely on sequences (see e.g., [ 15 ]). The net work is therefore giv en the 4-momen ta without an y loss of information, in a wa y that also captures substructures, as motiv ated by ph ysical theory . It is con venien t to think of the recursive neural netw ork as pro viding a ‘jet embedding’, whic h maps a set of 4-momenta into R q . This embedding has fixed length and can b e fed in to a subsequent netw ork used for classification or regression. Th us the pro cedure can b e used for jet tagging or estimating parameters that c haracterize the jet, suc h as the masses of resonances buried inside the jet. Importantly , the em bedding and the subsequen t netw ork can be trained join tly so that the embedding is optimized for the task at hand. Extending the natural language analogy paragraphs of text are sequence of sentences, just as ev ent are sequence of jets. In particular, we prop ose to em b ed the full particle con ten t of an ev en t by feeding a sequence of jet-embeddings into a recurren t net w ork. As b efore, this even t-level embedding can b e fed into a subsequen t net w ork used for classifi- cation or regression. T o our kno wledge, this represents the first mac hine learning mo del – 2 – op erating on all the detectable particles in an even t. The remainder of the pap er is structured as follo ws. In Sec. 2 , we formalize the classification tasks at the jet-lev el and even t-level. W e describe the prop osed recursiv e net w ork architectures in Sec. 3 and detail the data samples and prepro cessing used in our experiments in Sec. 4 . Our results are summarized and discussed first in Sec. 5 for exp erimen ts on a jet-level classification problem, and then in Sec. 6 for experiments on an ev ent-lev el classification problem. In Sec. 7 , we relate our work to close con tributions from deep learning, natural language pro cessing, and jet physics. Finally , w e gather our conclusions and directions for further works in Sec. 8 . 2 Problem statement W e describ e a collision ev ent e ∈ E as being comp osed of a v arying n um b er of particles, indexed b y i , and where eac h particle is represented by its 4-momen tum vector v i ∈ R 4 , suc h that e = { v i | i = 1 , . . . , N } . The 4-momenta in eac h even t can be clustered in to jets with a sequen tial recom bination jet algorithm that recursively combines (b y simply adding their 4-momen ta) the pair i, i 0 that minimize d α ii 0 = min( p 2 α ti , p 2 α ti 0 ) ∆ R 2 ii 0 R 2 (2.1) while d α ii 0 is less than min( p 2 α ti , p 2 α ti 0 ) [ 16 , 17 ]. These sequen tial recom bination algorithms ha v e three hyper-parameters: R , p t, min , α , and jets with p t < p t, min are discarded. At that p oin t, the jet algorithm has clustered e into M jets, each of which can b e represented b y a binary tree t j ∈ T indexed b y j = 1 , . . . , M with N j lea v es (corresponding to a subset of the v i ). In the following, w e will consider the specific cases where α = 1 , 0 , − 1, whic h resp ectiv ely correspond to the k t , Cam bridge-Aachen and anti- k t algorithms. In addition to jet algorithms, we consider a ‘random’ baseline that corresp onds to recom bining particles at random to form random binary trees t j , along with ‘asc- p T ’ and ‘desc- p T ’ baselines, whic h correspond to degenerate binary trees formed from the sequences of particles sorted resp ectiv ely in ascending and descending order of p T . F or jet-level classification or regression, eac h jet t j ∈ T in the training data comes with lab els or regression v alues y j ∈ Y jet . In this framew ork, our goal is to build a pre- dictiv e mo del f jet : T 7→ Y jet minimizing some loss function L jet . Similarly , for even t-level classification or regression, we assume that eac h collision ev en t e l ∈ E in the training data comes with labels or regression v alues y l ∈ Y even t , and our goal is to build a predictiv e mo del f even t : E 7→ Y even t minimizing some loss function L even t . 3 Recursiv e embedding 3.1 Individual jets Let us first consider the case of an individual jet whose particles are top ologically structured as a binary tree t j , e.g., based on a sequential recom bination jet clustering algorithm or a simple sequen tial sorting in p T . Let k = 1 , . . . , 2 N j − 1 indexes the no de of the binary tree – 3 – t j , and let the left and righ t c hildren of no de k b e denoted by k L and k R resp ectiv ely . Let also k L alw a ys b e the hardest c hild of k . By construction, we supp ose that lea v es k map to particles i ( k ) while in ternal no des corresp ond to recombinations. Using these notations, w e recursiv ely define the embedding h jet k ∈ R q of node k in t j as v 1 v 2 ... v N j h jet 1 ( t j ) h jet k h jet k L h jet k R ... f jet ( t j ) Classifier Jet emb e dding Figure 1 . QCD-motiv ated recursiv e jet em b edding for classification. F or each individual jet, the em b edding h jet 1 ( t j ) is computed recursiv ely from the root no de do wn to the outer nodes of the binary tree t j . The resulting embedding is chained to a subsequent classifier, as illustrated in the top part of the figure. The topology of the netw ork in the b ottom part is distinct for eac h jet and is determined b y a sequen- tial recombination jet algorithm (e.g., k t clustering). h jet k = u k if k is a leaf σ W h h jet k L h jet k R u k + b h otherwise (3.1) u k = σ ( W u g ( o k ) + b u ) (3.2) o k = ( v i ( k ) if k is a leaf o k L + o k R otherwise (3.3) where W h ∈ R q × 3 q , b h ∈ R q , W u ∈ R q × 4 and b u ∈ R q form together the shared parameters to b e learned, q is the size of the em b edding, σ is the ReLU activ ation function [ 18 ], and g is a function extracting the kinematic features p , η , θ , φ , E , and p T from the 4-momentum o k . When applying Eqn. 3.1 recursively from the ro ot no de k = 1 down to the outer no des of the binary tree t j , the resulting embedding, de- noted h jet 1 ( t j ), effectively summarizes the informa- tion con tained in the particles forming the jet in to a single vector. In particular, this recursive neural net w ork (RNN) embeds a binary tree of v arying shap e and size in to a v ector of fixed size. As a result, the em bedding h jet 1 ( t j ) can no w b e chained to a subsequent classifier or regressor to solve our target sup ervised learning problem, as illustrated in Figure 1 . All parameters (i.e., of the recursiv e jet embedding and of the classifier) are learned join tly using bac kpropagation through structure [ 9 ] to minimize the loss L jet , hence tailoring the em b edding to the specific requiremen ts of the task. F urther implemen tation details, including an ef- ficien t batched computation o v er distinct binary trees, can b e found in App endix C . – 4 – h jet 1 ( t 1 ) v ( t 1 ) h jet 1 ( t 2 ) v ( t 2 ) ... ... h