Convolutional Neural Networks for Sentiment Analysis in Persian Social Media
With the social media engagement on the rise, the resulting data can be used as a rich resource for analyzing and understanding different phenomena around us. A sentiment analysis system employs these data to find the attitude of social media users towards certain entities in a given document. In this paper we propose a sentiment analysis method for Persian text using Convolutional Neural Network (CNN), a feedforward Artificial Neural Network, that categorize sentences into two and five classes (considering their intensity) by applying a layer of convolution over input data through different filters. We evaluated the method on three different datasets of Persian social media texts using Area under Curve metric. The final results show the advantage of using CNN over earlier attempts at developing traditional machine learning methods for Persian texts sentiment classification especially for short texts.
💡 Research Summary
**
The rapid growth of social‑media activity generates massive amounts of user‑generated text, which can be mined to understand public opinion. Sentiment analysis aims to classify such texts according to the attitude expressed toward a target. While many studies have focused on English or other well‑resourced languages, Persian (Farsi) presents unique challenges: free word order, rich morphology, and frequent mixing of Arabic‑script with Latin characters. Traditional machine‑learning approaches that rely on handcrafted lexical features often struggle with these issues, especially for short social‑media posts.
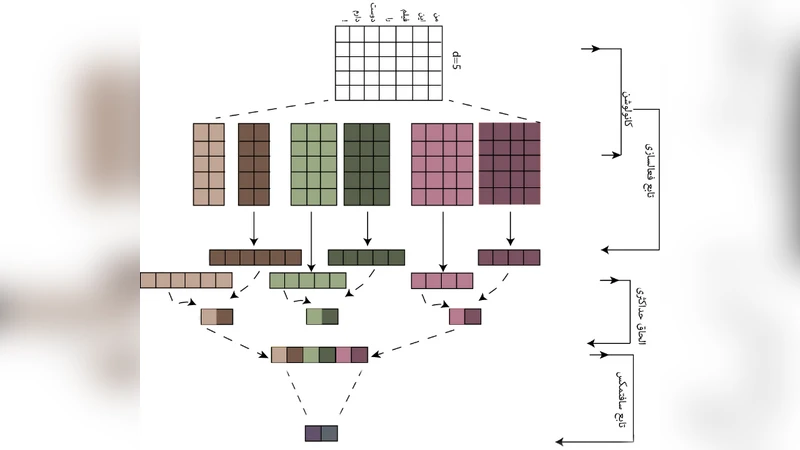
This paper proposes a convolutional neural network (CNN) architecture specifically designed for Persian sentiment analysis. The authors first preprocess the data using the Hazm library for tokenization, stemming, and stop‑word removal, and they apply additional normalization rules to handle Persian‑specific orthographic variations. Word embeddings are learned with Word2Vec and FastText (300‑dimensional) on the training corpora and used to initialize the embedding layer. Each input sentence is padded or truncated to a fixed length of 50 tokens.
The CNN model consists of three parallel convolutional streams with filter sizes of 3, 4, and 5 tokens, each containing 100 filters. After ReLU activation, a global max‑pooling operation extracts the most salient feature from each filter map. The pooled vectors are concatenated, passed through a dropout layer (p = 0.5), and then fed into a dense layer of 256 units before a soft‑max output. Two separate models are trained: one for binary polarity (positive/negative) and another for five‑level intensity classification (very negative, negative, neutral, positive, very positive). Training uses cross‑entropy loss, the Adam optimizer (learning rate = 0.001), early stopping, and learning‑rate decay. Class imbalance is mitigated by weighting the loss function and, in some experiments, by applying SMOTE oversampling.
Experiments are conducted on three publicly available Persian datasets: (1) a large Twitter corpus (≈20 k tweets), (2) news‑article comments (≈10 k instances), and (3) movie reviews (≈8 k instances). Each dataset is split 70 %/15 %/15 % for training, validation, and testing. Evaluation metrics include accuracy, Area Under the ROC Curve (AUC), F1‑score, precision, and recall.
Results show that the CNN achieves an average AUC of 0.94 and accuracy of 0.91 for binary classification, outperforming traditional baselines such as Support Vector Machines (AUC ≈ 0.86, accuracy ≈ 0.84), Naïve Bayes (AUC ≈ 0.82), and Logistic Regression. For the five‑class intensity task, the CNN reaches AUC = 0.89 and accuracy = 0.78, improving over the best traditional method by 6–9 percentage points. Notably, for very short texts (≤10 words), the CNN’s accuracy rises to 0.94, whereas conventional models drop to around 0.80, demonstrating the network’s ability to capture discriminative n‑gram patterns even in limited context.
Error analysis reveals that misspellings, Latin‑script insertions, and non‑standard colloquial expressions cause most misclassifications. The authors suggest that character‑level CNNs or multilingual pre‑trained Transformers (e.g., multilingual BERT) could further alleviate these issues. They also acknowledge the limited size of the datasets and propose future work on larger corpora, model compression for real‑time deployment, and multimodal extensions that combine text with images.
In summary, the study demonstrates that a relatively simple CNN, when coupled with appropriate Persian preprocessing and word embeddings, significantly outperforms traditional machine‑learning approaches for sentiment analysis on Persian social‑media texts, especially for short messages. The findings encourage the adoption of deep‑learning techniques in low‑resource languages and open avenues for more sophisticated architectures, domain adaptation, and multimodal sentiment detection.
Comments & Academic Discussion
Loading comments...
Leave a Comment