Classification accuracy as a proxy for two sample testing
When data analysts train a classifier and check if its accuracy is significantly different from chance, they are implicitly performing a two-sample test. We investigate the statistical properties of this flexible approach in the high-dimensional setting. We prove two results that hold for all classifiers in any dimensions: if its true error remains $\epsilon$-better than chance for some $\epsilon>0$ as $d,n \to \infty$, then (a) the permutation-based test is consistent (has power approaching to one), (b) a computationally efficient test based on a Gaussian approximation of the null distribution is also consistent. To get a finer understanding of the rates of consistency, we study a specialized setting of distinguishing Gaussians with mean-difference $\delta$ and common (known or unknown) covariance $\Sigma$, when $d/n \to c \in (0,\infty)$. We study variants of Fisher’s linear discriminant analysis (LDA) such as “naive Bayes” in a nontrivial regime when $\epsilon \to 0$ (the Bayes classifier has true accuracy approaching 1/2), and contrast their power with corresponding variants of Hotelling’s test. Surprisingly, the expressions for their power match exactly in terms of $n,d,\delta,\Sigma$, and the LDA approach is only worse by a constant factor, achieving an asymptotic relative efficiency (ARE) of $1/\sqrt{\pi}$ for balanced samples. We also extend our results to high-dimensional elliptical distributions with finite kurtosis. Other results of independent interest include minimax lower bounds, and the optimality of Hotelling’s test when $d=o(n)$. Simulation results validate our theory, and we present practical takeaway messages along with natural open problems.
💡 Research Summary
The paper investigates a widely used but theoretically under‑explored practice: training a classifier on two groups of data, measuring its held‑out accuracy, and declaring a significant difference when the accuracy exceeds chance. The authors formalize this “accuracy‑based test” as a two‑sample hypothesis test and study its statistical properties in high‑dimensional regimes where both the sample size n and the dimension d grow to infinity.
The first set of results is completely general. For any classifier, any dimension, and any growth rate of d and n, the authors show that if the true classification error stays at least a fixed ε > 0 below the random‑guess level (i.e., true accuracy ≥ ½ + ε), then two concrete testing procedures are asymptotically consistent: (a) a permutation test that re‑labels the data and recomputes the accuracy, and (b) a computationally cheap test that approximates the null distribution of the accuracy by a Gaussian. Both procedures control the type‑I error at the nominal level and achieve power → 1 as n,d → ∞.
To understand the rate at which power approaches one, the authors focus on the canonical high‑dimensional two‑sample mean problem: two Gaussian populations with a common covariance Σ (known or unknown) and a mean difference δ, with d/n → c∈(0,∞). They analyze Fisher’s linear discriminant analysis (LDA) estimated via sample splitting. Under mild regularity conditions, the centered and rescaled classification error converges to a standard normal under both the null and local alternatives (Theorem 5.1). This yields an explicit asymptotic power formula (6.7). Remarkably, the same formula appears for the optimal Hotelling‑type tests (Bai‑Saranadasa, Srivastava‑Du). The only difference is a constant factor: the LDA‑based test has asymptotic relative efficiency (ARE) = 1/√π ≈ 0.564 for balanced samples. Thus, while it is uniformly less powerful than the optimal quadratic test, the loss is modest and does not affect consistency.
When Σ is unknown, the authors consider “naïve Bayes” and other linear classifiers that replace Σ by its diagonal. The same Gaussian limit holds, and the ARE remains 1/√π (Theorem 7.1). Hence the inefficiency is intrinsic to using a linear decision rule that does not fully exploit the covariance structure.