jet 1 ( t M ) v ( t M ) h even t M ( e ) Event emb edding ... f even t ( e ) Classifier Figure 2 . QCD-motiv ated even t embedding for classification. The em b edding of an even t is computed b y feeding the sequence of pairs ( v ( t j ) , h jet 1 ( t j )) o ver the jets it is made of, where v ( t j ) is the unpro cessed 4-momentum of the jet t j and h jet 1 ( t j ) is its em b edding. The resulting ev en t-level em b edding h even t M ( e ) is c hained to a subsequent classifier, as illustrated in the righ t part of the figure. In addition to the recursive activ ation of Eqn. 3.1 , we also consider and study its extended v ersion equipp ed with reset and up date gates (see details in Appendix A ). This gated architecture allows the net work to preferen tially pass information along the left-c hild, righ t-c hild, or their com bination. While we hav e not p erformed exp eriments, w e point out that there is an analogous st yle of architectures based on jet algorithms with 2 → 3 recom binations [ 17 , 19 , 20 ]. 3.2 F ull ev ents W e no w em b ed en tire ev ents e of v ariable size b y feeding the em beddings of their individual jets to an ev en t-lev el sequence-based recurrent neural net w ork. As an illustrativ e example, w e consider here a gated recurren t unit [ 21 ] (GRU) op er- ating on the p T ordered sequence of pairs ( v ( t j ) , h jet 1 ( t j )), for j = 1 , . . . , M , where v ( t j ) is the unpro cessed 4-momen tum of the jet t j and h jet 1 ( t j ) is its em b edding. The final output h even t M ( e ) (see App endix B for details) of the GRU is c hained to a subsequen t classifier to solv e an even t-lev el classification task. Again, all parameters (i.e., of the inner jet embed- ding function, of the GR U, and of the classifier) are learned join tly using bac kpropagation through structure [ 9 ] to minimize the loss L even t . Figure 2 pro vides a sc hematic of the full classification mo del. In summary , combining tw o levels of recurrence provides a QCD- motiv ated ev en t-lev el embedding that effectively op erates at the hadron-level for all the particles in the ev en t. – 5 – In addition and for the purp ose of comparison, we also consider the simpler baselines where i) only the 4-momenta v ( t j ) of the jets are given as input to the GRU, without augmen tation with their embeddings, and ii) the 4-momen ta v i of the constituents of the ev ent are all directly giv en as input to the GR U, without grouping them into jets or pro viding the jet em b eddings. 4 Data, Prepro cessing and Exp erimental Setup In order to fo cus attention on the impact of the netw ork arc hitectures and the pro jection of input 4-momenta in to images, w e consider the same b o osted W tagging example as used in Refs. [ 1 , 2 , 4 , 6 ]. The signal ( y = 1) corresponds to a hadronically deca ying W b oson with 200 < p T < 500 GeV, while the background ( y = 0) corresp onds to a QCD jet with the same range of p T . W e are grateful to the authors of Ref. [ 6 ] for sharing the data used in their studies. W e obtained b oth the full-even t records from their PYTHIA b enchmark samples, including b oth the particle-lev el data and the to w ers from the DELPHES detector sim ulation. In addition, w e obtained the fully pro cessed jet images of 25 × 25 pixels, whic h include the initial R = 1 an ti- k t jet clustering and subsequent trimming, translation, pixelisation, rotation, reflection, cropping, and normalization prepro cessing stages detailed in Ref. [ 2 , 6 ]. Our training data was collected b y sampling from the original data a total of 100,000 signal and bac kground jets with equal prior. The testing data w as assembled similarly by sampling 100,000 signal and bac kground jets, without o v erlap with the training data. F or direct comparison with Ref. [ 6 ], p erformance is ev aluated at test time within the restricted windo w of 250 < p T < 300 and 50 ≤ m ≤ 110, where the signal and background jets are re-weigh ted to pro duce flat p T distributions. Results are rep orted in terms of the area under the ROC curve (R OC A UC) and of backgrou nd rejection (i.e., 1/FPR) at 50% signal efficiency ( R =50% ). Average scores reported include uncertaint y estimates that come from training 30 mo dels with distinct initial random seeds. About 2% of the mo dels had tec hnical problems during training (e.g., due to n umerical errors), so we applied a simple algorithm to ensure robustness: we discarded mo dels whose R =50% w as outside of 3 standard deviations of the mean, where the mean and standard deviation w ere estimated excluding the five b est and worst p erforming mo dels. F or our jet-lev el exp eriments we consider as input to the classifiers the 4-momenta v i from b oth the particle-level data and the DELPHES tow ers. W e also compare the p erformance with and without the pro jection of those 4-momen ta in to images. While the image data already included the full pre-processing steps, when considering particle-lev el and tow er inputs w e p erformed the initial R = 1 anti- k t jet clustering to iden tify the constituen ts of the highest p T jet t 1 of eac h even t, and then p erformed the subsequen t translation, rotation, and reflection pre-pro cessing steps (omitting cropping and normalization). When pro cessing the image data, we in v erted the normalization that enforced the sum of the squares of the pixel in tensities b e equal to one. 1 1 In Ref. [ 2 ], the jet images did not include the DELPHES detector simulation, they were comparable to our particle scenario with the additional discretization into pixels. – 6 – F or our even t-level exp eriments we w ere not able to use the data from Ref. [ 6 ] b ecause the signal sample corresp onded to pp → W ( → J ) Z ( → ν ¯ ν ) and the bac kground to pp → j j . Thus the signal w as c haracterized b y one high- p T jet and large missing energy from Z ( → ν ¯ ν ) whic h is trivially separated from the dijet background. F or this reason, w e generated our o wn PYTHIA and DELPHES samples of pp → W 0 → W ( → J ) Z ( → J ) and QCD background such that b oth the signal and background hav e t w o high- p T jets. W e use m W 0 = 700 GeV and restrict ˆ p t of the 2 → 2 scattering pro cess to 300 < ˆ p t < 350 GeV. Our focus is to demonstrate the scalabilit y of our metho d to all the particles or to w ers in an ev en t, and not to provide a precise statement ab out physics reach for this signal process. In this case each even t e was clustered by the same anti- k t algorithm with R = 1, and then the constituen ts of eac h jet were treated as in Sec. 3.1 (i.e., reclustered using k t or a sequen tial ordering in p T to provide the netw ork top ology for a non-gated em b edding). Additionally , the c onstituen ts of eac h jet w ere pre-pro cessed with translation, rotation, and reflection as in the individual jet case. T raining w as carried out on a dataset of 100,000 signal and bac kground even ts with equal prior. Performance w as ev aluated on an independent test set of 100,000 other even ts, as measured by the ROC A UC and R =80% of the mo del predictions. Again, av erage scores are given with uncertain t y estimates that come from training 30 models with distinct initial random seeds. In b oth jet-lev el and even t-level experiments, the dimension of the em b eddings q w as set to 40. T raining was conducted using Adam [ 22 ] as an optimizer for 25 ep o c hs, with a batc h size of 64 and a learning rate of 0 . 