How to Evaluate Solutions in Pareto-based Search-Based Software Engineering? A Critical Review and Methodological Guidance
💡 Research Summary
The paper addresses a fundamental challenge in Search‑Based Software Engineering (SBSE): how to evaluate the quality of solution sets produced by Pareto‑based multi‑objective optimization. While multi‑objective problems are increasingly common in software engineering, the resulting nondominated solution sets cannot be compared directly by simple dominance relations, making evaluation non‑trivial.
To uncover current practices and shortcomings, the authors performed a systematic literature review covering the period 2009‑2019. They retrieved 3,156 records from 36 venues across seven repositories, removed duplicates, and applied two rounds of title/abstract screening, yielding 717 unique papers. An iterative forward snowballing process further narrowed the pool to 95 primary studies that explicitly dealt with Pareto‑based SBSE evaluation. The review was guided by three research questions: (RQ1) which evaluation methods are used, (RQ2) why generic quality indicators are chosen and how they are applied, and (RQ3) in which domains and contexts these methods appear.
The analysis revealed that SBSE researchers commonly rely on three categories of evaluation: (1) visualisation (scatter plots) which is limited to bi‑objective cases, (2) descriptive statistics (best, mean, median per objective) which can be misleading when decision‑maker (DM) preferences are not aligned, and (3) generic quality indicators such as Hypervolume (HV) and Inverted Generational Distance (IGD). The authors identified five critical issues that pervade the literature: (i) over‑reliance on visualisation despite high‑dimensional objectives, (ii) misuse of single‑objective statistics that ignore trade‑offs, (iii) application of indicators that require a known Pareto front (e.g., IGD) even when such a reference set is unavailable, (iv) neglect of DM preferences and problem‑specific nature when selecting indicators, and (v) lack of clear understanding of what each indicator actually measures, leading to ambiguous or contradictory results.
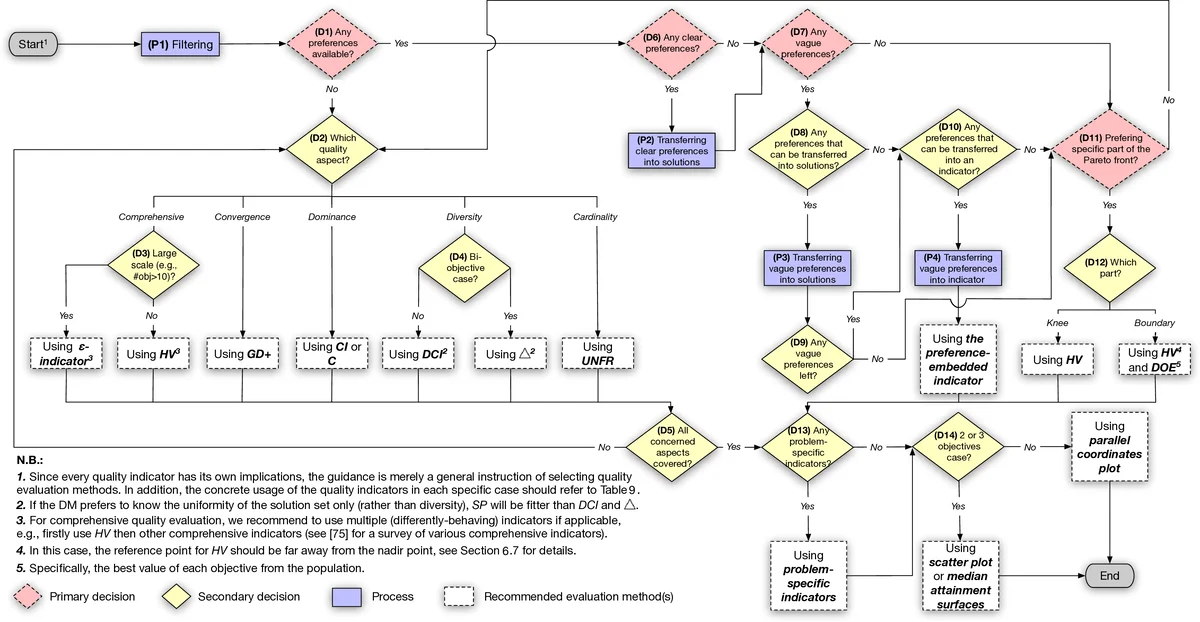
To address these gaps, the paper provides a thorough taxonomy of quality indicators based on four quality aspects widely recognised in multi‑objective optimisation: convergence (closeness to the true Pareto front), spread (extent of the covered region), uniformity (evenness of distribution), and cardinality (number of nondominated solutions). Indicators are mapped to these aspects, revealing that HV favours convergence and knee‑region solutions, IGD emphasises uniform coverage, Spread and Epsilon focus on diversity, while R2 and other scalarising‑based metrics can incorporate DM‑specified weightings. The authors also discuss practical concerns such as the selection of reference points for HV and the construction of surrogate reference fronts when the true front is unknown.
Building on this analysis, the authors propose a methodological guidance for SBSE practitioners. The guidance consists of five steps: (1) explicitly elicit or infer DM preferences and problem characteristics (e.g., whether a particular objective is dominant), (2) decide which quality aspects are most relevant for the specific scenario, (3) select indicators that align with the chosen aspects and respect the DM’s preferences, (4) configure indicator parameters (reference points, reference sets) in a way that reflects the problem’s scale and objectives, and (5) combine multiple indicators when necessary, interpreting results in a coherent manner (e.g., using HV for convergence and Spread for diversity, then analysing knee points for DM relevance). The paper illustrates the application of this workflow on typical SBSE problems such as software product line configuration, test case generation, and performance‑energy trade‑offs, showing how inappropriate indicator choices can lead to solutions that violate domain constraints (e.g., invalid product configurations) or ignore critical preferences (e.g., always preferring full coverage over cost).
Finally, the authors discuss threats to validity, including potential bias in paper selection, the limited time window, and the difficulty of modelling DM preferences quantitatively. They compare their work with recent empirical guideline efforts, arguing that a theory‑driven, preference‑aware approach offers broader applicability across domains.
In summary, this paper delivers the first systematic, theory‑backed review of solution‑set evaluation in Pareto‑based SBSE, identifies pervasive methodological flaws, analyses the strengths and limitations of existing quality indicators, and furnishes a practical, step‑by‑step guidance for selecting and configuring evaluation methods that respect both the technical characteristics of the optimisation problem and the nuanced preferences of the decision maker.
Comments & Academic Discussion
Loading comments...
Leave a Comment