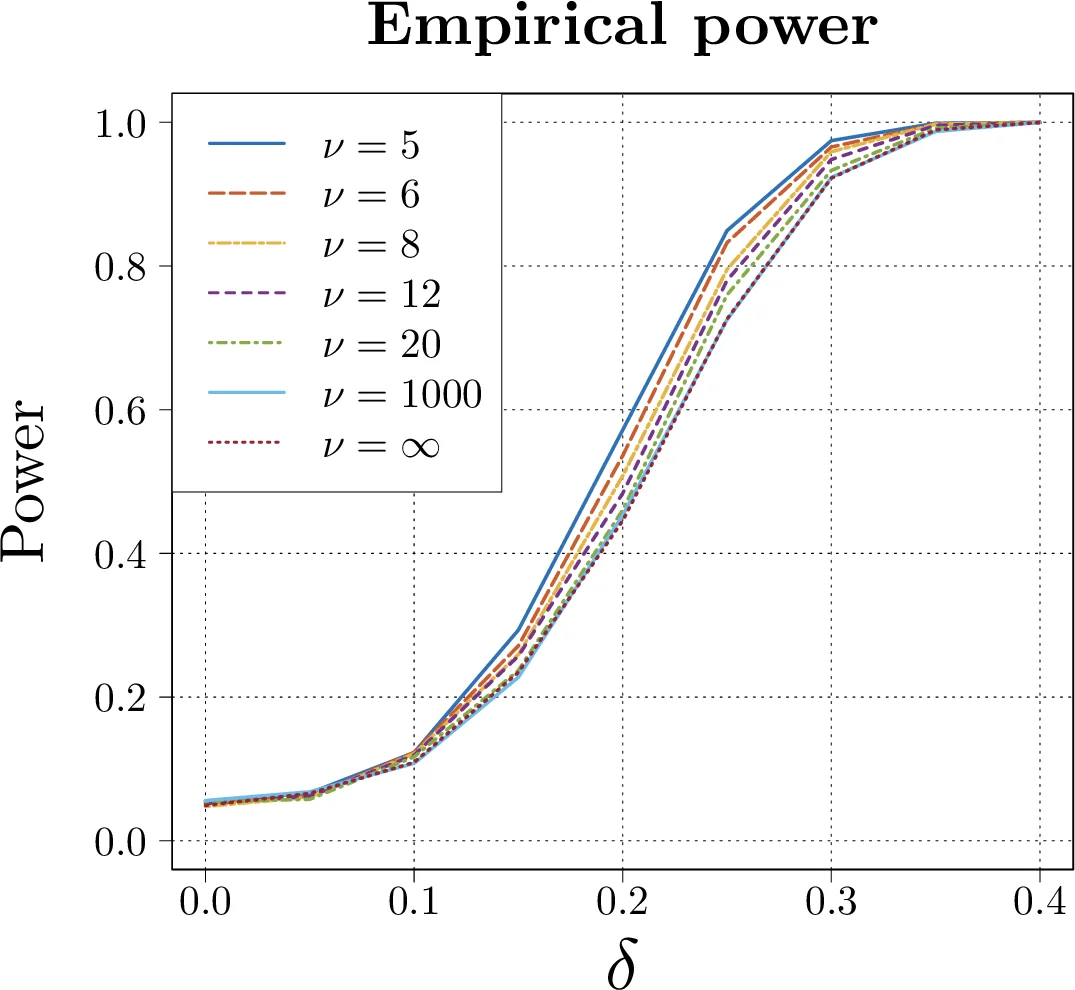
The analysis is further extended to elliptical distributions with finite kurtosis. The limiting power expression is identical up to a multiplicative constant √2 fX(0), where fX is the marginal density at zero. For multivariate t‑distributions, this constant can exceed one, implying that in heavy‑tailed settings the accuracy‑based test can even outperform Hotelling’s test.
Beyond power, the paper derives the exact asymptotic minimax power for high‑dimensional two‑sample mean testing (Proposition 3.1) and shows that Hotelling’s T² test attains this lower bound whenever d = o(n) (Theorem 4.1). This corrects the prevailing belief that Hotelling is powerless when d grows with n.
Simulation studies on Gaussian, t‑distributed, and real neuroimaging data confirm the theoretical predictions. The accuracy‑based tests track the derived power curves, and the constant‑factor loss relative to Hotelling is observed empirically.
Practical take‑aways are nuanced. If the data are scarce or the alternative hypothesis is hard to formalize, a flexible classifier (e.g., deep neural network, random forest) combined with an accuracy‑based test offers a reasonable, theoretically justified approach. Conversely, when abundant, well‑structured data are available and a tailored test statistic can be constructed, classical Hotelling‑type or graph‑based tests provide higher power.
In summary, the paper bridges machine‑learning practice and classical hypothesis testing, proving that classification accuracy can serve as a valid test statistic in high dimensions, quantifying its power loss, and offering guidance on when this approach is appropriate.
Comments & Academic Discussion
Loading comments...
Leave a Comment