0005 deca y ed b y a factor of 0 . 9 after every ep o c h. These parameters were found to p erform b est on a v erage, as determined through an optimization of the hyper-parameters. Performance w as monitored during training on a v alidation set of 5000 samples to allo w for early stopping and prev en t from ov erfitting. 5 Exp erimen ts with Jet-Lev el Classification 5.1 P erformance studies W e carried out performance studies where we v aried the follo wing factors: the pro jection of the 4-momen ta into an image, the source of those 4-momenta, the top ology of the RNN, and the presence or absence of gating. Impact of image pro jection The first factor w e studied was whether or not to pro ject the 4-momen ta in to an image as in Refs. [ 2 , 6 ]. The arc hitectures used in previous stud- ies required a fixed input (image) representation, and cannot b e applied to the v ariable length set of input 4-momenta. Con v ersely , w e can apply the RNN architecture to the discretized image 4-momen ta. T able 1 shows that the RNN architecture based on a k t top ology p erforms almost as well as the MaxOut arc hitecture in Ref. [ 6 ] when applied to the image pre-processed 4-momen ta coming from DELPHES to wers. Imp ortan tly the RNN arc hitecture is muc h more data efficien t. While the MaxOut architecture in Ref. [ 6 ] has 975,693 parameters and w as trained with 6M examples, the non-gated RNN arc hitecture has 8,481 parameters and w as trained with 100,000 examples only . – 7 – T able 1 . Summary of jet classification p erformance for several approaches applied either to particle- lev el inputs or tow ers from a DELPHES simulation. Input Arc hitecture R OC A UC R =50% Pro jected in to images to w ers MaxOut 0.8418 – to w ers k t 0.8321 ± 0.0025 12.7 ± 0.4 to w ers k t (gated) 0.8277 ± 0.0028 12.4 ± 0.3 Without image prepro cessing to w ers τ 21 0.7644 6.79 to w ers mass + τ 21 0.8212 11.31 to w ers k t 0.8807 ± 0.0010 24.1 ± 0.6 to w ers C/A 0.8831 ± 0.0010 24.2 ± 0.7 to w ers an ti- k t 0.8737 ± 0.0017 22.3 ± 0.8 to w ers asc- p T 0.8835 ± 0.0009 26.2 ± 0.7 to w ers desc- p T 0.8838 ± 0.0010 25.1 ± 0.6 to w ers random 0.8704 ± 0.0011 20.4 ± 0.3 particles k t 0.9185 ± 0.0006 68.3 ± 1.8 particles C/A 0.9192 ± 0.0008 68.3 ± 3.6 particles an ti- k t 0.9096 ± 0.0013 51.7 ± 3.5 particles asc- p T 0.9130 ± 0.0031 52.5 ± 7.3 particles desc- p T 0.9189 ± 0.0009 70.4 ± 3.6 particles random 0.9121 ± 0.0008 51.1 ± 2.0 With gating (see App endix A ) to w ers k t 0.8822 ± 0.0006 25.4 ± 0.4 to w ers C/A 0.8861 ± 0.0014 26.2 ± 0.8 to w ers an ti- k t 0.8804 ± 0.0010 24.4 ± 0.4 to w ers asc- p T 0.8849 ± 0.0012 27.2 ± 0.8 to w ers desc- p T 0.8864 ± 0.0007 27.5 ± 0.6 to w ers random 0.8751 ± 0.0029 22.8 ± 1.2 particles k t 0.9195 ± 0.0009 74.3 ± 2.4 particles C/A 0.9222 ± 0.0007 81.8 ± 3.1 particles an ti- k t 0.9156 ± 0.0012 68.3 ± 3.2 particles asc- p T 0.9137 ± 0.0046 54.8 ± 11.7 particles desc- p T 0.9212 ± 0.0005 83.3 ± 3.1 particles random 0.9106 ± 0.0035 50.7 ± 6.7 Next, we compare the RNN classifier based on a k t top ology on tow er 4-momen ta with and without image prepro cessing. T able 1 and Fig. 3 sho w significan t gains in not using jet images, improving R OC A UC from 0 . 8321 to 0 . 8807 (resp., R =50% from 12 . 7 to 24 . 1) in the case of k t top ologies. In addition, this result outperforms the MaxOut architecture – 8 – op erating on images b y a significan t margin. This suggests that the pro jection in to an image loses information and impacts classification performance. W e suspect the loss of information to b e due to some of the construction steps of jet images (i.e., pixelisation, rotation, zo oming, cropping and normalization). In particular, all are applied at the image- lev el instead of b eing p erformed directly on the 4-momen ta, which might induce artefacts due to the low er resolution, particle sup erp osition and aliasing. By con trast, the RNN is able to work directly with the 4-momenta of a v ariable-length set of particles, without any loss of information. F or completeness, we also compare to the p erformance of a classifier based purely on the single n -sub jettiness feature τ 21 := τ 2 / τ 1 and a classifier based on t wo features (the trimmed mass and τ 21 ) [ 23 ]. In agreemen t with previous results based on deep learning [ 2 , 6 ], w e see that our RNN classifier clearly outp erforms this v ariable. Measuremen ts of the 4-momen ta The second factor we v aried w as the source of the 4-momen ta. The towers scenario, corresp onds to the case where the 4-momenta come from the calorimeter simulation in DELPHES . While the calorimeter simulation is simplistic, the granularit y of the tow ers is quite large (10 ◦ in φ ) and it do es not take into accoun t that trac king detectors can provide very accurate momenta measurements for charged particles that can b e com bined with calorimetry as in the particle flow approac h. Th us, w e also consider the p articles scenario, whic h corresp onds to an idealized case where the 4-momen ta come from p erfectly measured stable hadrons from PYTHIA . T able 1 and Fig. 3 sho w that further gains could b e made with more accurate measurements of the 4-momenta, impro ving e.g. R OC AUC from 0 . 8807 to 0 . 9185 (resp., R =50% from 24 . 1 to 68 . 