Dense monocular Simultaneous Localization and Mapping by direct surfel optimization
This work presents a novel approach for monocular dense Simultaneous Localization and Mapping. The surface to be estimated is represented as a piecewise planar surface, defined as a group of surfels each having as parameters its position and normal. …
Authors: Emanuel Trabes, Julio Daniel Dondo Gazzano, Carlos Federico Sosa Paez
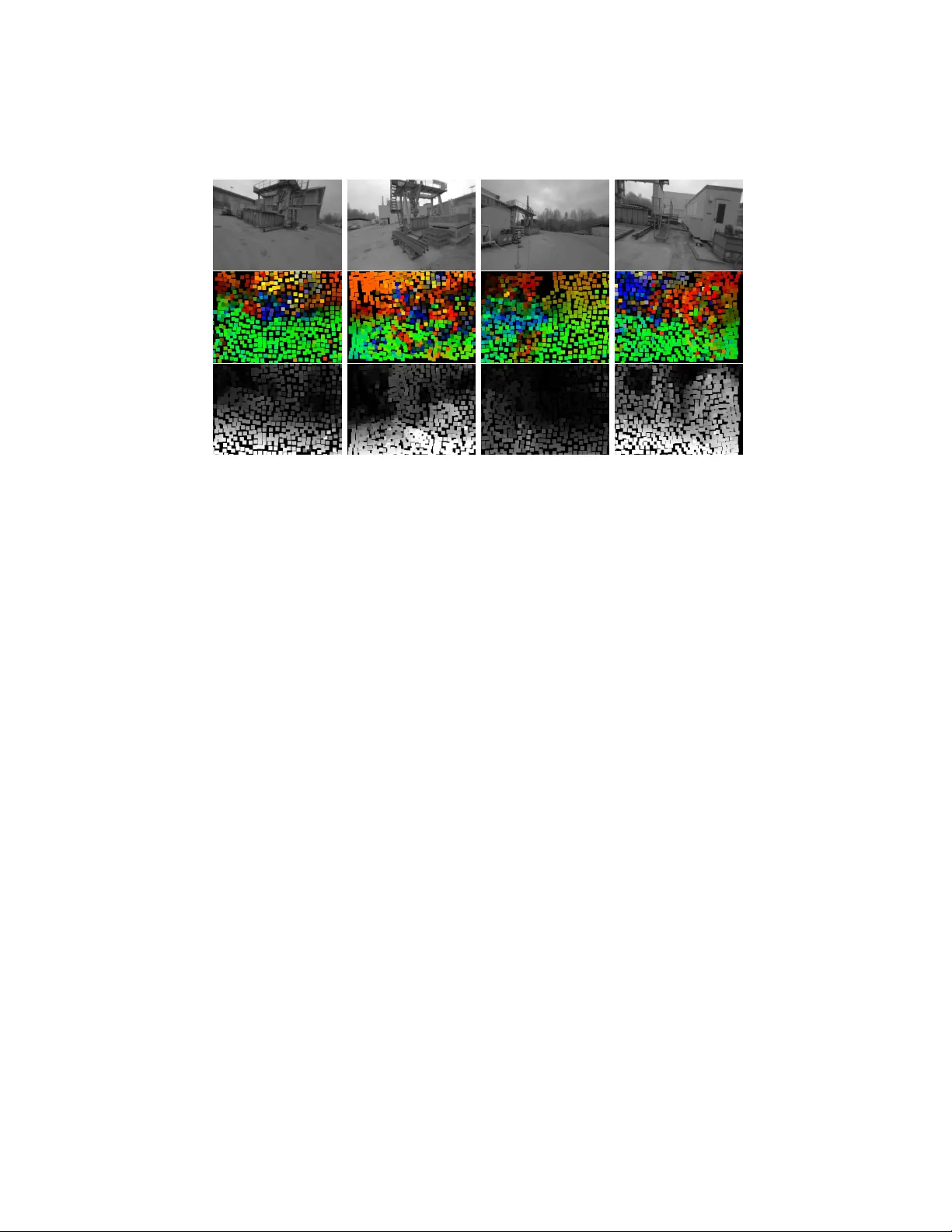
Dense mono cular Sim ultaneous Lo calization and Mapping b y direct surfel optimization Eman uel T rab es, Julio Daniel Dondo Gazzano, and Carlos F ederico Sosa P´ aez Departamen to de Electr´ onica Univ ersidad Nacional de San Luis, Argen tina Abstract. This w ork presents a no vel approac h for mono cular dense Sim ultaneous Lo calization and Mapping. The surface to b e estimated is represen ted as a piecewise planar surface, defined as a group of surfels eac h having as parameters its p osition and normal. These parameters are then directly estimated from the raw camera pixels measuremen ts, b y a Gauss-Newton iterative pro cess. As far as the authors know, this is the first time this approach is used for mono cular depth estimation. The represen tation of the surface as a group of surfels has sev eral adv an tages. It allo ws the reco very of robust and accurate pixel depths, without the need to use a computationally demanding depth regularization sc hema. This has the further adv an tage of a v oiding the use of a ph ysically unlikely surface smo othness prior. New surfels can b e correctly initialized from the information presen t in nearby surfels, av oiding also the need to use an exp ensiv e initialization routine commonly needed in Gauss-Newton metho ds. The method w as written in the GLSL shading language, al- lo wing the usage of GPGPU th us ac hieving real-time. The method was tested against sev eral datasets, showing b oth its depth and normal es- timation correctness, and its scene reconstruction qualit y . The results presen ted here show case the usefulness of the more physically grounded piecewise planar scene depth prior, instead of the more commonly pixel depth independence and smo othness prior. Keyw ords: Depth Estimation · Visual Odometry · SLAM. 1 In tro duction One of the most fundamental abilities that unmanned v ehicles must p osses is the capacit y for the estimation of its relative p osition within the exploration area. F urthermore, man y types of missions like resources detection and obstacle a voidance, require that the v ehicle must p osses a detailed map of its surrounding. One wa y to acquire such knowledge is by utilizing mapping metho ds, were a mo del of the nearb y terrain is recov ered from the measurements of the on-b oard sensors. It’s well kno wn in the literature that the problem of p ositioning and mapping are in terconnected, and b oth must b e solved sim ultaneously [6]. Systems that are capable of p osition estimation and mapping are known in the literatura as Simultaneous Lo calization and Mapping (SLAM) [2]. There is 2 T rab es et al. a wide c hoice in the t yp e of sensor that can b e utilized to accomplish the SLAM task. A very in teresting choice is the mono cular camera. This t yp e sensor can ha ve, with the current state of tec hnology , v ery large resolutions and also v ery high refresh rates. There are many SLAM systems curren tly present in the literature that suc- cessfully use a mono cular camera as the only sensor for resolving the SLAM problem. One example is LSD-SLAM [4], whic h uses an epip olar search approach together with a k alman filter for estimating the depth of some of the pixels of a frame tak en from a position of reference. The pixels that, due to lack of texture in the frame, cannot b e estimated accurately are detected and discarded, and its depths are not estimated. With the depth of the pixels and the p osition of the reference frame a lo cal map is constructed. in case of the frames taken in nearby p ositions, the information obtained from their relative p osition within the lo cal map is used to impro ve the reference frame pixels depth estimation. Another example is DSO [3], whic h tak es an even more restrictiv e approach with the selection of pixels to b e used for depth estimation. Only a very small p ercen tage of the pixels in the frame are used for depth estimation. The resulting map is a very sparse one, but the results in localizations are outstanding. Other w orks like ORB-SLAM [8] use a pre-pro cessing step on the captured frames, to iden tify the areas where robust depth estimation is more plausible. This pre- pro cessing utilizes a salience detector to filter the zones of the frame that are not well p osed for depth and p ose estimation. All of these metho ds do not try to reco ver a detailed map of the surrounding terrain, fo cusing its attention on correct p osition estimation. The usefulness of these metho ds in missions that require a detailed knowledge of the surrounding terrain is questionable. Other approaches, lik e DT AM [9] do try to estimate depth in every pixel. A brute force plane sw eeping approac h [7] in conjunction with a regularizer are used to accomplish this task. The system is still based on a pixel-wise epipolar search. And so, the estimation in areas in the frame where there is no texture is hea vily regularized with the depth of nearb y pixels, in order to reco ver somewhat correct depth estimations. REMODE [10] uses an epip olar depth search together with a probabilistic measuremen t merging, again with a regularization at the end of the pro cess. Zones in the frame where there is no texture m ust b e, again, hea vily regularized. The work of [14] tries to estimate a mesh from the frames taken from a monocular camera. The system utilizes first a plane sweeping metho d similar to [9] to estimate the depth, and then this information is used to optimize ev ery v ertex of the mesh. The use of a pixel-wise estimation metho d makes again the zones without texture difficult to estimate and it requires the use of a depth regularizer. It has b een lately recognized in the literature that the depth smo othness h yp otesis introduces a prior knowledge of the scene that many times is not accurate [3] [5]. A b etter prior hypothesis on the depth of the scene is desirable. A surfel representation for the depth estimation could p oten tially resolve these issues. This would replace the depth smoothness prior with a more plausible piecewise planar depth prior, preserving strong discontin uities commonly found Title Suppressed Due to Excessive Length 3 in man-made structures. Also, the representation of a part of the scene with the same paremeters could av oid the need for a regularizer. Man y w orks found in the literature hav e utilized surfels to represent the surface of the scene, but alwa ys using depth camera sensor lik e [11] [12][13]. This work presents a dense mono cular SLAM system that do es not utilizes the depth smo othness prior. This metho d accomplishes the map estimation task b y mo deling the map, not as a group of indep endent points, but as a group of surfels. This tak es adv an tage of the knowledge that the depth of most scenes can b e mo deled as a piecewise planar surface, instead of just a group of indep enden t pixels. Every piecewise p ortion of the scene can be estimated with a surfel. This approac h allo ws to directly recov er robust and accurate pixel depths, even in zones where there is no goo d texture observ ation. F urthermore, this approach a voids the need for a regularization step. This w a y we can sav e on computational resources and, more imp ortant, not add a physically unlikely smo othness prior. New surfels can b e initialized with the information of neighbor surfels. The en tire system w as written in the GLSL shading language, thus using the on b oard GPU to achiev e real-time. Results showing the p erformance of the metho ds are pro vided, demonstrating its scene reconstruction qualit y . 2 Prop osed Approac h 2.1 Surfel P arameterization Eac h surfel p osition p s and normal n s are defined relative to the p ose P kf ∈ S E (3) of a reference frame F kf . The surfels ha ve 3 free parameters, 2 b elonging to the degrees of freedom of its normal n s , and the other given by the inv erse depth id s of the ray r s going from the origin of the reference frame to p s , whose co ordinates are given by p s = r s /id s (1) The radius of the surfel r is selected so that all surfels hav e the same frame- space area in the reference frame F kf , regardless of its normal or depth. This is done so to assure the same quan tity of pixel observ ation for ev ery surfel, this w ay allo wing to gather enough information for the Gauss-Newton estimation process. Along with the aforementioned parameters, the last residual of each surfel and the time that the surfel w as last seen and up dated are stored for later use. 2.2 In verse Depth Calculation With the information provided by the estimated surfel parameters, the inv erse depth id u of every pixel u b elonging to the reference frame F kf can b e obtained. Ev ery u has a corresp onding ray r u with co ordinates r u = K − 1 π − 1 ( u ) (2) 4 T rab es et al. where K is the camera matrix, π () is the homogenizing function π ([ x, y , z ]) = [ x/z , y/z , 1] and u ∈ R 3 is a homogeneous pixel co ordinate relativ e to F kf . T o b e in the same plane, the p oin t p s and p u = r u /id u m ust satisfy n s ( p s − p u ) = 0, so id u is computed as id u = ( K − 1 π − 1 ( u )) · n s ( r s /id s ) · n s (3) The inv erse depth id u will b e calculated relativ e to a surfel s when the dis- tance b et ween u and the co ordinates of the surfel p s pro jected in to the frame F kf , u s = π ( K p s ), is less than the radius r of the surfel s in screen space, that is k π ( K p s ) − u k < r (4) The GLSL shading language is utilized for the implemen tation of the system, so it allows to seemingly introduce a depth buffer for o clution remov al. This means that, if sev eral surfel pro ject the same pixel screen lo cation, only the pixels with the closest depth to the camera are selected. During in verse depth computation, along with the depth information the index of the generating surfel s ind is sav ed, for subsequent utilization as describ ed b elo w. 2.3 Surfel Initialization T o initialize the surfels, the reference frame F kf ’s inv erse depth is computed. Clearly , in areas in the image where no surfel satisfy the equation 4, there will b e no in verse depth measuremen t. These areas are iden tified as potential lo cation to initialize a new surfel. First, a searc h is carried out for an empty pixel u ns where a new surfel can b e placed. This area m ust satisfy that there is no other inv erse depth measurement nearb y satisfying ∀ u nn , k u ns − u nn k > αr , where u nn is a non-empt y pixel. Then, all neigh b oring surfels are searched for. A neighbor surfel must sat- isfy that a corresp onding inv erse depth measurement pixel u s is nearb y , with a distance of less than k u ns − u s k < β r The inv erse depth for the new surfel is calculated as the mean of the estimated in verse depth, follo wing equation 3 with resp ect of all nearby surfels s . The normal of the new surfel is initialized as the mean of all neighboring surfel’s normal. In so far as the real surface is globally plane, this t yp e of initialization will giv e goo d results. This allows to initialize the surfel with the approximate correct surfel normal and depth, which allo ws to initialize the Gauss-Newton optimiza- tion, without the need to search for surfel initializing parameters. Title Suppressed Due to Excessive Length 5 2.4 Surfel Optimization The parameters of the surfels are estimated so that they minimize the cost function: C ( n s , id s ) = X n ∈ Ω X u ∈ s k I f n ( u p ( n s , id s )) − I kf ( u ) k h (5) whic h is the commonly used sum of the huber normed photometric error [9] [10] [3] b etw een the reference frame intensit y I kf and every frame I f n in a group Ω of frames tak en b efore I f n . The co ordinates u p of the pixel u as seen from the frame I f n can b e calculated with u p ( n s , id s ) = π − 1 ( K P f n kf K − 1 π ( u ) /id u ( n s , id s )) (6) where P f n kf ∈ S E (3) c hanges a p oin t p in the k eyframe reference frame to the frame f n reference frame. T o recov er the parameters of each surfel [ n s , id s ] that minimizes C ([ n s , id s ]) , a Leven b er-Marquat [3] Gauss-Newton optimization approac h is implemen ted. The Jacobian ∂ C [ n s ,d s ] ∂ [ n s ,d s ] is obtained b y using the c hain rule for deriv ativ es: J = X n ∈ Ω ∂ C ([ n s , d s ]) ∂ id u ∂ id u ∂ [ n s , d s ] (7) C ([ n s ,d s ]) ∂ id u can b e further expressed as C ([ n s , d s ]) ∂ id u = X n ∈ Ω ∂ C ([ n s , d s ]) ∂ I f ∇ I f n ( up ) ∂ π ( u ) ∂ u ∂ u p ∂ id u (8) where ∂ C ([ n s ,d s ]) ∂ I f = w ( I f n ( u p ) − I kf ( u )), w b eing the Hub er norm co efficien t correction to the squared norm, ∇ I f n is the gradient of the frame f n , ∂ π ( u ) ∂ u = 1 0 − u y 0 1 − u y 0 0 0 and ∂ u p ∂ id u = K R f n kf K − 1 π − 1 ( u ), where R f n kf is the relativ e rotation b et w een the co ordinate frames P kf and P f n . F urthermore, ∂ id u ∂ [ n s ,d s ] can b e expressed as ∂ id u ∂ n s = r s /id s K − 1 π − 1 ( u ) · n s − ( r s /id s ) K − 1 π − 1 ( u ) · n s ( K − 1 π − 1 ( u ) · n s ) 2 ∂ id u ∂ id s = K − 1 π − 1 ( u ) · n s r s · n s (9) As ∂ id u ∂ [ n s ,d s ] do es not dep end up on I f n or its p ose P f n kf , it can b e tak en out of the sum and computed only once for all I f n ∈ Ω , which allo ws to reduce the computational burden of the GPU. 6 T rab es et al. Notice that ev en n s has t wo degrees of freedom, the optimization as calculated with the equation 9 utilizes tree degrees of freedom for the normal. This is done to a void such normal expression as in cylindrical parameterizations, which adds singularities to the optimization pro cedure that can cause problems. It w as chosen to implement a 3 degree of freedom parameterizations, and then normalize the resulting up dated normal. 2.5 Surfel Reference F rame Change A new reference frame F kf 1 is selected as in the approach describ ed in [4]. First, the new reference frame p ose P kf 1 kf 0 is estimated, relative to the previous reference frame P kf 0 . If there are surfels previously estimated in the last reference frame F kf 0 , its surfels are passed to the new reference frame. The p osition and normal of each surfel are changed as p s kf 1 = P kf 1 kf 0 p s kf 0 n kf 1 = R kf 1 kf 0 n kf 0 (10) where R kf 1 kf 0 ∈ S O (3) is the rotation of P kf 1 kf 0 . The ray r s kf 1 can b e easily calculated as π ( p kf 1 ). 3 Implemen tation The prop osed system is implemented using the parallel computing capabilities of common GPU, by utilizing Op enGL core 3.3. This w ay go o d p erformance is ac hieved without the need to hav e a high p erformance system capable of CUD A or Op enCL. This depth estimation appro c h is integrated with the LSD-SLAM system [4], th us ha ving position estimation and map management. It w as found that this system is a go o d c hoice, b ecause of its state of the art p erformance while b eing op en-source and easy to expand up on. 4 System ev aluation The system was ev aluated in 3 datasets a v ailable in [1]. These datasets depict 3 differen t scenes. The first dataset was taken on fo od court, with tables and b enc hes in view. The street road present in the scene has a v ery smo oth texture, so estimating its depth can b e difficult. The second dataset was taken from inside a launch buffet, so the scene has man y non-diffuse surfaces, as the flo or and doors. The last scene w as tak en w alking around a mac hine building, so there are many op en spaces and intricate structures. In the following sections, results are sho wn for these three datasets. The color co des presen t in the figures are as follow. F or the normal estimations, blue Title Suppressed Due to Excessive Length 7 represen ts vectors whose directions are facing to the right edge of the frame, and red represents vectors wic h are p ointing to the right of the frame. Similarly , green represents vectors p oin ting up, and y ellow are v ectors pointing do wn. F or the depth estimation figures, black represen ts a low inv erse depth, and therefore high depth. Conv ersely , white represents high inv erse depths, and so depths close to the camera fo cal p oin t. F or the following ev aluations, the camera image has a 640 x 480 resolution, and the surfel size w as set to a radius of 10 pixels. 4.1 F oo dcourt Dataset Results from the F o odcourt dataset are sho wn in the figure 1. It can b e seen that the resulting depth is correctly recov ered, even in the low texture sections of the street. The first column of figure 1 depict a backw ard moving mo vemen t. This means that the pixels in the lo wer part of the image are pixels just entering the frame, and so they hav e received very few observ ations. This highlights the usefulness of the surfel initialization scheme explained in section 2.3. The third column of figure 1 depicts a forward mo ving mov ement, sho wing that both t yp es of mov emen ts allow correct normal and depth estimations. In the second column it can b e seen that the guarding fence, the fo o d truc k and the flo or ha ve correct depth and normal estimations. This part of the dataset is particularly c hallenging, b ecause the guarding fence w as seen a few frame ago from the opp osite side, so its normals had the inv erse direction. The same happ ens with the normals of the fo od truc k. Fig. 1: F oo dcourt Dataset results. First column: raw frame. Second column: es- timated normals. Third column: estimated depth. 8 T rab es et al. 4.2 Eccv Dataset This dataset is particularly challenging, b ecause of the sp ecularities presen t in almost all of the surfaces. The flo or, the ceiling and even some of the furniture presen t in the scene ha ve this c haracteristic. The first column of figure 2 shows that the flo or depth and normal was correctly estimated, even when there are sp ecularities and blurriness. In the second, third and fourth columns of figure 2 it can b e seen that the depth and normal of the ceiling was correctly recov ered. The mo vemen t in the second ro w was backw ard, so all of the pixels in the low er part of the frame are new and with v ery few observ ations. Again this shows the usefulness of the surfel initialization. Fig. 2: Eccv Dataset results. First column: raw frame. Second column: estimated normals. Third column: estimated depth. 4.3 Mac hine Dataset This dataset has the particularit y that it was taken outside, and the sky is a v ery prominent part of most of the frames. As it was a cloudy da y , the sky has texture, even when it is very smooth with a very low gradien t. As can b e seen in figure 3, the depth of the sky was correctly recov ered, ev en with the conditions describ ed b efore. The normals of the scene 4.4 Usefulness of Normal Estimation The usefullness of the join t depth and normal estimation was tested, by mo difing the Leven b erg-Marquat estimation algoritm describ ed in 2.4. In 9, ∂ id u ∂ n s w as set to [0 . 0 , 0 . 0 , 0 . 0], efectively just optimizing for id s , similarly to apro c hes lik e [3]. Title Suppressed Due to Excessive Length 9 Fig. 3: Machine Dataset results. First column: ra w frame. Second column: esti- mated normals. Third column: estimated depth. The resulting surface reconstruction of the foo dcourt dataset with and with- out normal estimation can b e seen in the figure 4. The resulting scene recon- struction has a quality not present in the reconstruction made without normal estimation. 4.5 Impact of Surfel Size Selection In this ev aluation, the surfel radius w as set to 12 pixels wide. Results of the scene reconstruction can b e seen in figure 5. The widening of the surfel causes a coarse reconstruction result, lo osing many details present on the scene. Nevertheless, the prop osed approac h is able to reconstruct the scene correctly , with the surfels on the flo or and b enches recov ered correctly . Without using normal estimation the resulting reconstruction has a very po or qualit y , at the p oint of almost being unrecognizable, as seen in figure 5. 5 Conclusion The approach describ ed here can estimate a monocular dense depth map as a set of surfels, directly from the raw image pixels. As far as the authors kno w, this is the first time this approach is utilized for mono cular depth estimation. This presents several adv an tages ov er metho ds more commonly found in the literature, that implemen t pixel depth estimation follo wed by a regularization sc hema. Firstly , there is no need for a computationally costly and physically unlik ely depth regularization. Also, the information from the normal estimation can b e used to initialize new neighboring surfels, thus being able to initialize 10 T rab es et al. Fig. 4: Detail of reconstruction, using a surfel radius of 5 pixels. First ro w: pro- p osed metho d. The b enc hes and tables presen t in the scene are easily recogniz- able, resulting from the correct surface normal estimation. Second row: without estimating surfels normals. This time the scene cannot b e easily recognized, and artifacts caused b y incorrect surfel normals are present the Gauss Newton optimization approach without the need to p erform further computations. The metho d w as tested in sev eral datasets, showing that the depth and surfels can b e recov ered correctly . The normal estimation allows for a more precise scene reconstruction, even when the surfel pixel radius is incremented considerably . The main mono cular depth estimation approach present in the literature rev olves around pixelwise depth estimation in conjunction with depth regular- ization metho ds. The results obtained in this paper suggest that more plausible depth priors can b e utilized for scene reconstruction. References References 1. T um lsd-slam datasets. https://vision.in.tum.de/research/vslam/lsdslam , accessed: 2017-07-22 2. Cadena, C., Carlone, L., Carrillo, H., Latif, Y., Scaramuzza, D., Neira, J., Reid, I., Leonard, J.J.: Past, present, and future of simultaneous lo calization and mapping: T ow ard the robust-p erception age. IEEE T ransactions on Robotics 32 (6), 1309– 1332 (Dec 2016). https://doi.org/10.1109/TR O.2016.2624754 3. Engel, J., Koltun, V., Cremers, D.: Direct sparse o dometry . IEEE T ransactions on P attern Analysis and Mac hine Intelligence (Mar 2018) 4. Engel, J., Sch¨ ops, T., Cremers, D.: LSD-SLAM: Large-scale direct mono cular SLAM. In: Europ ean Conference on Computer Vision (ECCV) (September 2014) 5. Go odfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press (2016), http: //www.deeplearningbook.org 6. Grisetti, G., Kummerle, R., Stachniss, C., Burgard, W.: A tutorial on graph- based slam. IEEE In telligent T ransportation Systems Magazine 2 (4), 31–43 (winter 2010). h ttps://doi.org/10.1109/MITS.2010.939925 Title Suppressed Due to Excessive Length 11 Fig. 5: Detail of reconstruction with a surfel radius of 12 pixels. The first row sho ws result with the presen t metho d, while the second row sho w result with- out estimating the surfels normal. With the prop osed method, even with such a coarse surfel reconstruction size, the b enches and tables present in the scene can b e still recognized, and the flo or is correctly recov ered. On the other hand, with- out estimating the surfels normal, the scene is almost completely unrecognizable, and there are heavy plane-depth related artifacts 7. Hosni, A., Rhemann, C., Bley er, M., Rother, C., Gelautz, M.: F ast cost- v olume filtering for visual correspondence and b ey ond. IEEE T ransactions on Pattern Analysis and Mac hine In telligence 35 (2), 504–511 (F eb 2013). h ttps://doi.org/10.1109/TP AMI.2012.156 8. Mur-Artal, R., Montiel, J.M.M., T ards, J.D.: Orb-slam: A versatile and accurate mono cular slam system. IEEE T ransactions on Rob otics 31 (5), 1147–1163 (Oct 2015). h ttps://doi.org/10.1109/TRO.2015.2463671 9. New combe, R.A., Lo vegro ve, S.J., Davison, A.J.: Dtam: Dense tracking and map- ping in real-time. In: 2011 In ternational Conference on Computer V ision. pp. 2320– 2327 (No v 2011). h ttps://doi.org/10.1109/ICCV.2011.6126513 10. Pizzoli, M., F orster, C., Scaramuzza, D.: REMODE: Probabilistic, mono cular dense reconstruction in real time. In: IEEE In ternational Conference on Rob otics and Automation (ICRA) (2014) 11. W ang, K., Gao, F., Shen, S.: Real-time scalable dense surfel mapping. In: 2019 In ternational Conference on Rob otics and Automation (ICRA). pp. 6919–6925 (Ma y 2019). https://doi.org/10.1109/ICRA.2019.8794101 12. Whelan, T., Salas-Moreno, R.F., Glo c ker, B., Da vison, A.J., Leuteneg- ger, S.: Elasticfusion: Real-time dense slam and light source estima- tion. The In ternational Journal of Rob otics Researc h 35 (14), 1697–1716 (2016). h ttps://doi.org/10.1177/0278364916669237, https://doi.org/10.1177/ 0278364916669237 13. Y an, Z., Y e, M., Ren, L.: Dense visual slam with probabilistic surfel map. IEEE T ransactions on Visualization and Computer Graphics 23 (11), 2389–2398 (No v 2017). h ttps://doi.org/10.1109/TVCG.2017.2734458 14. Zienkiewicz, J., Tsiotsios, A., Da vison, A., Leutenegger, S.: Mono cular, real- time surface reconstruction using dynamic lev el of detail. In: 2016 F ourth In ternational Conference on 3D Vision (3D V). pp. 37–46 (Oct 2016). h ttps://doi.org/10.1109/3DV.2016.82
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment