The G^ateaux-Hopfield Neural Network method
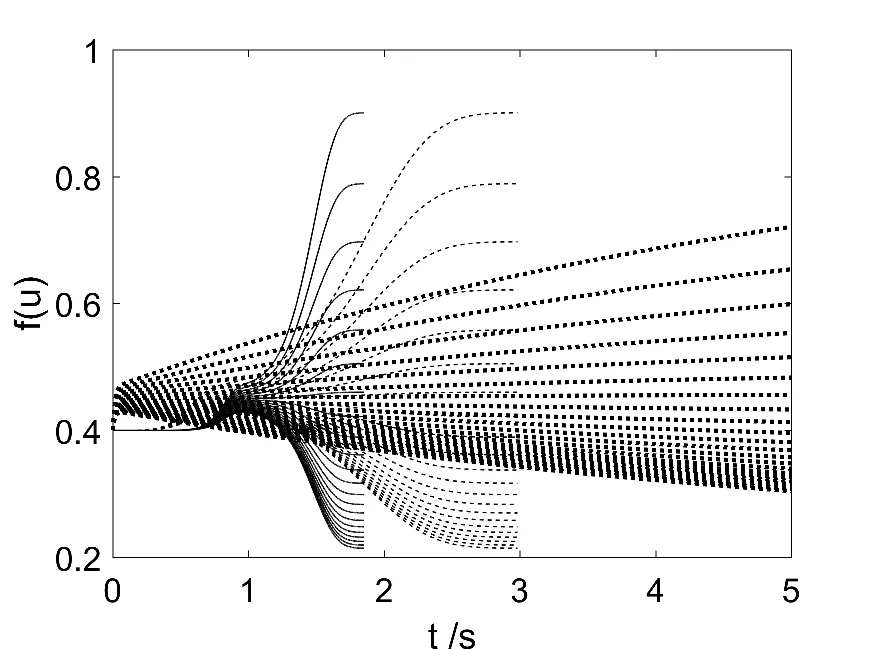
In the present work a new set of differential equations for the Hopfield Neural Network (HNN) method were established by means of the Linear Extended Gateaux Derivative (LEGD). This new approach will be referred to as G^ateaux-Hopfiel Neural Network (GHNN). A first order Fredholm integral problem was used to test this new method and it was found to converge 22 times faster to the exact solutions for {\alpha} > 1 if compared with the HNN integer order differential equations. Also a limit to the learning time is observed by analysing the results for different values of {\alpha}. The robustness and advantages of this new method will be pointed out.
💡 Research Summary
**
The paper introduces a novel formulation of Hopfield Neural Networks (HNN) by incorporating the Linear Extended Gateaux Derivative (LEGD), which the authors term the G‑ateaux‑Hopfield Neural Network (GHNN). The motivation stems from the well‑known difficulty of solving inverse problems, which often require regularization techniques such as Tikhonov or singular‑value decomposition. Traditional HNNs have been successfully applied to a variety of inverse problems, but their learning dynamics are governed by integer‑order differential equations that may be inefficient for ill‑posed cases.
Fractional calculus offers a way to modify the dynamics, yet many fractional derivatives (e.g., Caputo, Riemann‑Liouville) violate basic calculus properties such as the chain rule, making them awkward for neural‑network‑based learning. The authors focus on the Conformable Fractional Derivative (CFD) proposed by Khalil et al., which satisfies the usual calculus rules when the auxiliary function ψ(t,α)=t^{1‑α} with 0 < α ≤ 1. By generalizing ψ to allow any real α, the LEGD becomes a broader operator that retains linearity, product rule, and a simple chain rule (Equation 5).
Using this operator, the authors re‑derive the gradient of the HNN cost function Φ(t)=½‖Kf−g‖² with respect to the learning time. Imposing a decreasing error (dΦ_leg < 0) yields a set of coupled differential equations for the neuron potentials u₁(t) and u₂(t). In matrix notation the dynamics become
d u/dt = −(1/ψ)·(KᵀK f − Kᵀg).
When ψ = 1 the classic integer‑order HNN is recovered. For ψ = t^{1‑α} the learning rate becomes time‑dependent: if α < 1 the rate decays, leading to rapid early learning but eventual stagnation; if α > 1 the rate starts near zero and then grows, producing a short overall learning time once the dynamics kick in.
To test the method, the authors solve a first‑order Fredholm integral equation of the form
g(x) = ∫₀ᵇ K(x,y) f(y) dy,
with K(x,y) = (x + y)^{−1}, f(y) = y^{−1}, and g(x) = x^{−1} ln
Comments & Academic Discussion
Loading comments...
Leave a Comment