3) in the case of k t top ologies. W e also considered a case where the 4-momentum came from the DELPHES particle flow simulation and the data asso ciated with each particle w as augmented with a particle-flo w iden tifier distinguishing ± c harged hadrons, photons, and neutral hadrons. This is similar in motiv ation to Ref. [ 7 ], but we did not observe an y significant gains in classification performance with respect to the towers scenario. T op ology of the binary trees The third factor we studied w as the top ology of the binary tree t j describ ed in Sections 2 and 3.1 that dictates the recursiv e structure of the RNN. W e considered binary trees based on the anti- k t , Cambridge-Aac hen (C/A), and k t sequen tial recombination jet algorithms, along with random, asc- p T and desc- p T binary trees. T able 1 and Fig. 4 show the p erformance of the RNN classifier based on these v arious top ologies. In terestingly , the topology is significan t. F or instance, k t and C/A significantly outperform the an ti- k t top ology on b oth tow er and particle inputs. This is consisten t with in tuition from previous jet substructure studies where jets are t ypically reclustered with the k t algorithm. The fact that the top ology is imp ortan t is further supp orted by the p o or performance of the random binary tree top ol- ogy . W e exp ected ho wev er that a simple sequence (represen ted as a degenerate binary tree) based on ascending and descending p T ordering w ould not p erform particularly well, par- ticularly since the top ology do es not use any angular information. Surprisingly , the simple descending p T ordering slightly outperforms the RNNs based on k t and C/A top ologies. The descending p T net w ork has the highest p T 4-momen ta near the ro ot of the tree, whic h w e exp ect to b e the most imp ortant. W e susp ect this is the reason that the descending – 9 – 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Signal efficiency 1 0 0 1 0 1 1 0 2 1 / Background efficiency particles towers images Figure 3 . Jet classification p erformance for v arious input represen tations of the RNN classifier, using k t top ologies for the em b edding. The plot shows that there is significant improv emen t from remo ving the image pro cessing step and that significant gains can be made with more accurate measuremen ts of the 4-momenta. p T outp erforms the ascending p T ordering on particles, but this is not supp orted by the p erformance on to w ers. A similar observ ation w as already made in the con text of natural languages [ 24 – 26 ], where tree-based models hav e at b est only sligh tly outperformed sim- pler sequence-based netw orks. While recursiv e net works app ear as a principled c hoice, it is conjectured that recurren t net w orks may in fact b e able to disco v er and implicitly use recursiv e compositional structure b y themselves, without sup ervision. Gating The last factor that we v aried w as whether or not to incorporate gating in the RNN. Adding gating increases the num ber of parameters to 48,761, but this is still about 20 times smaller than the n um b er of parameters in the MaxOut architectures used in previous jet image studies. T able 1 shows the p erformance of the v arious RNN top ologies with gating. While results improv e significantly with gating, most notably in terms of R =50% , the trends in terms of top ologies remain unchanged. Other v arian ts Finally , we also considered a num b er of other v arian ts. F or example, w e jointly trained a classifier with the concatenated embeddings obtained ov er k t and anti- k t top ologies, but saw no significan t p erformance gain. W e also tested the p erformance of recursiv e activ ations transferred across topologies. F or instance, w e used the recursiv e activ ation learned with a k t top ology when applied to an an ti- k t top ology and observ ed a significan t loss in p erformance. W e also considered particle and to w er level inputs with an additional trimming prepro cessing step, whic h was used for the jet image studies, but we – 10 – 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Signal efficiency 1 0 0 1 0 1 1 0 2 1 / Background efficiency k t C/A a n t i - k t a s c - p T d e s c - p T random Figure 4 . Jet classification p erformance of the RNN classifier based on v arious netw ork top ologies for the embedding ( p articles scenario). This plot shows that top ology is significant, as supp orted b y the fact that results for k t , C/A and desc- p T top ologies improv e ov er results for anti- k t , asc- p T and random binary trees. Best results are achiev ed for C/A and desc- p T top ologies, dep ending on the metric considered. sa w a significant loss in p erformance. While the trimming degraded classification p erfor- mance, we did not ev aluate the robustness to pileup that motiv ates trimming and other jet grooming pro cedures. 5.2 Infrared and Collinear Safet y Studies In prop osing v ariables to characterize substructure, physicists ha ve b een equally concerned with classification p erformance and the abilit y to ensure v arious theoretical prop erties of those v ariables. In particular, initial w ork on jet algorithms fo cused on the Infrared- Collinear (IR C) safe conditions: • Infr ar e d safety. The mo del is robust to augmenting e with additional particles { v N +1 , . . . , v N + K } with small transv erse momen tum. • Col line ar safety. The model is robust to a collinear splitting of a particle, which is represen ted by replacing a particle v j ∈ e with t w o particles v j 1 and v j 2 , such that v j = v j 1 + v j 2 and v j 1 · v j 2 = || v j 1 || || v j 2 || − . The sequen tial recom bination algorithms lead to an IRC-safe definition of jets, in the sense that given the ev ent e , the n um b er of jets M and their 4-momenta v ( t j ) are IRC-safe. An early motiv ation of this w ork is that basing the RNN top ology on the sequen tial recom bination algorithms would pro vide an av enue to mac hine learning classifiers with some – 11 – theoretical guarantee of IRC safet y . If one only wan ts to ensure robustness to only one soft particle or one collinear split, this could b e satisfied b y simply running a single iteration of the jet algorithm as a pre-processing step. How e v er, it is difficult to ensure a more general notion of IRC safety on the em bedding due to the non-linearities in the net work. Nev ertheless, we can explicitly test the robustness of the embedding or the subsequen t classifier to the addition of soft particles or collinear splits to the input 4-momen ta. T able 2 sho ws the results of a non-gated RNN trained on the nominal particle-level input when applied to testing data with additional soft particles or collinear splits. The collinear splits were uniform in the momentum fraction and maintained the small inv ariant mass of the hadrons. W e considered one or ten collinear splits on both random particles and the highest p T particles. W e see that while the 30 mo dels trained with a descending p T top ology v ery slightly outp erform the k t top ology for almost scenarios, their p erformance in terms of R =50% decreases relativ ely more rapidly when collinear splits are applied (see e.g., the c ol line ar10-max scenarios where the p erformance of k t decreases b y 4%, while the p erformance of p T decreases by 10%). This suggests a higher robustness to w ards collinear splits for recursive netw orks based on k t top ologies. W e also p oint out that the training of these net works is based solely on the classification loss for the nominal sample. If we are truly concerned with the IR C-safet y considerations, then it is natural to augment the training of the class ifiers to b e robust to these v ariations. A num b er of mo dified training pro cedures exist, including e.g., the adversarial training pro cedure described in Ref. [ 27 ]. 6 Exp erimen ts with ev en t-lev el classification As in the previous section, we carried out a num ber of p erformance studies. How ev er, our goal is mainly to demonstrate the relev ance and scalability of the QCD-motiv ated approac h w e prop ose, rather than making a statement ab out the physics reach of the signal pro cess. Results are discussed considering the idealized p articles scenario, where the 4-momen ta come from perfectly measured stable hadrons from PYTHIA . Experiments for the towers scenario (omitted here) rev eal similar qualitativ e conclusions, though p erformance was sligh tly w orse for all mo dels, as exp ected. Num b er of jets The first factor we v aried w as the maxim um n umber of jets in the sequence of em b eddings giv en as input to the GR U. While the ev ent-lev el em bedding can b e computed ov er all the jets it is constituted by , QCD suggests that the 2 highest p T jets hold most of the information to separate signal from bac kground ev ents, with only marginal discriminating information left in the subsequen t jets. As T able 3 and Fig. 5 sho w, there is indeed significan t impro v emen t in going from the hardest jet to the 2 hardest jets, while there is no to little gain in considering more jets. Let us also emphasize that the even t-level mo dels ha ve only 18,681 parameters, and were trained on 100,000 training examples. T op ology of the binary trees The second factor we studied was the architecture of the net w orks used for the inner em b edding of the jets, for which we compare k t against descend- – 12 – T able 2 . Performance of pre-trained RNN classifiers (without gating) applied to nominal and mo dified particle inputs. The c ol line ar1 ( c ol line ar10 ) scenarios corresp ond to applying collinear splits to one (ten) random particles within the jet. The c ol line ar1-max ( c ol line ar10-max ) scenarios corresp ond to applying collinear splits to the highest p T (ten highest p T ) particles in the jet. The soft scenario corresp onds to adding 200 particles with p T = 10 − 5 GeV uniformly in 0 < φ < 2 π and − 5 < η < 5. Scenario Arc hitecture R OC A UC R =50% nominal k t 0.9185 ± 0.0006 68.3 ± 1.8 nominal desc- p T 0.9189 ± 0.0009 70.4 ± 3.6 collinear1 k t 0.9183 ± 0.0006 68.7 ± 2.0 collinear1 desc- p T 0.9188 ± 0.0010 70.7 ± 4.0 collinear10 k t 0.9174 ± 0.0006 67.5 ± 2.6 collinear10 desc- p T 0.9178 ± 0.0011 67.9 ± 4.3 collinear1-max k t 0.9184 ± 0.0006 68.5 ± 2.8 collinear1-max desc- p T 0.9191 ± 0.0010 72.4 ± 4.3 collinear10-max k t 0.9159 ± 0.0009 65.7 ± 2.7 collinear10-max desc- p T 0.9140 ± 0.0016 63.5 ± 5.2 soft k t 0.9179 ± 0.0006 68.2 ± 2.3 soft desc- p T 0.9188 ± 0.0009 70.2 ± 3.7 ing p T top ologies. As in the previous section, b est results are achiev ed with descending p T top ologies, though the difference is only marginal. Other v ariants Finally , we also compare with baselines. With respect to an even t-lev el em b edding computed only from the 4-momen ta v ( t j ) (for j = 1 , . . . , M ) of the jets, w e find that augmen ting the input to the GRU with jet-lev el em b eddings yields significan t impro v emen t, e.g. improving ROC AUC from 0 . 9606 to 0 . 9875 (resp. R =80% from 21 . 1 to 174 . 5) when considering the 2 hardest jets case. This suggests that jet substructures are imp ortan t to separate signal from background ev ents, and correctly learned when nesting em b eddings. Similarly , w e observ e that directly feeding the GRU with the 4-momen ta v i , for i = 1 , . . . , N , of the constituen ts of the ev en t performs significantly worse. While p erformance remains decen t (e.g., with a R OC A UC of 0 . 8925 when feeding the 50 4- momen ta with largest p T ), this suggests that the recurren t net work fails to leverage some of the relev ant information, whic h is otherwise easier to identify and learn when inputs to the GR U come directly grouped as jets, themselves structured as trees. In con trast to our previous results for jet-level exp eriments, this last comparison underlines the fact that in tegrating domain kno wledge by structuring the netw ork top ology is in some cases crucial for performance. Ov erall, this study shows that ev ent em b eddings inspired from QCD and pro duced b y nested recurrence, ov er the jets and o ver their constituents, is a promising a v en ue for building effectiv e mac hine learning mo dels. T o our knowledge, this is the first classifier – 13 – T able 3 . Summary of ev en t classification performance. Best results are achiev ed through nested recurrence ov er the jets and ov er their constituents, as motiv ated by QCD. Input R OC A UC R =80% Hardest jet v ( t j ) 0.8909 ± 0.0007 5.6 ± 0.0 v ( t j ), h jet( k t ) j 0.9602 ± 0.0004 26.7 ± 0.7 v ( t j ), h jet(desc − p T ) j 0.9594 ± 0.0010 25.6 ± 1.4 2 hardest jets v ( t j ) 0.9606 ± 0.0011 21.1 ± 1.1 v ( t j ), h jet( k t ) j 0.9866 ± 0.0007 156.9 ± 14.8 v ( t j ), h jet(desc − p T ) j 0.9875 ± 0.0006 174.5 ± 14.0 5 hardest jets v ( t j ) 0.9576 ± 0.0019 20.3 ± 0.9 v ( t j ), h jet( k t ) j 0.9867 ± 0.0004 152.8 ± 10.4 v ( t j ), h jet(desc − p T ) j 0.9872 ± 0.0003 167.8 ± 9.5 No jet clustering, desc- p T on v i i = 1 0.6501 ± 0.0023 1.7 ± 0.0 i = 1 , . . . , 50 0.8925 ± 0.0079 5.6 ± 0.5 i = 1 , . . . , 100 0.8781 ± 0.0180 4.9 ± 0.6 i = 1 , . . . , 200 0.8846 ± 0.0091 5.2 ± 0.5 i = 1 , . . . , 400 0.8780 ± 0.0132 4.9 ± 0.5 op erating at the hadron-level for all the particles in an ev en t, in a wa y motiv ated in its structure b y QCD. 7 Related work Neural net w orks in particle ph ysics ha v e a long history . They ha v e been used in the past for many tasks, including early work on quark-gluon discrimination [ 28 , 29 ], particle iden tification [ 30 ], Higgs tagging [ 31 ] or trac k identification [ 32 ]. In most of these, neural net w orks app ear as shallow multi-la y er p erceptrons where input features w ere designed b y exp erts to incorp orate domain knowledge. More recen tly , the success of deep conv olutional net w orks has triggered a new b o dy of w ork in jet ph ysics, shifting the paradigm from engineering input features to learning them automatically from ra w data, e.g., as in these w orks treating jets as images [ 1 – 8 ]. Our w ork builds instead upon an analogy b et w een QCD and natural languages, hence complemen ting the set of algorithms for jet ph ysics with techniques initially developed for natural language pro cessing [ 9 – 14 ]. In addition, our approac h do es not delegate the full mo deling task to the machine. It allows to incorp orate domain kno wledge in terms of the net w ork arc hitecture, sp ecifically by structuring the recursion stac k for the embedding directly from QCD-inspired jet algorithms (see Sec. 3 ) – 14 – 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Signal efficiency 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 1 / Background efficiency 1 j e t 2 j e t s 5 j e t s Figure 5 . Ev en t classification performance of the RNN classifier when v arying the maxim um n um b er of jets given as input to the GRU. This plots shows there is significant improv emen t from going to the hardest to the 2 hardest jets, while there is no to little gain in considering more jets. Bet w een the time that this work app eared on the arXiv preprint server and submitted for publication there has b een a flurry of activity connecting deep learning tec hniques and jet ph ysics (for reviews see Refs.[ 33 – 35 ]). In particular the method describ ed here w as also used for quark/gluon tagging in Ref. [ 36 ] and a v ariant of this metho d w as used to reconstruct a jet’s charge [ 37 ]. The authors of Ref. [ 38 ] used the tree structure defined b y the jet clustering history to define a substructure ordering scheme for use with a sequen tial recurren t neural netw ork. Going the opp osite direction, graph neural netw orks and mes- sage passing neural netw orks ha ve also been applied to the the same jet-level classification problem and data described in this work [ 39 ]. There has also b een a spate of recent work on using QCD-inspired v ariables, enforcing physical constraints into neural netw orks, and en- suring infrared safety of neural net w ork based approac hes to jet ph ysics [ 40 – 44 ]. Exploring a compleme n tary direction, several authors ha v e developed wa ys to train machine learning tec hniques using real data to a void sensitivit y to systematic effects in the simulation [ 45 – 48 ]. These recen t training techniques are agnostic to the net w ork arc hitecture and can b e paired with the RNN arc hitectures describ ed here. Finally , deep learning tec hniques are no w b eing studied as generative models for jets, where the tree-based mo del mimics the parton sho wer and can be trained on real data [ 49 ]. Learning generativ e modes for both signal and background classes of jets can b e used to define a clas sifier in which eac h branc h of the tree can be interpreted as a contribution to a lik eliho o d ratio discriminan t [ 49 ]. – 15 – 8 Conclusions Building up on an analogy betw een QCD and natural languages, we ha v e presented in this w ork a nov el class of recursive neural netw orks for jet ph ysics that are deriv ed from sequen tial recom bination jet algorithms. Our exp erimen ts ha ve revealed that preprocessing steps applied to jet images during their construction (specifically the pixelisation) loses information, which impacts classification p erformance. By contrast, our recursive netw ork is able to work directly with the four-momen ta of a v ariable-length s et of particles, without the loss of information due to discretization into pixels. Our exp eriments indicate that this results in significant gains in terms of accuracy and data efficiency with resp ect to previous image-based netw orks. Finally , we also sho w ed for the first time a hierarchical, ev en t-lev el classification model op erating on all the hadrons of an even t. Notably , our results sho w ed that incorp orating domain kno wledge derived from jet algorithms and encapsulated in terms of the net w ork arc hitecture led to impro ved classification p erformance. While w e initially exp ected recursiv e net w orks operating on jet recombination trees to outp erform simpler p T -ordered arc hitectures, our results still clearly indicate that the top ology has an effect on the final p erformance of the classifier. How ever, our initial studies indicate that arc hitectures based on jet trees are more robust to infrared radiation and collinear splittings than the simpler p T -ordered arc hitectures, which may out weigh what at face v alue app ears to b e a small loss in p erformance. Accordingly , it w ould b e natural to include robustness to pileup, infrared radiation, and collinear splittings directly in the training pro cedure [ 27 ]. Moreo v er, it is comp elling to think of generalizations in whic h the optimization w ould include the top ology used for the em b edding as learnable comp onen t instead of considering it fixed a priori. An immediate challenge of this approac h is that a discontin uous c hange in the top ology (e.g., from v arying α or R ) mak es the loss non-differen tiable and rules out standard back propagation optimization algorithms. Nev ertheless, solutions for learning composition orders ha ve recently b een prop osed in NLP , using either explicit supervision [ 50 ] or reinforcement learning [ 51 ]; b oth of whic h could certainly b e adapted to jet embeddings. Another promising generalization is to use a graph-conv olutional netw ork that op erates on a graph where the vertices corresp ond to particle 4-momen ta v i and the edge weigh ts are given by d α ii 0 or a similar QCD-motiv ated quan tit y [ 39 , 52 – 58 ]. In conclusion, we feel confident that there is great p otential in hybrid tec hniques lik e this that incorp orate physics knowledge and leverage the p ow er of machine learning. Ac kno wledgments W e would lik e to thank the authors of Ref.[ 6 ] for sharing the data used in their studies and No el Da we in particular for his resp onsiveness in clarifying details ab out their work. W e w ould also like to thank Joan Bruna for enlightening discussions ab out graph-con volutional net w orks. Cranmer and Louppe are both supp orted through NSF A CI-1450310, addition- ally Cranmer and Becot are supp orted through PHY-1505463 and PHY-1205376. – 16 – References [1] J. Cogan, M. Kagan, E. Strauss and A. Sc h warztman, Jet-Images: Computer Vision Inspir e d T e chniques for Jet T agging , JHEP 02 (2015) 118 [ 1407.5675 ]. [2] L. de Oliveira, M. Kagan, L. Mack ey , B. Nac hman and A. Sch w artzman, Jet-Images – De ep L e arning Edition , 1511.05190 . [3] L. G. Almeida, M. Back ovi ´ c, M. Cliche, S. J. Lee and M. Perelstein, Playing T ag with ANN: Bo oste d T op Identific ation with Pattern R e c o gnition , JHEP 07 (2015) 086 [ 1501.05968 ]. [4] P . Baldi, K. Bauer, C. Eng, P . Sadowski and D. Whiteson, Jet Substructur e Classific ation in High-Ener gy Physics with De ep Neur al Networks , 1603.09349 . [5] D. Guest, J. Collado, P . Baldi, S.-C. Hsu, G. Urban and D. Whiteson, Jet Flavor Classific ation in High-Ener gy Physics with De ep Neur al Networks , Phys. R ev. D94 (2016) 112002 [ 1607.08633 ]. [6] J. Barnard, E. N. Daw e, M. J. Dolan and N. Ra jcic, Parton Shower Unc ertainties in Jet Substructur e A nalyses with De ep Neur al Networks , 1609.00607 . [7] P . T. Komiske, E. M. Meto diev and M. D. Sch w artz, De ep le arning in c olor: towar ds automate d quark/gluon jet discrimination , JHEP 01 (2017) 110 [ 1612.01551 ]. [8] G. Kasieczk a, T. Plehn, M. Russell and T. Schell, De ep-le arning T op T aggers or The End of QCD? , 1701.08784 . [9] C. Goller and A. Kuchler, L e arning task-dep endent distribute d r epr esentations by b ackpr op agation thr ough structur e , in Neur al Networks, 1996., IEEE International Confer enc e on , vol. 1, pp. 347–352, IEEE, 1996. [10] R. So cher, C. C. Lin, C. Manning and A. Y. Ng, Parsing natur al sc enes and natur al language with r e cursive neur al networks , in Pr o c e e dings of the 28th international c onfer enc e on machine le arning (ICML-11) , pp. 129–136, 2011. [11] R. So cher, J. Pennington, E. H. Huang, A. Y. Ng and C. D. Manning, Semi-sup ervise d r e cursive auto enc o ders for pr e dicting sentiment distributions , in Pr o c e e dings of the Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing , pp. 151–161, Asso ciation for Computational Linguistics, 2011. [12] K. Cho, B. v an Merri¨ en b o er, D. Bahdanau and Y. Bengio, On the pr op erties of neur al machine tr anslation: Enc o der-de c o der appr o aches , arXiv pr eprint arXiv:1409.1259 (2014) . [13] K. Cho, B. V an Merri¨ en b oer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Sch wenk et al., L e arning phr ase r epr esentations using rnn enc o der-de c o der for statistic al machine tr anslation , arXiv pr eprint arXiv:1406.1078 (2014) . [14] X. Chen, X. Qiu, C. Zh u, S. W u and X. Huang, Sentenc e mo deling with gate d r e cursive neur al network , in Pr o c e e dings of the 2015 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing , pp. 793–798, 2015. [15] I. Go o dfellow, Y. Bengio and A. Courville, De ep L e arning , c h. 10. MIT Press, 2016. [16] M. Cacciari, G. P . Salam and G. So yez, The Anti-k(t) jet clustering algorithm , JHEP 04 (2008) 063 [ 0802.1189 ]. [17] G. P . Salam, T owar ds Jeto gr aphy , Eur. Phys. J. C67 (2010) 637 [ 0906.1833 ]. – 17 – [18] V. Nair and G. E. Hin ton, R e ctifie d line ar units impr ove r estricte d b oltzmann machines , in Pr o c e e dings of the 27th international c onfer enc e on machine le arning (ICML-10) , pp. 807–814, 2010. [19] N. Fischer, S. Prestel, M. Ritzmann and P . Sk ands, Vincia for Hadr on Col liders , 1605.06142 . [20] M. Ritzmann, D. A. Kosow er and P . Sk ands, Antenna Showers with Hadr onic Initial States , Phys. L ett. B718 (2013) 1345 [ 1210.6345 ]. [21] J. Chung, C. Gulcehre, K. Cho and Y. Bengio, Empiric al evaluation of gate d r e curr ent neur al networks on se quenc e mo deling , arXiv pr eprint arXiv:1412.3555 (2014) . [22] D. Kingma and J. Ba, A dam: A metho d for sto chastic optimization , arXiv pr eprint arXiv:1412.6980 (2014) . [23] J. Thaler and K. V an Tilburg, Identifying Bo oste d Obje cts with N-subjettiness , JHEP 03 (2011) 015 [ 1011.2268 ]. [24] S. R. Bowman, C. D. Manning and C. Potts, T r e e-structur e d c omp osition in neur al networks without tr e e-structur e d ar chite ctur es , arXiv pr eprint arXiv:1506.04834 (2015) . [25] S. R. Bowman, Mo deling natur al language semantics in le arne d r epr esentations , Ph.D. thesis, ST ANFORD UNIVERSITY, 2016. [26] X. Shi, I. Padhi and K. Knight, Do es string-b ase d neur al mt le arn sour c e syntax? , in Pr o c. of EMNLP , 2016. [27] G. Loupp e, M. Kagan and K. Cranmer, L e arning to Pivot with A dversarial Networks , arXiv pr eprint arXiv:1611.01046 (2016) . [28] L. Lonnblad, C. Peterson and T. Rognv aldsson, Finding Gluon Jets With a Neur al T rigger , Phys. R ev. L ett. 65 (1990) 1321 . [29] L. Lonnblad, C. Peterson and T. Rognv aldsson, Using neur al networks to identify jets , Nucl. Phys. B349 (1991) 675 . [30] R. Sinkus and T. V oss, Particle identific ation with neur al networks using a r otational invariant moment r epr esentation , Nucl. Instrum. Meth. A391 (1997) 360 . [31] P . Chiapp etta, P . Colangelo, P . De F elice, G. Nardulli and G. P asquariello, Higgs se ar ch by neur al networks at LHC , Phys. L ett. B322 (1994) 219 [ hep-ph/9401343 ]. [32] B. H. Denb y , Neur al Networks and Cel lular A utomata in Exp erimental High-ener gy Physics , Comput. Phys. Commun. 49 (1988) 429 . [33] A. J. Larkoski, I. Moult and B. Nachman, Jet Substructur e at the L ar ge Hadr on Col lider: A R eview of R e c ent A dvanc es in The ory and Machine L e arning , 1709.04464 . [34] D. Guest, K. Cranmer and D. Whiteson, De ep L e arning and its Applic ation to LHC Physics , 1806.11484 . [35] M. Russell, T op quark physics in the L ar ge Hadr on Col lider er a , Ph.D. thesis, Glasgow U., 2017. 1709.10508 . [36] T. Cheng, R e cursive Neur al Networks in Quark/Gluon T agging , Comput. Softw. Big Sci. 2 (2018) 3 [ 1711.02633 ]. [37] K. F raser and M. D. Sch wartz, Jet Char ge and Machine L e arning , 1803.08066 . – 18 – [38] S. Egan, W. F edork o, A. Lister, J. Peark es and C. Gay , L ong Short-T erm Memory (LSTM) networks with jet c onstituents for b o oste d top tagging at the LHC , 1711.09059 . [39] I. Henrion, K. Cranmer, J. Bruna, K. Cho, J. Brehmer, G. Loupp e et al., Neur al Message Passing for Jet Physics , in Pr o c e e dings of the De ep L e arning for Physic al Scienc es Workshop at NIPS (2017) , 2017, https://dl4ph ysicalsciences.gith ub.io/files/nips dlps 2017 29.p df . [40] A. Butter, G. Kasieczk a, T. Plehn and M. Russell, De ep-le arne d T op T agging with a L or entz L ayer , 1707.08966 . [41] K. Datta and A. J. Lark oski, Novel Jet Observables fr om Machine L e arning , JHEP 03 (2018) 086 [ 1710.01305 ]. [42] P . T. Komiske, E. M. Meto diev and J. Thaler, Ener gy flow p olynomials: A c omplete line ar b asis for jet substructur e , JHEP 04 (2018) 013 [ 1712.07124 ]. [43] S. H. Lim and M. M. No jiri, Sp e ctr al Analysis of Jet Substructur e with Neur al Network: Bo oste d Higgs Case , 1807.03312 . [44] S. Choi, S. J. Lee and M. Perelstein, Infr ar e d Safety of a Neur al-Net T op T agging A lgorithm , 1806.01263 . [45] E. M. Meto diev, B. Nachman and J. Thaler, Classific ation without lab els: L e arning fr om mixe d samples in high ener gy physics , JHEP 10 (2017) 174 [ 1708.02949 ]. [46] P . T. Komiske, E. M. Meto diev, B. Nac hman and M. D. Sch wartz, L e arning to Classify fr om Impur e Samples , 1801.10158 . [47] J. H. Collins, K. How e and B. Nachman, CWoL a Hunting: Extending the Bump Hunt with Machine L e arning , 1805.02664 . [48] R. T. D’Agnolo and A. W ulzer, L e arning New Physics fr om a Machine , 1806.02350 . [49] A. Andreassen, I. F eige, C. F ry e and M. D. Sch wartz, JUNIPR: a F r amework for Unsup ervise d Machine L e arning in Particle Physics , 1804.09720 . [50] S. R. Bowman, J. Gauthier, A. Rastogi, R. Gupta, C. D. Manning and C. Potts, A fast unifie d mo del for p arsing and sentenc e understanding , arXiv pr eprint (2016) . [51] D. Y ogatama, P . Blunsom, C. Dyer, E. Grefenstette and W. Ling, L e arning to c omp ose wor ds into sentenc es with r einfor c ement le arning , arXiv pr eprint arXiv:1611.09100 (2016) . [52] J. Bruna, W. Zaremba, A. Szlam and Y. LeCun, Sp e ctr al networks and lo c al ly c onne cte d networks on gr aphs , CoRR abs/1312.6203 (2013) . [53] M. Henaff, J. Bruna and Y. LeCun, De ep c onvolutional networks on gr aph-structur e d data , CoRR abs/1506.05163 (2015) . [54] Y. Li, D. T arlo w, M. Bro cksc hmidt and R. S. Zemel, Gate d gr aph se quenc e neur al networks , CoRR abs/1511.05493 (2015) . [55] M. Niep ert, M. Ahmed and K. Kutzko v, L e arning c onvolutional neur al networks for gr aphs , CoRR abs/1605.05273 (2016) . [56] M. Defferrard, X. Bresson and P . V andergheynst, Convolutional neur al networks on gr aphs with fast lo c alize d sp e ctr al filtering , CoRR abs/1606.09375 (2016) . [57] T. N. Kipf and M. W elling, Semi-sup ervise d classific ation with gr aph c onvolutional networks , arXiv pr eprint arXiv:1609.02907 (2016) . – 19 – [58] T. N. Kipf and M. W elling, Semi-sup ervise d classific ation with gr aph c onvolutional networks , CoRR abs/1609.02907 (2016) . [59] D. Maclaurin, D. Duvenaud, M. Johnson and R. P . Adams, “Autograd: Rev erse-mo de differen tiation of native Python.” http://github.com/HIPS/autograd , 2015. A Gated recursive jet em b edding The recursive activ ation prop osed in Sec. 3.1 suffers from tw o critical issues. First, it assumes that left-child, right-c hild and local node information h jet k L , h jet k R , u k are all equally relev ant for computing the new activ ation, while only some of this information ma y b e needed and selected. Second, it forces information to pass through several levels of non- linearities and does not allow to propagate unc hanged from lea v es to root. Addressing these issues and generalizing from [ 12 – 14 ], we recursively define a recursive activ ation equipp ed with reset and up date gates as follo ws: h jet k = u k if k is a leaf z H ˜ h jet k + z L h jet k L + otherwise → z R h jet k R + z N u k (A.1) u k = σ ( W u g ( o k ) + b u ) (A.2) o k = ( v i ( k ) if k is a leaf o k L + o k R otherwise (A.3) ˜ h jet k = σ W ˜ h r L h jet k L r R h jet k R r N u k + b ˜ h (A.4) z H z L z R z N = softmax W z ˜ h jet k h jet k L h jet k R u k + b z (A.5) r L r R r N = sigmoid W r h jet k L h jet k R u k + b r (A.6) where W ˜ h ∈ R q × 3 q , b ˜ h ∈ R q , W z ∈ R q × 4 q , b z ∈ R q , W r ∈ R q × 3 q , b r ∈ R q , W u ∈ R q × 4 and b u ∈ R q form together the shared parameters to be learned, σ is the ReLU activ ation function and denotes the element-wise multiplication. In tuitiv ely , the reset gates r L , r R and r N con trol how to actively select and then merge the left-c hild embedding h jet k L , the right-c hild embedding h jet k R and the local no de information u k to form a new candidate activ ation ˜ h jet k . The final embedding h jet k can then b e regarded as a c hoice among the candidate activ ation, the left-child em b edding, the righ t-c hild em b edding and the local no de information, as con trolled b y the up date gates – 20 – z H , z L , z R and z N . Finally , let us note that the prop osed gated recursiv e em b edding is a generalization of Section 3.1 , in the sense that the later corresp onds to the case where up date gates are set to z H = 1, z L = 0, z R = 0 and z N = 0 and reset gates to r L = 1, r R = 1 and r N = 1 for all no des k . B Gated recurrent ev en t embedding In this section, we formally define the gated recurrent even t embedding in troduced in Sec. 3.2 . Our ev ent embedding function is a GRU [ 21 ] operating on the p T ordered sequence of pairs ( v ( t j ) , h jet 1 ( t j )), for j = 1 , . . . , M , where v ( t j ) is the unpro cessed 4-momen tum ( φ, η , p T , m ) of the jet t j and h jet 1 ( t j ) is its embedding. Its final output h even t j = M is recursively defined as follows: h even t j = z j h even t j − 1 + (1 − z j ) ˜ h even t j (B.1) ˜ h even t j = σ W hx x j + W hh ( r j h even t j − 1 ) + b h (B.2) x j = " v ( t j ) h jet 1 ( t j ) # (B.3) z j = sigmoid W z x x j + W z h h even t j − 1 + b z (B.4) r j = sigmoid W rx x j + W rh h even t j − 1 + b r (B.5) where W hx ∈ R r × 4+ q , W hh ∈ R r × r , b h ∈ R r , W rx ∈ R r × 4+ q , W rh ∈ R r × r , b r ∈ R r , W z x ∈ R r × 4+ q , W z h R r × r and b z ∈ R r are the parameters of the embedding function, r is the size of the embedding, σ is the ReLU activ ation function, and h even t 0 = 0. In the exp erimen ts of Sec. 6 , only the 1, 2 or 5 hardest jets are considered in the sequence j = 1 , . . . , M , as ordered by ascending v alues of p T . C Implemen tation details While tree-structured net works app ear to b e a principled c hoice in natural language pro- cessing, they often ha ve b een ov erlo oked in fav or of sequence-based net works on the accoun t of their tec hnical incompatibilit y with batc h computation [ 50 ]. Because tree-structured net w orks use a differen t top ology for eac h example, batc hing is indeed often imp ossible in standard implementations, whic h preven ts them from b eing trained efficiently on large datasets. F or this reason, the recursive jet embedding w e in tro duced in Sec. 3.1 w ould undergo the same tec hnical issues if not implemen ted with caution. In our implemen tation, w e achiev e batch computation b y noticing that activ ations from a same level in a recursive binary tree can b e p erformed all at once, provided all nec- essary computations from the deeper lev els ha v e already been p erformed. This principle extends to the sync hronized computation across multiple trees, which enables the batch computation of our jet em b eddings across many ev ents. More sp ecifically , the computation of jet em beddings is preceded b y a trav ersal of the recursion trees for all jets in the batch, and whose purp ose is to unroll and regroup computations b y their level of recursion. Em- b eddings are then reconstructed lev el-wise in batc h, in a b ottom-up fashion, starting from the deepest lev el of recursion across all trees. – 21 – Finally , learning is carried out through gradien ts obtained b y the automatic differ- en tiation of the full mo del chain on a batc h of ev en ts (i.e., the recursive computation of jet em b eddings, the sequence-based recurrence to form the even t embeddings, and the for- w ard pass through the classifier). The implemen tation is written in nativ e Python co de and mak es use of Autograd [ 59 ] for the easy deriv ation of the gradien ts o ver dynamic structures. Co de is av ailable at 2 under BSD license for further technical details. 2 https://github.com/glouppe/recnn – 22 –
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment